从FM推演各深度CTR预估模型(附代码)1
需积分: 0 157 浏览量
2022-08-04
00:27:34
上传
评论
收藏 3.65MB PDF 举报


从
FM
推
演
各
深
度
CTR
预
估
模
型
(
附
代
码
)
多年以后,当资深算法专家们看着无缝对接用户需求的广告收入节节攀升时,他们可能会想起自己之前痛苦推导FM
与深度学习公式的某个夜晚……
——题记
1.
引
言
点击率(click-through rate, CTR)是互联网公司进行流量分配的核心依据之一。比如互联网广告平台,为了精细化权衡
和保障用户、广告、平台三方的利益,准确的CTR预估是不可或缺的。CTR预估技术从传统的逻辑回归,到近两年大
火的深度学习,新的算法层出不穷:DeepFM, NFM, DIN, AFM, DCN…… 然而,相关的综述文章不少,但碎片罗列的
居多,模型之间内在的联系和演化思路如何揭示?怎样才能迅速get到新模型的创新点和适用场景,快速提高新论文
速度,节约理解、复现模型的成本?这些都是亟待解决的问题。
我们认为,从FM及其与神经网络的结合出发,能够迅速贯穿很多深度学习CTR预估网络的思路,从而更好地理解和
应用模型。
2.
本
文
的
思
路
与
方
法
我们试图从原理上进行推导、理解各个深度CTR预估模型之间的相互关系,知其然也知其所以然。(以下的分析与拆
解角度,是一种我们尝试的理解视角,并不是唯一的理解方式)
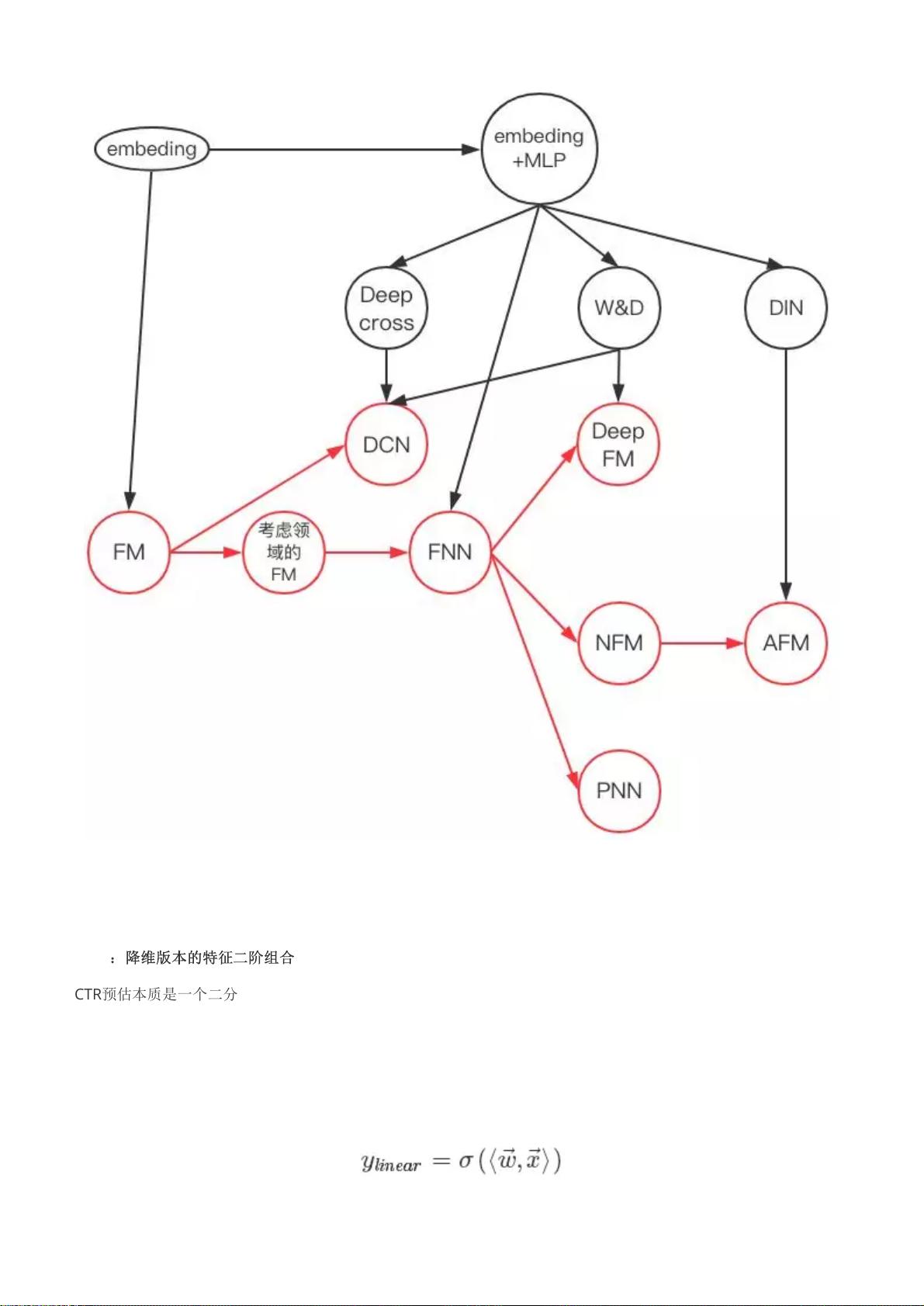
推演的核心思路:“通过设计网络结构进行组合特征的挖掘。”
具体来说有两条:其一是从FM开始推演其在深度学习上的各种推广(对应下图的红线),另一条是从
embedding+MLP自身的演进特点结合CTR预估本身的业务场景进行推演(对应下图黑线部分)。


剩余23页未读,继续阅读

八位数花园
- 粉丝: 42
- 资源: 282









最新资源
- 51单片机学习(1)-软件keil下载
- 历届(第1-21届)希望杯数学竞赛初一试题及答案(最新整理).doc全国数学邀请赛(264页资料)
- 水滴.psd
- TokenPocket_V2.1.2_release.apk
- Apache-druid-kafka-rce.yaml
- 基于C#的ASP.NET数据库原理及应用技术课程指导平台的开发
- 基于ROS的智能车轨迹跟踪算法的仿真与设计源码运用PID跟踪算法.zip.zip
- Bug Bounty Tip - i春秋Self-XSS变废为宝的奇思妙想
- 1991-2015年全国初中化学竞赛复赛试题汇编(212页)(24年竞赛复赛真题).docx天原杯
- Apache Flink 未授权访问+远程代码执行.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0