Flink安装配置(2)1
需积分: 0 137 浏览量
2022-08-08
23:10:01
上传
评论
收藏 80KB DOCX 举报

Flink(二)CentOS7.5 搭建 Flink1.6.1 分布式集群
一. Flink 的下载
安装包下载地址:http://flink.apache.org/downloads.html ,选择对应 Hadoop 的 Flink 版本
下载
[admin@bigdata11 software]$ wget
http://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.6.1/flink-
1.6.1-bin-hadoop27-scala_2.11.tgz
[admin@bigdata11 software]$ ll
-rw-rw-r-- 1 admin admin 301867081 Sep 15 15:47 flink-1.6.1-bin-
hadoop27-scala_2.11.tgz
Flink 有三种部署模式,分别是 Local、Standalone Cluster 和 Yarn Cluster。
二. Local 模式
对于 Local 模式来说,JobManager 和 TaskManager 会公用一个 JVM 来完成 Workload。如
果要验证一个简单的应用,Local 模式是最方便的。实际应用中大多使用 Standalone 或者
Yarn Cluster,而 local 模式只是将安装包解压启动(./bin/start-local.sh)即可,在这里不在演
示。
三. Standalone 模式
快速入门教程地址:https://ci.apache.org/projects/flink/flink-docs-release-
1.6/quickstart/setup_quickstart.html
1. 软件要求
� Java 1.8.x 或更高版本,
� ssh(必须运行 sshd 才能使用管理远程组件的 Flink 脚本)
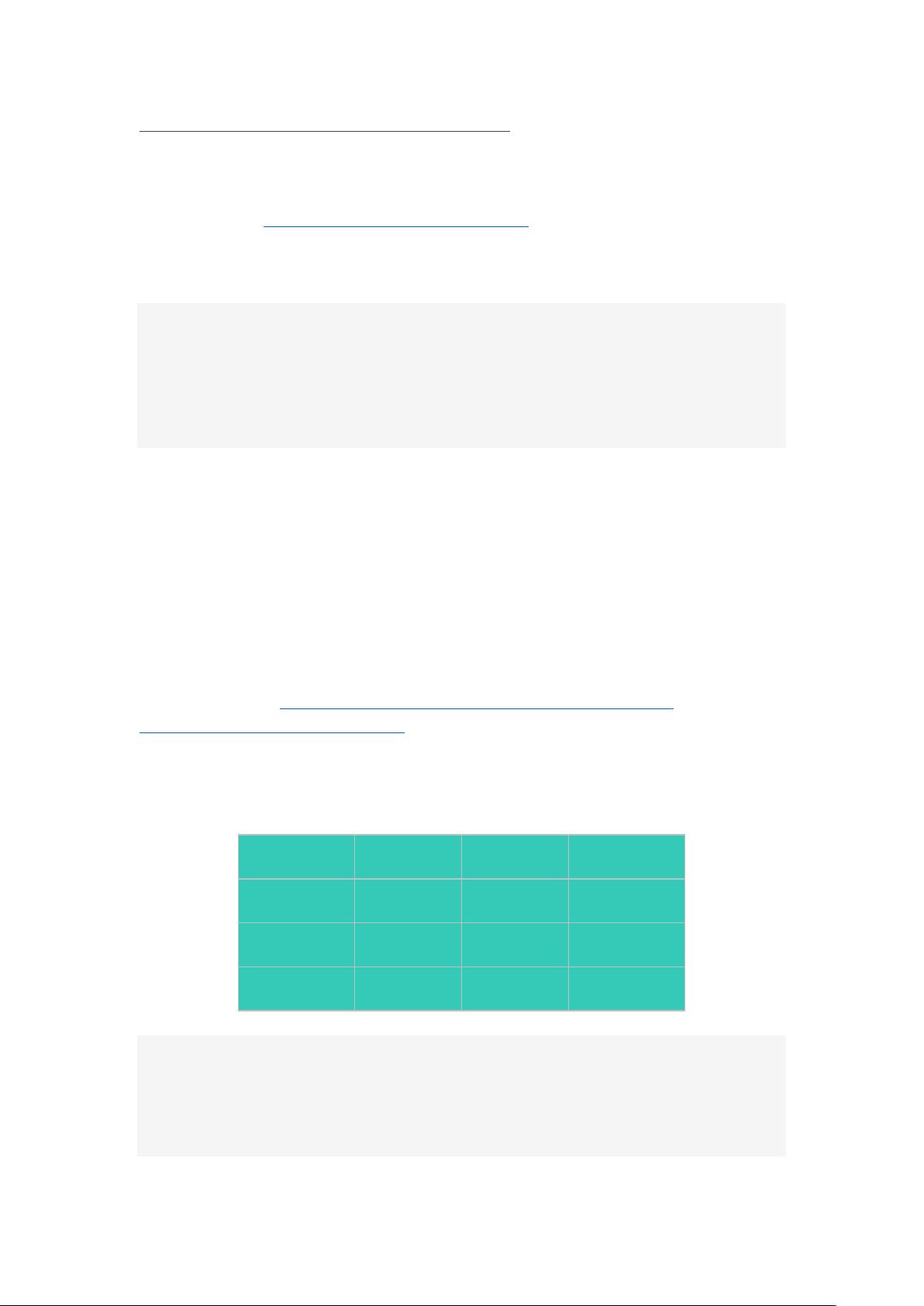
集群部署规划
节点名称
master
worker
zookeeper
bigdata11
master
zookeeper
bigdata12
master
worker
zookeeper
bigdata13
worker
zookeeper
2. 解压
[admin@bigdata11 software]$ tar zxvf flink-1.6.1-bin-hadoop27-
scala_2.11.tgz -C /opt/module/
[admin@bigdata11 software]$ cd /opt/module/
[admin@bigdata11 module]$ ll
drwxr-xr-x 8 admin admin 125 Sep 15 04:47 flink-1.6.1
3. 修改配置文件

剩余10页未读,继续阅读
资源评论













