caffe学习笔记1CIFAR-10在caffe上进行训练与学习-薛开宇1

需积分: 0 157 浏览量
更新于2022-08-03
收藏 144KB PDF 举报
《CIFAR-10在Caffe上的训练与学习》
CIFAR-10是一个常用的计算机视觉数据集,包含60,000张32x32彩色图像,分为10个类别,其中50,000张用于训练,10,000张用于测试。在Caffe这一深度学习框架中对CIFAR-10进行训练与学习,可以帮助我们理解如何在实际中应用Caffe进行图像识别任务。
1. 数据准备
在开始训练前,首先需要获取并处理CIFAR-10数据集。在Caffe的安装目录下,运行`$CAFFE_ROOT/data/cifar10/get_cifar10.sh`脚本,这将下载数据集。接着,执行`$CAFFE_ROOT/examples/cifar10/create_cifar10.sh`,它会创建LevelDB格式的数据库和图像均值文件。这些文件位于`./cifar10-leveldb`和`./mean.binaryproto`,是训练模型所必需的。
2. 构建模型
Caffe中的模型定义通常以prototxt文件形式存在。在这个例子中,CIFAR-10的模型由一系列层构成,包括卷积层、池化层、非线性激活层以及顶部的局部对比归一化线性分类器。模型的具体配置可以在`cifar10_quick_train.prototxt`中找到,根据需求可以进行修改。prototxt文件是用来定义网络结构和参数的文本文件。
3. 训练与测试
训练模型的步骤相当简单。我们需要编写训练参数设置的`solver.prototxt`文件(如`cifar10_quick_solver.prototxt`)和定义模型的`train.prototxt`文件(如`cifar10_quick_train.prototxt`及`cifar10_quick_test.prototxt`)。通过运行`train_quick.sh`脚本或者直接在终端输入相应的命令启动训练过程。
训练过程中,Caffe会输出关于模型构建和训练过程的信息。例如,`Creating Layer conv1`表示正在创建卷积层;`Top shape: 100 32 32 32 (3276800)`展示了顶层的形状,这里是一个包含100个32x32特征图的批次;`loss`值表示训练损失,随着训练的进行,期望其逐渐减小。每隔一定迭代次数(如100次),Caffe会报告学习率(lr)和当前的loss。每500次迭代,模型会进行一次测试,并输出测试得分。
4. 监控与优化
训练期间,我们可以观察loss和score的变化来评估模型的性能。如果loss下降较慢或测试得分不理想,可能需要调整学习率、优化算法、增加层数或改变超参数。Caffe提供了一些内置的可视化工具,如TensorBoard,帮助我们更好地理解模型的训练过程并进行调优。
总结,Caffe对CIFAR-10的训练流程包括数据预处理、模型定义、训练以及性能评估。通过这个过程,不仅可以掌握Caffe的基本操作,也能对深度学习模型的训练有更深入的理解。
读书笔记 1 CIFAR-10 在 caffe 上进行训练与学习
2014.7.21 薛开宇
本次学习笔记作用,知道如何在 caffe 上训练与学习,如何看结果。
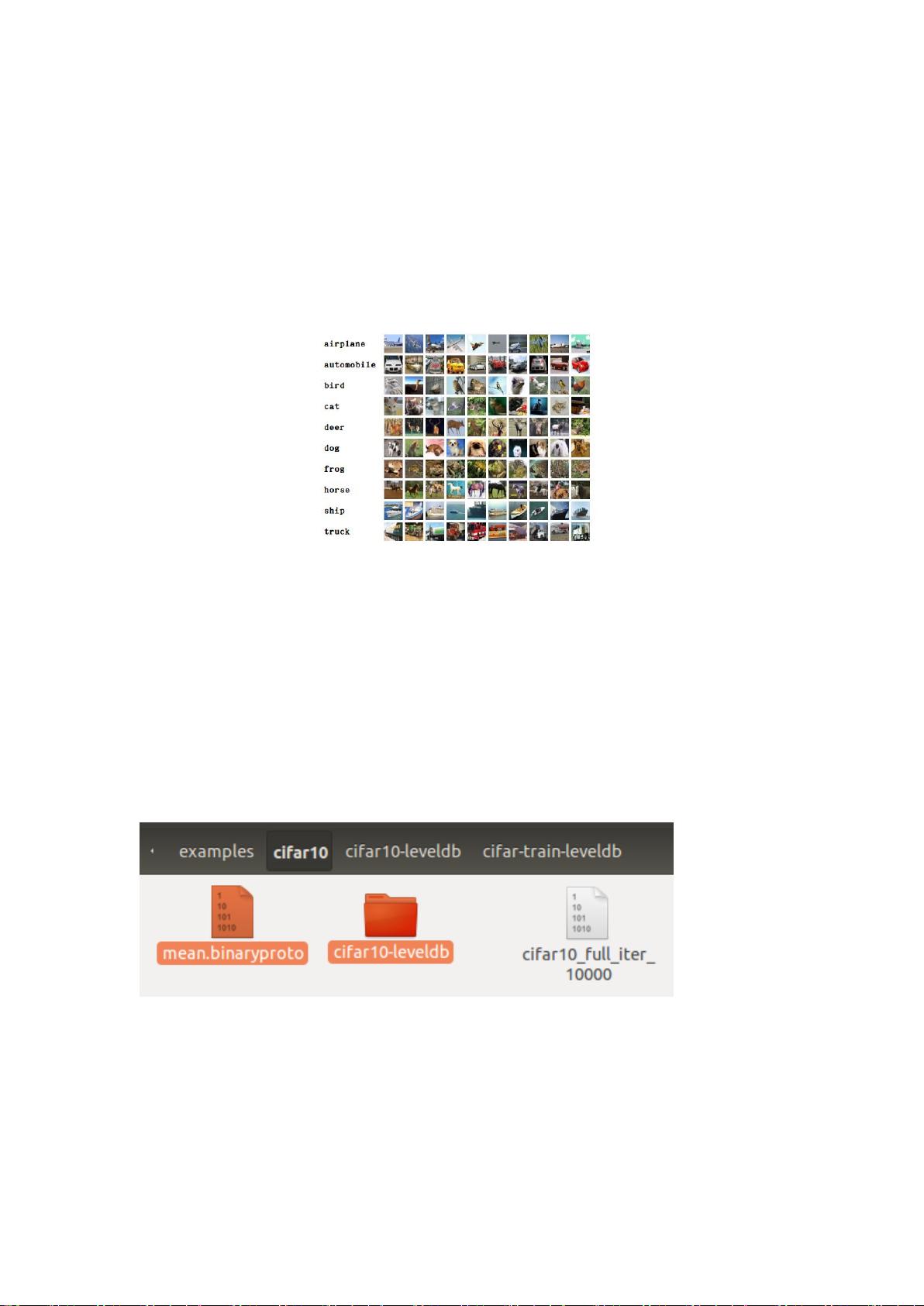
1.1 使用数据库:CIFAR-10
60000 张 32X32 彩色图像 10 类
50000 张训练
10000 张测试
1.2 准备
在终端运行以下指令:
cd $CAFFE_ROOT/data/cifar10
./get_cifar10.sh
cd $CAFFE_ROOT/examples/cifar10
./create_cifar10.sh
其中 CAFFE_ROOT 是 caffe-master 在你机子的地址
运行之后,将会在 examples 中出现数据库文件./cifar10-leveldb 和数据库图像均值二进制文
件./mean.binaryproto
下载后可阅读完整内容,剩余2页未读,立即下载
2018-07-25 上传
2022-08-08 上传
2022-08-03 上传
172 浏览量
117 浏览量
157 浏览量
178 浏览量
155 浏览量
170 浏览量
129 浏览量
资源评论


ai
- 粉丝: 874
- 资源: 314









最新资源
- 基于dubbo-go、gin的集成项目资料齐全+详细文档.zip
- 基于dubbo2.5.3开发的监控平台,兼容了dubbo-admin的特性,有redis、mysql两个版本资料齐全+详细文档.zip
- 基于Dubbo的agent探针数据采集模块资料齐全+详细文档.zip
- 基于Dubbo-RPC的分布式配置服务中心资料齐全+详细文档.zip
- 基于dubbo的分布式工程开发规范实例工程,分布式跟踪、ID生成、分布式事务、分布式治理、分表分库、分布式锁、选举、分布式配置、API文档生成器...资料齐全+详细文档.zip
- 基于Dubbo的分布式任务调度系统资料齐全+详细文档.zip
- 基于dubbo的分布式商城资料齐全+详细文档.zip
- 基于dubbo的分布式数据库事务资料齐全+详细文档.zip
- @Transactional事务,太坑了!前言 对于从事java开发工作的同学来说,Spring的事务肯定再熟悉不过了
- 基于dubbo的微服务架构资料齐全+详细文档.zip
- 基于dubbo第三方支付系统资料齐全+详细文档.zip
- 基于Dubbo框架的raft算法库资料齐全+详细文档.zip
- 基于dubbo框架+leveldb存储构建高可用的事件通讯组件资料齐全+详细文档.zip
- 基于Dubbo分布式简易支付系统资料齐全+详细文档.zip
- 基于Dubbo埋点的分布式调用跟踪系统资料齐全+详细文档.zip
- 基于Dubbo微服务项目快速搭建脚手架,提供基础功能,方便企业快速搭建项目。资料齐全+详细文档.zip
