分布式缓存的通用方法—《可伸缩服务架构》1

需积分: 0 10 浏览量
更新于2022-08-03
收藏 1.14MB PDF 举报
分布式缓存是现代大型互联网应用解决性能瓶颈的关键技术之一,其主要目的是提高数据访问的速度,降低对后端数据库的压力。本文将围绕《可伸缩服务架构:框架与中间件》一书中关于分布式缓存的通用方法进行深入探讨。
分布式缓存的编程方法主要有三种:编程法、Spring注入法和注解法。编程法是最基础的方式,通过直接调用缓存服务的API来存取数据,虽然直观但易导致代码冗余。Spring注入法则利用Spring框架的特性,通过Bean注入方式简化缓存操作。注解法更进一步,通过在方法上添加注解,使得缓存操作对开发者更加透明,提高了代码的简洁性和可维护性。
在应用层访问缓存的模式上,主要分为双读双写、异步更新和串联模式。双读双写是最常见的策略,即读操作先尝试从缓存获取,未命中再从数据库中获取并回写缓存;写操作则先更新数据库,然后更新缓存。这种方法简单直接,但需要在应用层处理读写顺序。异步更新模式则将缓存更新独立出来,应用仅与缓存交互,更新服务负责异步同步数据库与缓存,这种方式性能最优,但需要额外维护更新服务的稳定性和一致性。串联模式中,应用直接通过缓存代理层与数据库通信,增加了复杂度,但在特定场景下能提供额外功能,如缓存加速。
分布式缓存分片是处理海量数据的重要手段,主要分为客户端分片、代理分片和集群分片。客户端分片将分片逻辑放在应用层,需要保证所有节点的分片规则一致;代理分片通过代理服务器进行分片,降低了应用的复杂性,但引入了额外的网络开销;集群分片则是通过缓存集群自动处理分片,通常与一致性哈希算法结合使用,确保数据迁移时的稳定性。
在实际应用中,选择合适的缓存编程方法和访问模式,以及合理的分片策略,对于优化系统性能和保证数据一致性至关重要。同时,还需要关注缓存的过期策略、并发控制以及数据同步等问题,以确保系统的高可用性和可靠性。在设计分布式缓存方案时,应根据业务需求和系统规模,综合考虑各种因素,做出最佳选择。

分布式缓存的通⽤⽅法—《可伸缩服
务架构》
本⽂节选⾃《可伸缩服务架构:框架与中间件》 第四章《缓存的本质和缓
存使⽤的优秀实践》。PS:本⽂最后有《可伸缩服务架构:框架与中间件》
共5本抽奖活动,试试你的运⽓吧~
4 分布式缓存的通⽤⽅法
笔者所在的多家互联⽹公司⼤量使⽤了缓存,对分布式缓存的应⽤可谓遍地
开花,笔者曾供职的⼀家社交媒体⽹站,号称是世界上使⽤缓存最多的公
司。⽏庸置疑,缓存帮助我们解决了很多性能问题,甚⾄帮助我们解决了⼀
些并发问题。
4.4.1 缓存编程的具体⽅法
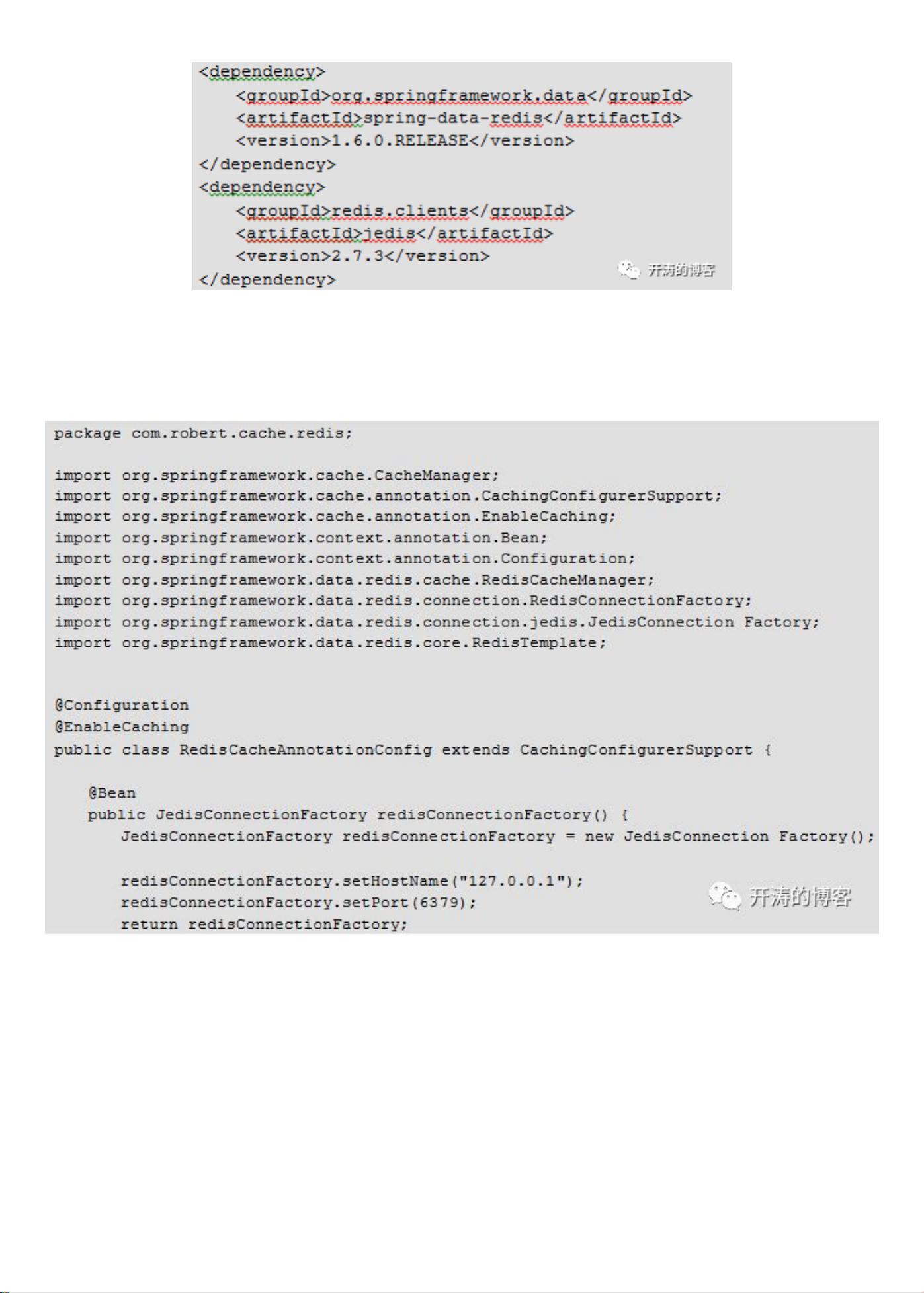
各种分布式缓存如Redis,都提供了不同语⾔的客户端API,我们可以使⽤这
些API直接访问缓存,也可以通过注解等⽅法使⽤缓存。
1.编程法
编程法指通过编程的⽅式直接访问缓存,伪代码如下:
这种⽅法实现起来简单,但是每次使⽤时都得敲⼊类似上⾯这样的⼀段代
码,很烦琐,可以将这部分内容抽象成⼀个框架,请参考下⾯的⼩节。


剩余21页未读,继续阅读
162 浏览量
118 浏览量
2010-11-25 上传
153 浏览量
2018-04-18 上传
177 浏览量
112 浏览量
2012-08-13 上传
2021-11-08 上传
2021-09-04 上传
2023-05-11 上传
144 浏览量
121 浏览量
2019-07-16 上传
200 浏览量
2012-06-07 上传
185 浏览量
136 浏览量
191 浏览量
2021-07-18 上传
125 浏览量
资源评论











