数据爬取_正则解析1
需积分: 0 137 浏览量
2022-08-03
15:40:54
上传
评论
收藏 1.08MB PDF 举报

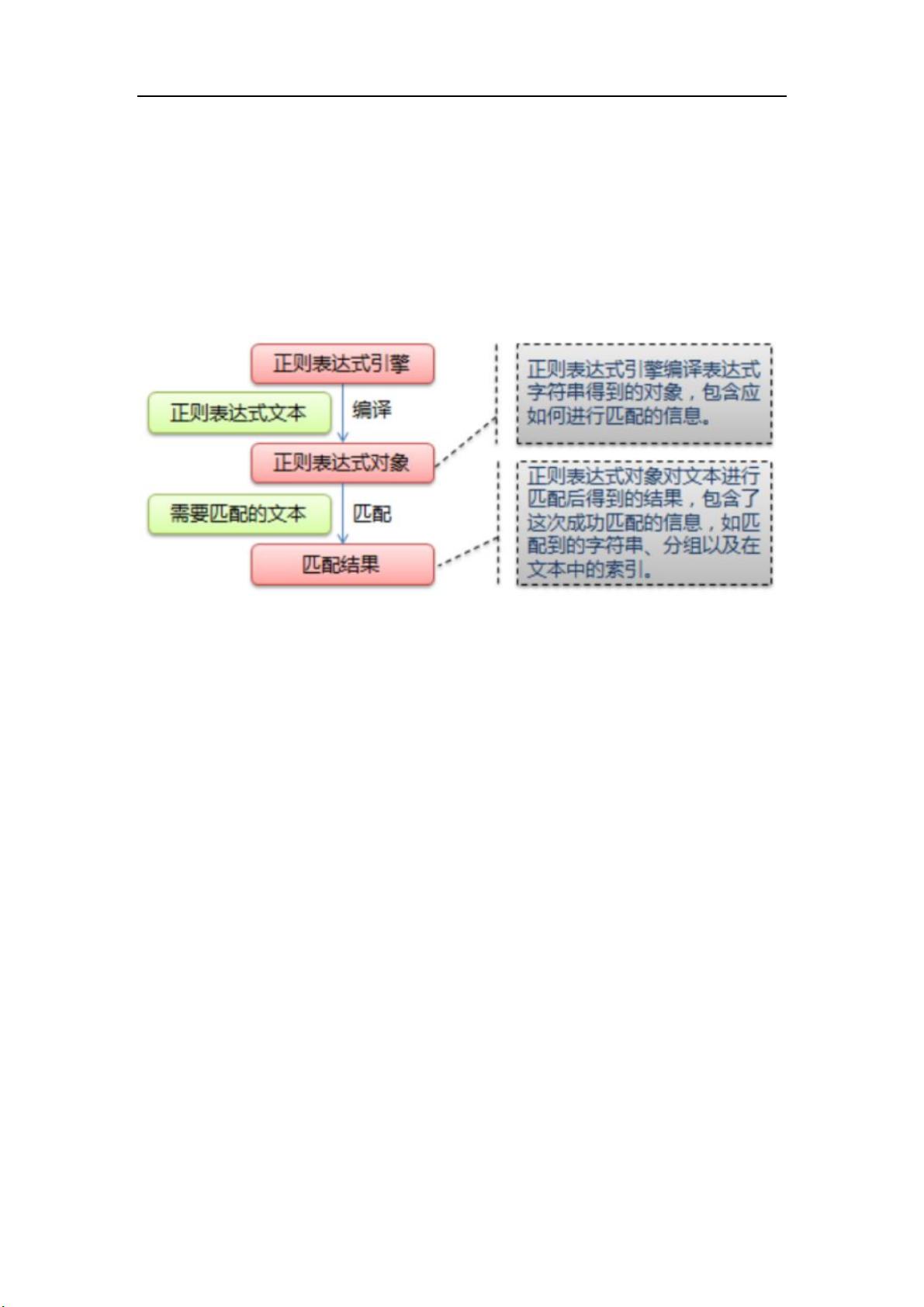
python 之――――用正则表达式提取数据
1 / 18 奇酷学院高级讲师:郭建涛
用正则表达式提取数据
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
复习回顾
单字符匹配,多字符匹配,匹配分组,
对文本进行匹配查找的一系列方法
match 方法:从起始位置开始查找,一次匹配
search 方法:从任何位置开始查找,一次匹配
findall 方法:全部匹配,返回列表
finditer 方法:全部匹配,返回迭代器
split 方法:分割字符串,返回列表
sub 方法:替换



剩余17页未读,继续阅读













评论0