chap-网络优化与正则化1
需积分: 0 114 浏览量
2022-08-03
22:04:26
上传
评论
收藏 3.34MB PDF 举报


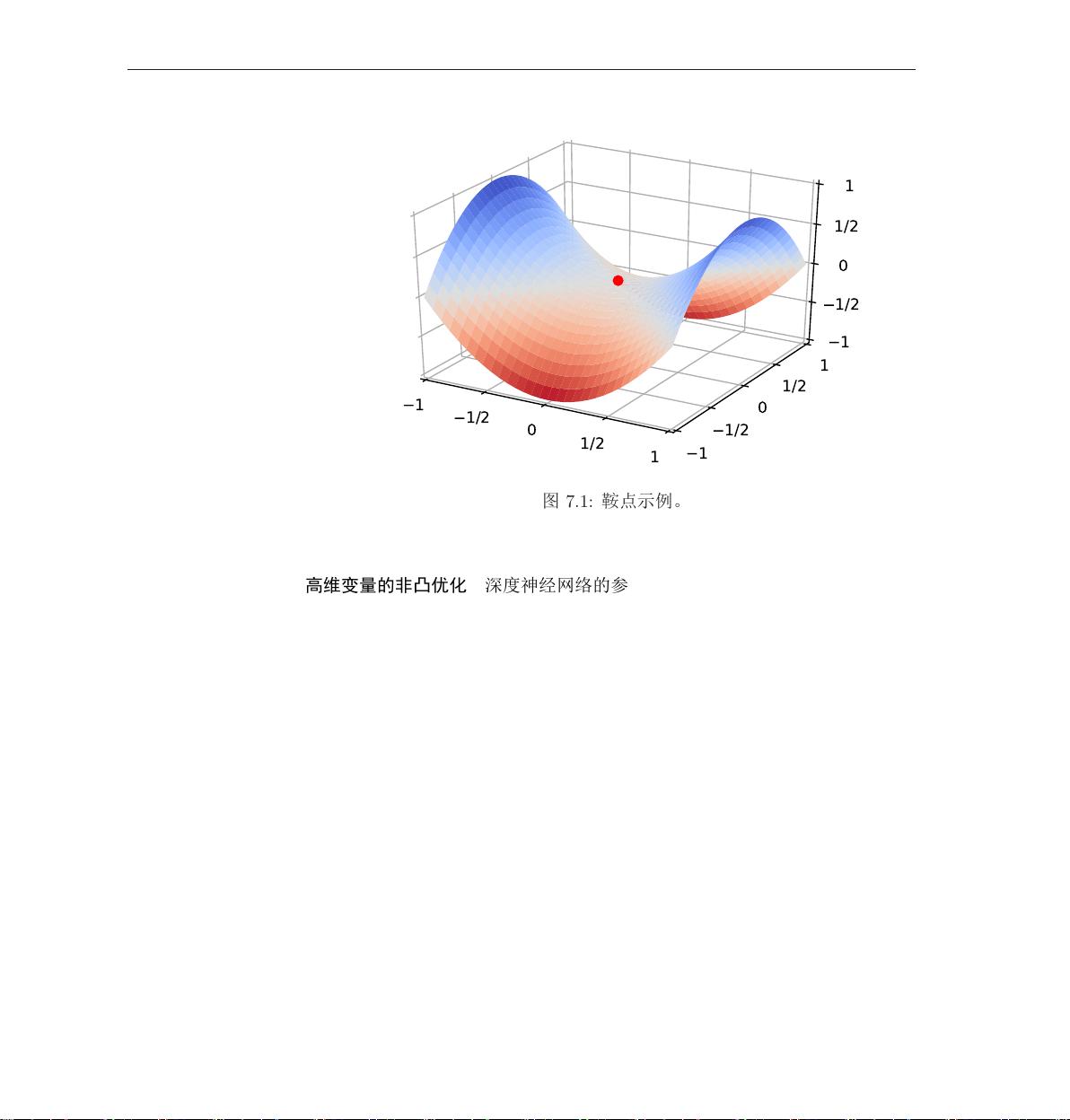
第七章 网络优化与正则化
虽然神经网络具有非常强的表达能力,但是当应用神经网络模型到机器学
习时依然存在一些难点。主要分为两大类:(1)优化问题:神经网络模型是一
个非凸函数,再加上在深度网络中的梯度消失问题,很难进行优化;另外,深
度神经网络模型一般参数比较多,训练数据也比较大,会导致训练的效率比较
低。(2)泛化问题:因为神经网络的拟合能力强,反而容易在训练集上产生过
拟合。因此,在训练深度神经网络时,同时也需要掌握一定的技巧。目前,人
们在大量的实践中总结了一些经验技巧,从优化和正则化两个方面来提高学习
效率并得到一个好的网络模型。
7.1 网络优化
深度神经网络是一个高度非线性的模型,其风险函数也是一个非凸问题。
在非凸问题中,一个会存在一些局部最优点。
有效地学习深度神经网络的参数是一个具有挑战性的问题,其主要原因有
以下几个方面。
网络结构多样性 神经网络的种类非常多,比如卷积网络、循环网络等,其结
构也非常不同。有些比较深,有些比较宽。不同参数在网络中的作用也有很大
的差异,比如连接权重和偏置的不同,以及循环网络中循环连接上的权重和其
它权重的不同。
网络结构的多样性导致了很难找到一种通用的优化方法。不同的优化方法
在不同网络结构上的差异也都比较大。
此外,网络的超参数一般也比较多,这也给优化带来很大的挑战。


剩余19页未读,继续阅读

胡说先森
- 粉丝: 53
- 资源: 280









最新资源
- threadmanager.cpp
- 腾讯云小程序 - 一站式开发与部署平台
- 基于JSP+Java+Servlet采用MVC模式开发的购物网站+源码(毕业设计&课程设计&项目开发)
- fastgestures安装包,模拟mac的触控板收拾,两指代表右击, 三指拖拽
- 基于组态王的升降式横移立体车库控制系统+源码(毕业设计&课程设计&项目开发)
- 基于python+Django和协同过滤算法的电影推荐系统+源码(毕业设计&课程设计&项目开发)
- 环境配置 vscode+jupyter
- 项目全部代码,还包含使用到的图片
- 项目全部代码,还包含使用到的图片
- 基于java+MapReduce实现基于物品协同过滤算法,即电影推荐系统+源码+开发文档+算法解析(毕业设计&课程设计&项目开发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0