
GBDT_XGBoost_LGBM算法原理v1.11

需积分: 0 104 浏览量
更新于2022-08-03
1
收藏 2.18MB PDF 举报
《GBDT_XGBoost_LGBM算法原理v1.11》
在机器学习领域,Gradient Boosting Decision Trees (GBDT)、XGBoost和LightGBM是极具影响力的集成学习算法,它们基于梯度提升(Gradient Boosting)原理,通过构建一系列弱预测器并逐步优化来构建强大的模型。本文将深入探讨这些算法的核心概念和技术细节。
我们从基础的数学原理出发,泰勒公式是理解许多优化算法的关键。泰勒公式提供了一种将复杂函数近似为多项式的方法,这在损失函数的优化过程中起到重要作用。一阶泰勒展开用于近似函数在某一点的局部行为,而二阶泰勒展开则进一步考虑了函数的曲率,这对于梯度下降法和牛顿法的优化过程至关重要。
接下来,梯度下降法是机器学习中常见的优化算法,尤其在GBDT的实现中。它的基本思想是从一个初始点出发,沿着梯度的反方向,以一定的步长更新参数,以最小化损失函数。迭代公式可以表示为:θ_t = θ_{t-1} - α * ∇_θ L(θ),其中θ是模型参数,L是损失函数,α是学习率。梯度下降法简单易懂,但可能收敛速度较慢,且需要合适的学习率来确保稳定收敛。
然后,牛顿法是一种利用二阶导数信息进行优化的方法,它通过构造一个二次曲面来近似损失函数,并找到这个曲面的最小值作为参数的下一个估计值。牛顿法的迭代公式是:θ_t = θ_{t-1} - [Hessian(L)]^(-1) * ∇_θ L(θ),其中Hessian矩阵是损失函数的二阶导数,反映了函数的局部曲率。相比于梯度下降,牛顿法通常能更快地收敛,但计算Hessian矩阵可能会导致较高的计算成本。
从梯度下降法到Gradient Boosting,我们看到一个从参数空间到函数空间的转变。在GBDT中,我们不是优化单个参数,而是构建一系列决策树,每次迭代的目标是拟合上一轮残差,从而逐步减小整体误差。这种方法既利用了梯度下降的思想,又引入了模型的多样性,提高了预测性能。
XGBoost是GBDT的一种高效实现,它采用了二阶泰勒展开的近似,优化了原生GBDT的计算效率,同时引入正则化项控制模型复杂度,防止过拟合。XGBoost通过精心设计的数据结构和并行计算策略,实现了快速训练和预测,使其成为实际应用中的首选算法之一。
LightGBM进一步提升了效率,它采用梯度提升的叶子节点顺序优化(GOSS)和直方图算法,减少了内存占用和计算时间。这些优化使得LightGBM在大规模数据集上表现优异,同时保持了良好的预测精度。
GBDT、XGBoost和LightGBM是现代机器学习中不可或缺的工具,它们基于强大的数学原理和优化技术,结合了迭代学习和决策树的优势,为解决复杂问题提供了强大而高效的解决方案。在实际应用中,理解这些算法的工作原理和内在联系,对于模型的选择和调优具有极其重要的意义。



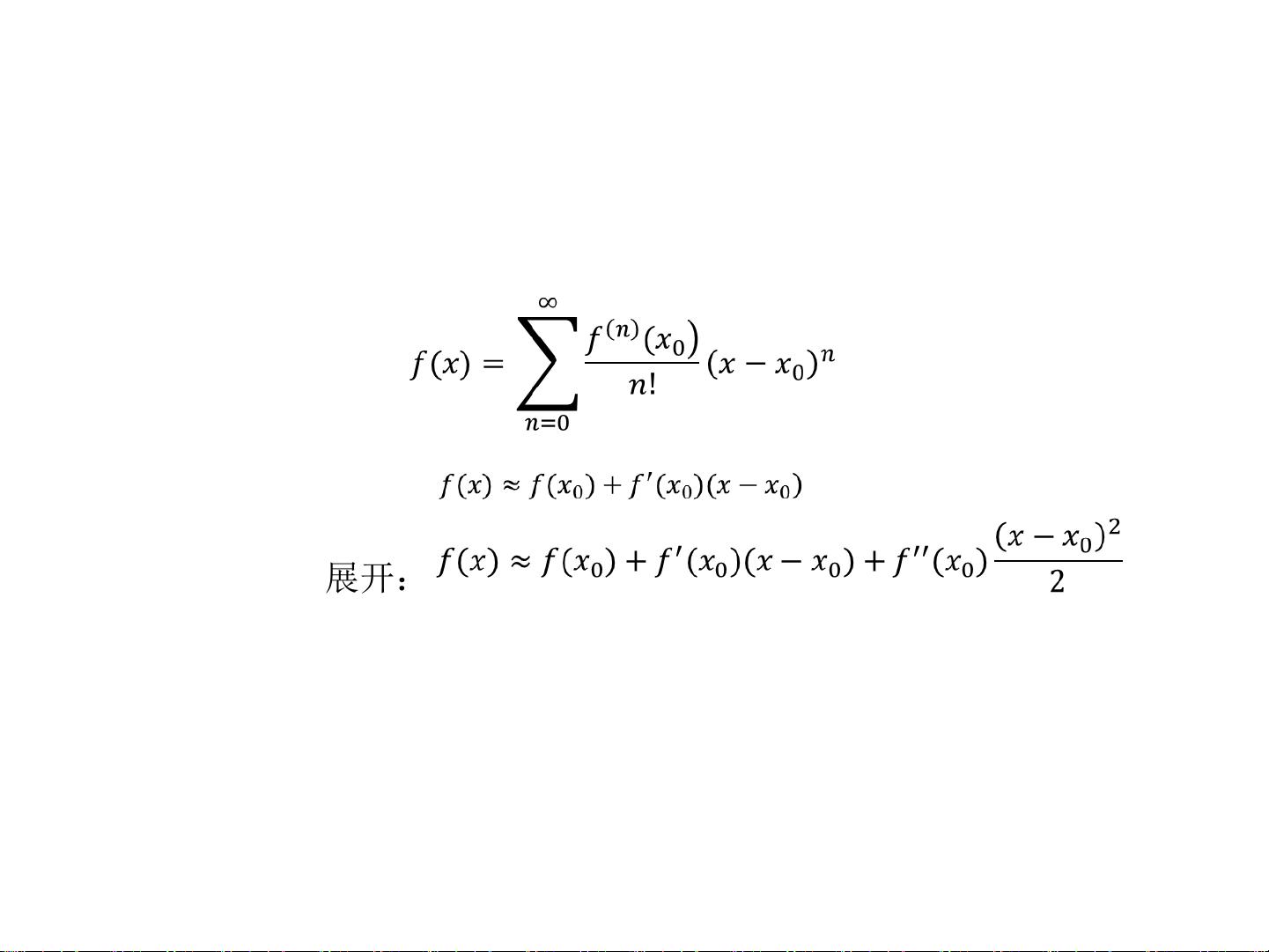

130 浏览量
2022-08-03 上传
2024-11-24 上传
196 浏览量
2022-08-03 上传
157 浏览量
2024-07-14 上传
2022-08-03 上传
125 浏览量
103 浏览量
152 浏览量
127 浏览量
185 浏览量
101 浏览量
162 浏览量
2021-10-02 上传
172 浏览量
143 浏览量
172 浏览量
168 浏览量
2023-07-27 上传
资源评论


Orca是只鲸
- 粉丝: 36
- 资源: 317









最新资源
- 基于LabVIEW的CRC校验程序
- Python毕业设计-基于Python的天气预测和天气可视化项目(源码+数据库)
- Comsol光子晶体光栅非对称传输
- Mac最新版本的JasperSoft
- 在CodeBlocks搭建SDL2工程构建TFT彩屏模拟器虚拟TFT彩屏幕显示
- Python实现简单的天气数据爬取和可视化(课程设计)
- COMSOL 热流耦合拓扑优化 无量纲-双目标
- comsol光子晶体仿真,拓扑荷,偏振态 三维能带,三维Q,Q因子计算 远场偏振计算
- ECMAScript 6 入门 作者:阮一峰, 的学习源码,供大家学习使用
- 海草云智能修片,一键修图,修人像,修风景,媲美美图、PS,方便快捷
- 含齿根裂纹-轴承内圈,外圈,滚动体的超高自由度斜齿–轴承复合故障特性分析!才用残差法突出故障时域响应,采用包络谱对故障特征频率进行分析,模型难度巨大
- VB 开发access职工工资管理信息系统(系统+开题+论文+任务书
- 电解质锂离子电化学传输模型 基于Nernst-Planck方程构建电解质中锂离子传输机理模型,传递机理包括对流,迁移和扩散作用,可模拟电解质的锂离子浓度,通量和电场结果 可添加正负电极,界面电极动力
- 销售记录数据,包括订单ID、产品种类、销售额、利润、客户区域等
- Comsol三维锂离子叠片电池电化学-热全耦合 采用COMSOL锂离子电池模块耦合传热模块,仿真模拟锂离子电池在充放电过程中产生的欧姆热,极化热,反应热,以及所引起的电芯温度变化
- Comsol石墨烯二维材料 包含太赫兹德鲁得和近红外Kubo两种模型 共7个案例,包含参考文献
