数据聚合与分组操作1
需积分: 0 42 浏览量
2022-08-03
13:14:01
上传
评论
收藏 107KB PDF 举报

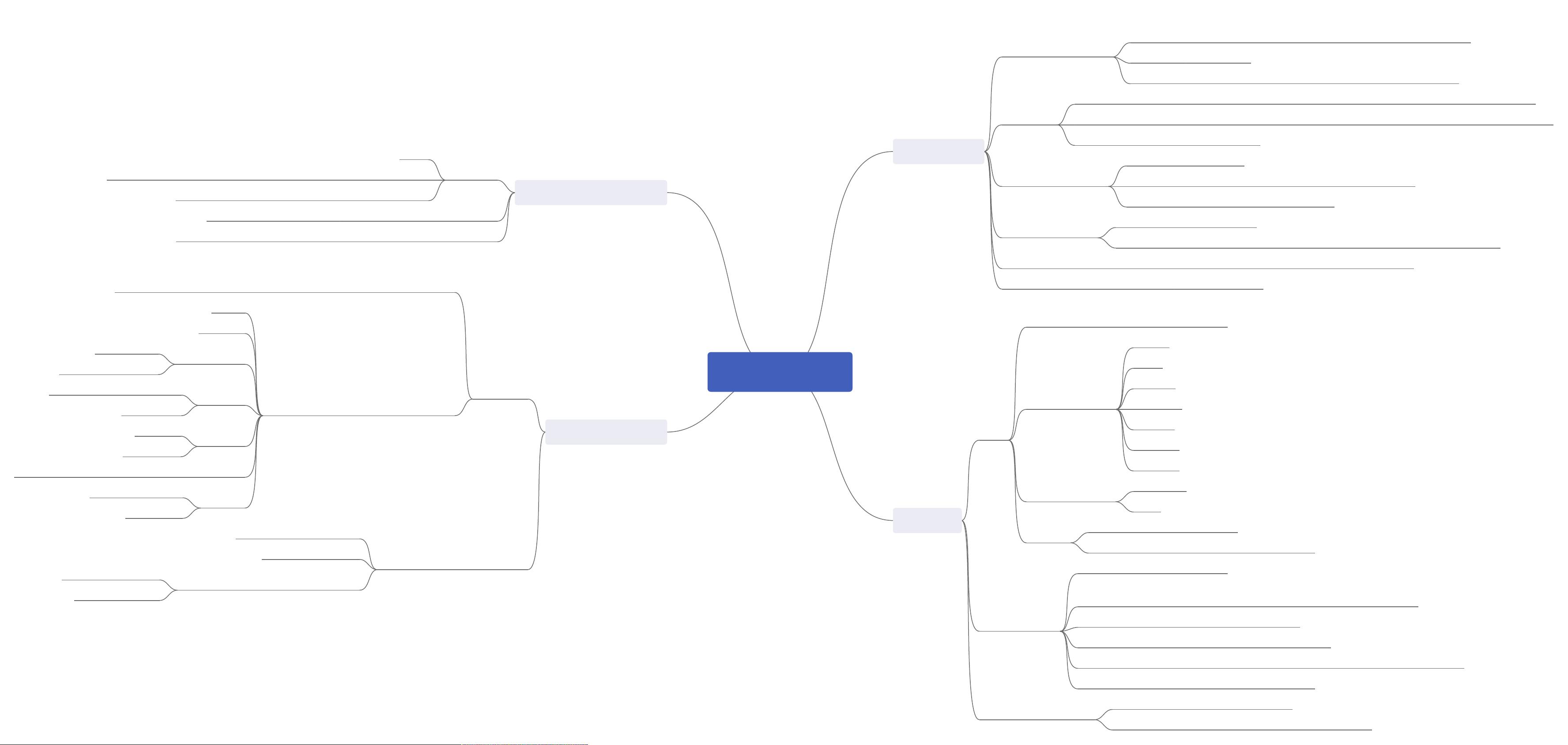
数据聚合与分组操作
GroupBy机制
数据聚合
应用:通用拆分-应用-联合
数据透视表与交叉表
基础
遍历各分组
选择一列或所有列的子集
使用字典和Series分组
使用函数分组
根据索引层级分组
groupby方法
数据根据分组键进行了聚合,并产生了一个新的Series,这个Series使用key1列的唯一
值作为索引
返回值
GroupBy对象
如果传入值是多个数组作为列表传入,结果Series会有一个包含唯一键对的多层索引
GroupBy对象支持迭代,会生成一个包含组名和数据块的2为元组序列
for name, group in df.groupby('key1'):
在多个分组键的情况下,元组中的第一个元素是键值的元组
for (key1, key2), group in df,groupby(['key1', 'key2']):
默认情况下,groupby在axis=0的轴向上分组
df.groupby('key1')['data1']
如果传递的是列表或数组,则此索引操作返回的对象是分组的DataFrame
如果只有单个列名作为标量传递,则为分组的Series
分组信息可能会以非数组形式存在
根据字典构造传给groupby的数组,也可以直接传字典
people.groupby(mapping, axis=1)
作为分组键传递的函数将会按照每个索引值调用一次,同时返回值会被用作分组名称
level关键字
层级数值或层级名称
聚合是指所有根据数据产生标量值的数据转换过程
优化的groupby方法
count
sum
median
min/max
std/var
first/last
使用自己的聚合函数
aggregate
agg
describe
quantile
Series或DataFrame列的样本分位数
不是显式地为GroupBy对象实现的,但是是Series的方法
基础
逐列及多函数应用
返回不含行索引的聚合数据
根据各列同时使用多个函数进行聚合
向agg/aggregate传递函数或者是函数名的列表,可以得到列名是这些函数名的
DataFrame
自定义DataFrame的列名
传递(name, function)
可以指定应用到所有列上的函数列表或每一列要应用的不同函数
将不同的函数应用到一个或多个列上
将有列名与函数对应关系的字典传递给agg/aggregate
当多个函数应用到至少一个列上时,DataFrame具有分层列
as_index=False
禁用分组键作为索引
reset_index
在结果上调用这个方法也可以获得同样的效果
apply方法
应用
将对象分为多块,然后在每一块上调用传递的函数,之后尝试将每一块拼接在一起
压缩分组键
除了函数还可以传递其他参数或关键字,要放在函数后进行传递
group_keys=False
分位数与桶分析
禁用分组键形成的分层索引
cut/qcut返回的Categorical对象可以直接传递给groupby
数据透视表
交叉表
pandas.crosstab函数
是根据一个或多个键聚合一张表的数据,将数据在矩形格式中排列,其中一部分分组键
是沿着行的,另一些是沿着列的
pivot_table方法和pandas.pivot_table顶层函数
margins=True
index
添加部分总计
columns
增加一个All行和列标签
aggfunc
使用不同的聚合函数或函数列表
fill_value
填补空值
fill_value=0
是数据透视表的一个特殊情况
默认是mean
dropna
如果为True,将不含所有条目均为NA的列
margins
添加行/列小计和总计
默认为False
计算的是分组中的频率
前两个参数可以是数组、Series或数组的列表
第一个参数是columns
第二个参数是index
资源评论













