Tesnor Ridge Regression 与多信息源因子 Ver 1.21
需积分: 0 189 浏览量
2022-08-03
13:45:20
上传
评论
收藏 2.01MB PDF 举报

Tesnor Ridge Regression
与
多
信
息
源
因
子
张
量
表
征
猫狗
大
战
联系信箱:[email protected]
首
先
给
自
己
打
个
广
告
,
应
届
硕
士
,
求
量
化
相
关
工
作
、
实
习
。
本文先简单归纳《A Tensor-Based Information Framework for Predicting the Stock Market 》中介绍的一种探
索多维数组(张量)表征多因子并计算不同因子抽象关系并降低维度的方法,然后归纳《Tensor Learning for
Regression 》中介绍的Tesnor Ridge Regression算法,通过CP分解张量降低需要估计回归系数(因子收益率)的
数量。
股票趋势受各种高度相关信息的强烈影响,这通常涵盖经济学、政治学和心理学等多方面研究。传统的有效市场假
说(EMH)指出,股价总是由“理性”的投资者驱动,股价等于公司预期未来现金流的理性现值。与市场有关的新信
息可能会改变投资者的期望,并导致股价波动,这种对信息反应的分歧导致股价的实际价格与内在价值之间的差
异。竞争市场参与者导致股价波动周围的股价内在价值,即新信息对股价产生复杂的影响。然而,股价并不严格遵
循随机游走,行为金融研究将股票趋势的非随机性归结为投资者由于认知和情绪偏见的对不利消息的过度反应。虽
然传统金融和行为金融均认为新的信息对股票趋势产生复杂影响。
A股市场刨除内幕等操作方法为,一般分为基本面分析和技术分析两类。基本面分析通常通过构建经济、商业和市
场行业等多信息源的数据与股票未来走势之间的关系来预测股票趋势,即国家整体经济,行业条件,公司的财务状
况和管理层能力等因素,可以深度拆解股价未来走势。技术分析通过历史股票趋势预测股价未来走势,技术分析流
派认为股价市场是周期性或者类周期性的,并且具有特定的模式,这些模式随着时间的推移而重复出现。
受到移动互联网的影响,股票信息迅速更新并以前所未有的速度传播,并且通常在正式统计报告之前向投资者对投
资者产生影响。用户参与社交媒体(包括评论,评分和投票)的变化可以更快速地互动交换信息。这种情况可能导
致群体投资行为,因为投资者的决策倾向于受同行的情绪影响。目前常见的做法是使用NLP量化新闻和社交网络的
新信息提供定性信息,如舆情指数。影响股票趋势的信息是多方面的且互相影响的,反映到因子数据方面就是存在
多重共线性。
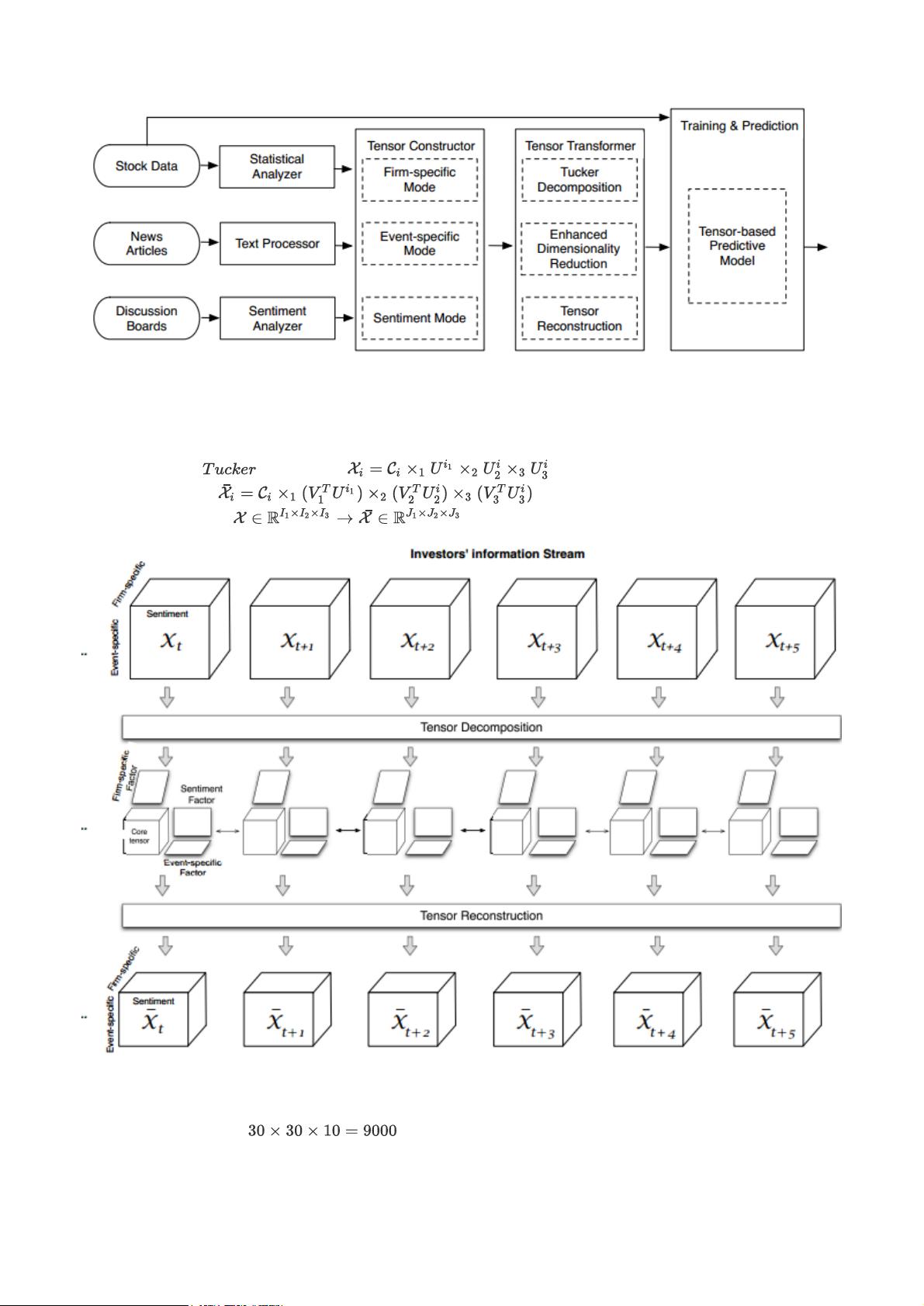
传统的线性回归将多个信息源(模式)的特征(无量纲因子)连接到一个复合特征的向量中处理。由于维度灾难和
多重共线性,这种做法限制了多因子模型囊括因子数量。此外使用马赛克拼接(mosaic approach)通常包含各种信
息源的混合和交互,但级联向量假设每个信息膜是是相互独立的。如下图这里,矩阵用于建模简化的投资信息源,
其中每行代表一种信息模式,如企业信息、事件信息或情绪信息。根据马赛克拼接信息结构,特征模式可以存在于
不同信息源(行)或不同模式之间。


剩余15页未读,继续阅读













评论0