没有合适的资源?快使用搜索试试~
我知道了~
文库首页
大数据
算法与数据结构
数据结构课程设计实验报告_内部排序算法比较.doc
数据结构课程设计实验报告_内部排序算法比较.doc
1.该资源内容由用户上传,如若侵权请联系客服进行举报
2.虚拟产品一经售出概不退款(资源遇到问题,请及时私信上传者)
版权申诉
数据结构
文档资料
排序算法
5星
· 超过95%的资源
1 下载量
63 浏览量
2022-05-30
13:09:11
上传
评论
收藏
2.1MB
DOC
举报
温馨提示
五一特惠:¥17.90
37.90
数据结构课程设计实验报告_内部排序算法比较.doc
资源详情
资源评论
数据结构课程设计
实验报告
内部排序算法比较
08
级计算机科学与技术专业
E10814131
郭磊
2010
年
06
月
13
日
【实验简介】
1
、
在教
科书
各种
内部
排序
算法
的时
间复
杂度
分析
结果
只给
出了
算法
执行
的
时
间
的
阶
,
或
大
概
的
执
行
时
间
,
如
:
直
接
插
入
排
序
即
时
间
复
杂
度
为
O
(
n*n
)
2
、
通过
五组
随机
数据
、一
组正
序数
据与
一组
逆序
数据
比较
6
种常
用的
内部
算法
(起
泡排
序、
直接
插入
排序
、简
单选
择排
序、
快速
查找
排序
、希
尔
排序、堆排序)的关键字比较次数和关键字移动次数,以取得直观感受;
3
、
用五组
不同的长度
不小于
100
的数据
进行测试,
并对测试结
果作出简
单
的分析,对得出结果拨动大小的进行解释;
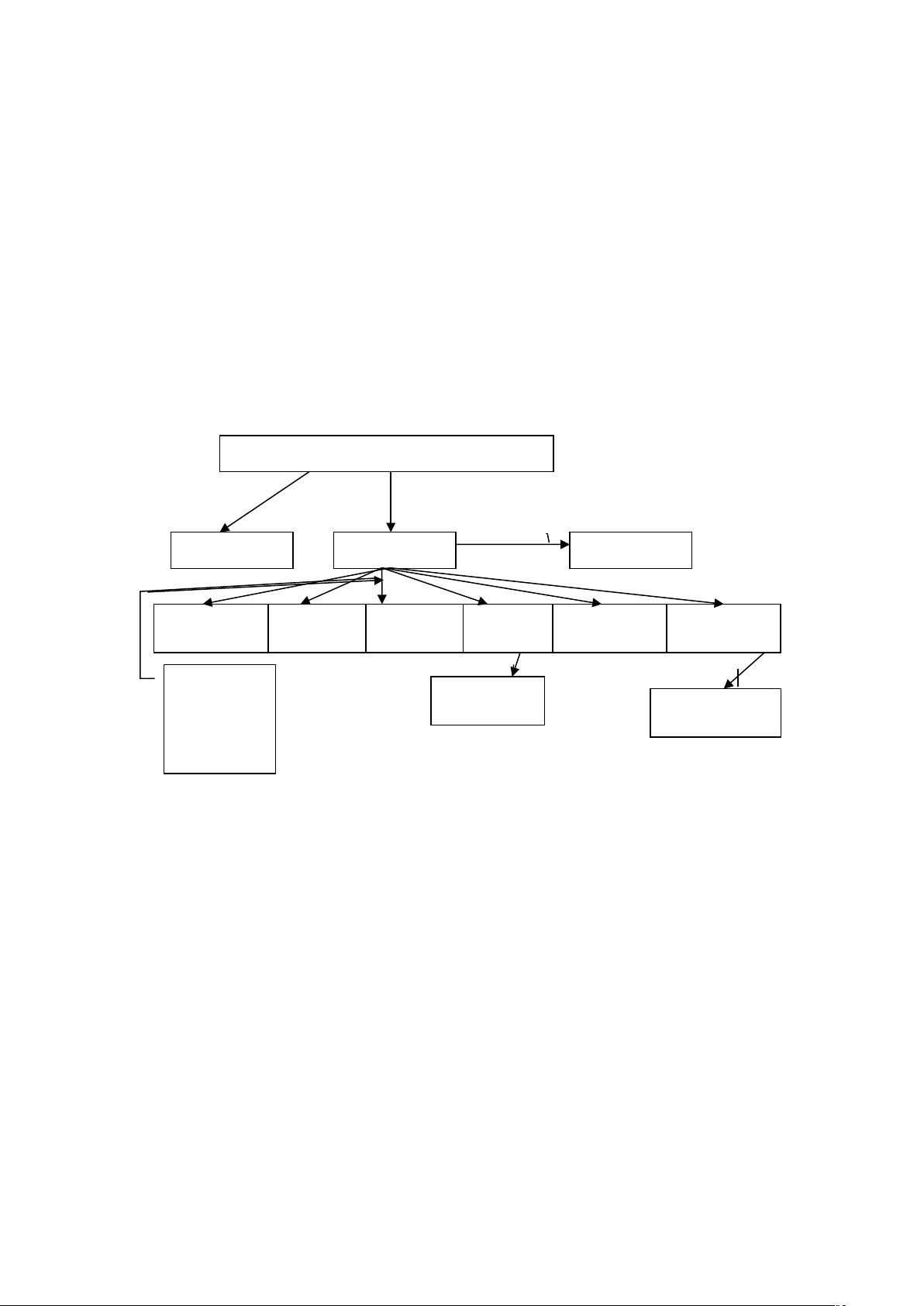
【设计模块】
【对应模块算法说明】
(1)
此算法程序中需要用到顺序表数据类型
,
数据元素的类型定义如下
:
typedef struct{
K
eyT
ype k
ey; //
关键字项
}R
edT
ype;
typedef struct{
R
edT
ype r[MAXSIZE+1]; //0
号单元闲置或用作哨兵单元
int length; //
顺序表长度
int info; //
记录关键字移动次数
int cmp; //
关键字的比较次数
}Sqlist;
(2)
本实验用
到六种排
序算法,
一个主函
数和菜单
函数
,
其中排
序算法分
别为起泡
排序、直
接插
入排序
、简
单选择
排序、
快速
查找排序
、希
尔排序
、堆排
序;
相应时
间复杂
度分
析如
下:
起泡
排序
:
若待
排序
列为
“正
序”
,则
需进
行一
趟排
序在
排序
过程
中关
键字
需进
行
n-1
次比
较,无
须移动纪
录;若是
“逆序”
,则进行
n-1
趟排序
,需
n(n-1)/2
次比较
,并坐等
数量级
调用
调用
调用
HeapAdjust
主函数
生成随机数
Switch
函数
菜单函数
SelectSort
insertSort
BubbleSort
ShellSort
HeapSort
ser
chSort
QSort
根
据
菜
单
函
数
返
回
值
调
用
相
应
的
操
作函数
的移动,因此总的事件复杂度为
O
(
n
2
)
;
直
接
插
入
排
序
待
排
序
纪
录
是
随
机
的
,
关
键
字
间
的
移
动
次
数
和
比
较
次
数
的
平
均
值
约
为
n*n/4,
即时间复杂度为
O
(
n
2
)
;
简单的选择
排序
虽
然在排序过程中所
需要的移动次数较
少,最小时为
0
,最大时为
3
(
n-
1
)
;
但
是
关
键
字
的
比
较
次
数
总
是
相
同
的
,
均
为
n(n-1)/2
,
因
此
,
时
间
复
杂
度
亦
为
O
(
n
2
)
;
快
速排
序
其平
均时
间
是
kn*
㏑
n,
其中
n
为待
排序
列
中纪
录
的个
数,
k
为某
个常
数
,其
时
间复杂度为
O
(
n*
㏑
n
);
希
尔排
序
当
增序
序
列
为
dlta[k]=2
t-k+1-1
时
,时
间
复
杂度
为
O
(
n
3/2
)
,
其中
t
为
排序
趟
数
,
1≤k≤t≤
㏒
2
(n+1);
堆排序
此排序对于含
n
个元素的序列排序时,总共进行的关键字比较次数不超过
4n
,且
在最坏的情况下,其时间复杂度为
O
(
n*
㏑
n
);
算法分析如下:
①
冒
泡
排
序
该
算
法
的
的
思
路
是
首
先
将
第
1
个
记
录
的
关
键
字
负
值
给
L.r[0]
,
然
后
用
L.r[0]
与第(
i+1
)个记录
的关键字比较
,
若
为逆序
,
则交换第
i
与第
i+1
两记录的位置
,
然后
让
i
加
1
,
重复以
上操作
,直
至
i=n-1
为止
;
依次
进行第
二趟、
第三
趟……
作同样
的操
作,
直
至所
有
的
记录
按
正
序
排列
(
一
般需
要
n-1
趟
比较
,
第
i
趟
从
L.r[1]
到
L
.r[n-i+1]
依次
比
较,
1≦ i ≦n-i
,比较结果是让其中最大的记录放在
L.r[n-i+1]
的位置)
void BubbleSort(Sqlist *L) //
冒泡排序
{
for(i=0;i<L->length;i++)
{
L->r[0]=L
->r[1];
for(j=1;j<N-i;j++)
if(L->r[0].k
ey>=L->r[j+1].k
ey)
L->r[j]
L
->r[j+1];
//
交换两记录的位置
else
L->r[0]=L
->r[j+1];
//
保证
L->r[0]
始终为较大的记录
L->r[j+1]=L
->r[0];
//
把最大的记录放到祠堂排序的最高位置
}
printf(L->r[MAXSIZE]);//
输出排序后数组和相关数据
}
②
直接插
入排序
本算法的
思路是,
把
L->r[0]
设置为哨
兵,排序
时把第
i
个
记录复制
给
哨兵
,并
于其
前的
i-1
个记
录进
行比
较,
找到
第一
个比
起大
的记
录,利
用循
环让
记录
后移
,
把其放到第一个比起大的记录前面。
void insertSort(Sqlist *L) //
直接插入排序
{
for(i=2;i<=L->length;i++)
{
if((L->r[i].k
ey < L->r[i-1].k
ey))
{
L->r[0] = L
->r[i]; //
复制哨兵
L->r[i] = L
->r[i-1];
for(j=i-2;(L->r[0].k
ey < L->r[j].k
ey);j--)
L->r[j+1] = L
->r[j]; //
纪录后移
L->r[j+1] = L
->r[0]; //
插入到正
确
位置
}
}
printf(L->r[MAXSIZE]);//
输出排序后数组和相关数据
}
③
简单选
择排序
基
本
思
想
是在
第
i
趟选择
排序时:
通过
n-i
次关
键字
之
间
的比较,
从
n-
i+1
个记录中选出关键字最小的记录,并和第
i
(
1≦ i ≦n
)个记录交换
之
void SelectSort(Sqlist *L) //
简单选择排序
{
for (i=1; i<=L->length; ++i) //
选择第
i
小的记录,并交换到位
{
L->r[0]=L
->r[i];j=i;
for(k=i+1;k<=L->length;k++)//
从
L.r[i..L.length]
中选
key
最小的
if(L->r[0].k
ey>L->r[k].k
ey)
{
L->r[0]=L
->r[k];
j=k;
}
if (i!=j)
L.r[i]←→L.r[j]; //
与第
i
个记录交换
}
printf(L->r[MAXSIZE]);//
输出排序后数组和相关数据
}
④
快
速查
找
排序
其
基
本
思
想
为,
通
过一
趟
排序
将
带
排
序
记录
分
割
成
两
部分
,其
中
一部
分记
录的关
键字
均小于
另
一
部分的
关键字
,
再
利用
递
归
分
别对分
割
所
得到的
子
序
列进行
快
速排序。其中一趟快速排序的算法为:
int ser
ch
Sort(Sqlist *L,int low,int high) //
快速排序单次排序
{
pivotk
ey=L->r[low].k
ey; //
枢轴
纪录关键字
while(low<high)
{
while(low<high && L->r[high].k
ey>=pivotk
ey)
high--;
L->r[low]
L
->r[high];
//
将比
枢轴
纪录小的纪录移到
底端
while(low<high && L->r[low].k
ey<=pivotk
ey)
low++;
L->r[high]
L
->r[low]
; //
将比
枢轴
纪录大的纪录移到高
端
}
ret
urn high;
//
返回
枢轴
所在位置
}
递归
算法为:
void QSort(Sqlist *L, int low, int high) //
快速排序
{
if (low < high)
{ //
长度大于
1
pivotloc = serchSort(L, low,
high);
//
调用
ser
chSort
()将
L.r[low
..high]
一
分为
二
QSort(L, low, pivotloc-1); //
对
低子
表
递归
排序,
pivotloc
是
枢轴
位置
QSort(L, pivotloc+1, high);
//
对高
子
表
递归
排序
}
}
⑤
希尔排序
基
本思路是先将
整
个待排序的记录
分
割
成若
干
个
子
序
列进行直接排序,
待
整
个序列中的记录“
基
本有序”时,
再
对
全体
记录进行一次
全体
直接插入排序
void ShellSort(Sqlist *L,int dlta[],int t) //
希尔排序
{
for(k=1;k<=t;k++)
{
dlta[k]=(int)pow(
2,
t-k+1
)-1;//double
pow(
double
base,
double
exp );
函数返回以
参
数
base
为
底
的
e
xp
次
幂
for(i=dlta[k]+1;i<=L->length;i++)
if(L->r[i].k
ey < L->r[i-dlta[k]].k
ey)
{
L->r[0] = L
->r[i];
for(j=i-dlta[k];j>0 && (L->r[0].k
ey < L->r[j].k
ey);j-=dlta[k])
L->r[j+dlta[k]] = L
->r[j];
L->r[j+dlta[k]] = L
->r[0];
}
}
printf(L->r[MAXSIZE]);//
输出排序后数组和相关数据
}
⑥
堆排序
基
本思
想
是
使
记录序列按关键字
非递减
有序排列,
则
再
对排序的算法
中先
建立
一个
“大
顶
堆
”
,即先
选得
一个
关键
字为
最大
的记
录与
序列
中最
后一
个记
录交
换,
然后
再
对
序列中前
n-1
记录进行
筛
选,重
新
将
它
调
整
为“大
顶
堆“,如此
反
复直至排序结
束
。
void
HeapAdjust(Sqlist
*L,
int
s,
int
m)
{
//
已
知
L.r[s..m]
中
记
录
的
关
键
字
除
L.r[s].k
ey
之外
均
满足
堆的定
义,
本函数
调
整
L.r[s]
的关键
字,
使
L.r[s..m]
成为
一个大
顶
堆(对其中记录的关键字
而言
)
rc = L
->r[s];
for (j=2*s; j<=m; j*=2) { //
沿
k
e
y
较大的
孩子
结
点向
下
筛
选
if (j<m && L->r[j].k
ey<L->r[j+1].k
ey) ++j;//j
为
k
ey
较大记录的下
标
if (rc.k
ey >= L->r[j].
key) br
eak; /
/ r
c
应插入在位置
s
上
L->r[s] = L
->r[j];
s = j;
}
L->r[s] = r
c; //
插入
}
void HeapSort(Sqlist *L) //
堆排序
{
for(i=L->length/2;i>0;i--) //
把
H->r[…]
建
成大
顶
堆
剩余63页未读,
继续阅读
评论
收藏
内容反馈
1.该资源内容由用户上传,如若侵权请联系客服进行举报
2.虚拟产品一经售出概不退款(资源遇到问题,请及时私信上传者)
版权申诉
五一特惠:¥17.90
37.90
评论1
去评论
m0_55781655
2022-06-07
用户下载后在一定时间内未进行评价,系统默认好评。
最新资源
tp_music.sql
camera view 1.0.0.unitypackage
压力测试撒大撒大撒大撒
图像视频的车牌检测系统
Matlab Traffic ToolBox
包含全桥变压器计算过程
DB2数据库单机部署安装
Suno AI 音乐下载工具
QT实现的证券盘口信息界面
测试工程师的简单版本OKR
老帽爬新坡
粉丝: 79
资源:
2万+
私信
下载权益
C知道特权
VIP文章
课程特权
VIP享
7
折,此内容立减5.37元
开通VIP
上传资源 快速赚钱
前往需求广场,查看用户热搜
相关推荐
实验7: 内部排序算法比较.doc
实验7: 内部排序算法比较.doc 实验7: 内部排序算法比较.doc 实验7: 内部排序算法比较.doc
(完整word版)数据结构(C语言版)实验报告(内部排序算法比较).doc
(完整word版)数据结构(C语言版)实验报告(内部排序算法比较).doc
数据结构实验报告-查找与排序算法17.doc
数据结构实验报告-查找与排序算法17.doc
数据结构实验报告-查找与排序算法18.doc
数据结构实验报告-查找与排序算法18.doc
数据结构实验报告-查找与排序算法22.doc
数据结构实验报告-查找与排序算法22.doc
河北工业大学-数据结构实验报告-内部排序算法效率比较平台的设计与实现.doc
河北工业大学-数据结构实验报告-内部排序算法效率比较平台的设计与实现.doc
数据结构实验报告--多关键字排序.doc
直接插入排序,希尔排序,简单选择排序,冒泡排序,快速排序,堆排序,归并排序主要通过某种策略移动,选择或交换关键字来实现,关键字选择上,为了简便起见,都是整形数据。关键字间的比较,也都是直观的大小比较。...
数据结构 课程设计 排序算法的比较
数据结构课程设计 包括以下算法:直接插入排序,希尔排序,冒泡排序,快排,简单选择排序,堆排序。完整DOC文档,含源代码,还有执行结果,完整的实验报告
4星 · 用户满意度95%
数据结构课程设计报告几种排序算法的演示(附源代第四次实验码)毕业论文.doc
数据结构课程设计报告几种排序算法的演示(附源代第四次实验码)毕业论文.doc
数据结构各种排序算法的课程设计实验报告(C语言版).doc
数据结构各种排序算法的课程设计实验报告(C语言版).doc
5星 · 资源好评率100%
数据结构-排序-实验报告.doc
数据结构实验报告 课程 数据结构 _ 实验名称 实验六: 内部排序 院 系 专业班级 实验地点 姓 名 学 号 实验时间 指导老师 实验成绩 批改日期 1. 实验目的 1. 熟悉相关的排序算法 2. 实验内容及要求 1. 实现两种排序...
数据结构实验报告(四):实现典型的排序算法.doc
数据结构实验报告(四):实现典型的排序算法.doc
数据结构排序实验报告.doc
《数据结构》课程设计报告 实验五 排序 一、需求分析: 本演示程序用C++6.0编写,完成各种排序的实现,对输入的一组数字实现不同的排序 方法,对其由小到大顺序输出。 (1)分别对直接插入排序、希尔排序、冒泡排序...
数据结构内排序实验报告.doc
设计一个程序exp10—1.cpp实现直接插入排序算法,并输出{9,8,7,6,5,4,3,2,1 ,0}的排序过程。 1. 源程序如下所示: //文件名:exp10-1.cpp #include <stdio.h> #define MAXE 20 //线性表中最多元素个数 typedef int ...
数据结构查找算法实验报告.doc
数据结构实验报告 实验第四章: 实验: 简单查找算法 1. 需求和规格说明: 查找算法这里主要使用了顺序查找,折半查找,二叉排序树查找和哈希表查找四种方法 。由于自己能力有限,本想实现其他算法,但没有实现。其中...
数据结构实验报告--链式基数排序算法.doc
1.需求分析 ①.问题描述 给出一组数据,按照最低位优先的方法完成基数排序。多关键码排序按照从最主位关键码到最次位或从最次位到最主位关键码的顺序逐次排序。
5星 · 资源好评率100%
数据结构实验报告 排序.doc
通过比较各排序算法对于数据存储结构的要求,体会算法设计不依赖于数据存储结构,而算法实现依赖于数据存储结构;通过分析排序算法的效率,研究如何进一步提高算法性能的方法。要求掌握每种排序算法思路、算法描述、...
5星 · 资源好评率100%
2019数据结构与算法实验报告.doc
线性表的逻辑特征;栈,二叉树构造、二叉树遍历,图的遍历、拓扑排序等,,文字代码应有尽有,大学数据结构必备报告。
数据结构实验报告--用简单数组实现下面各种排序算法.doc
数据结构实验报告--用简单数组实现下面各种排序算法
5星 · 资源好评率100%
全国计算机等级考试二级Python真题及解析.docx
全国计算机等级考试二级Python真题及解析 全国计算机等级考试二级Python真题及解析全文共19页,当前为第1页。全国计算机等级考试二级Python真题及解析全文共19页,当前为第1页。全国计算机等级考试二级Python真题及解析(5) 全国计算机等级考试二级Python真题及解析全文共19页,当前为第1页。 全国计算机等级考试二级Python真题及解析全文共19页,当前为第1页。 一、选择
1000份ppt模版,PPT模板优秀PPT
ppt模版,商务模版,海量精品流行PPT模板全新上线,各类动态创意PPT模板/优秀PPT模板/国内外PPT模板,创意设计,ppt模板,只要您想的..PPT模板网提供各类PPT模板免费下载,PPT背景图,PPT素材,PPT背景,免费PPT模板下载,PPT图表,精美PPT下载,PPT课件下载,PPT背景图片免费下载;简约红蓝渐变圆点背景PPT模板免费下载 简洁PPT模板 下载:13187次 紫色简约时
matlab批量读取excel表格数据并处理画图
批量读取全部sheet内容,可指定,并对无效内容处理,提取所需数据并画图
5星 · 资源好评率100%
导入证书可以解决”无法建立到信任根颁发机构的证书链"问题。
解决”无法建立到信任根颁发机构的证书链",则导入相关证书。
5星 · 资源好评率100%
OpenCv车辆识别训练模型
OpenCv车辆识别训练模型
5星 · 资源好评率100%
代码随想录知识星球精华-大厂面试八股文第二版v1.2.pdf
代码随想录知识星球精华-大厂面试八股文第二版v1.2.pdf c++ java go
Vue-Element UI集成ECharts实现数据统计分析页代码部分(如果帮助到你,感谢关注点赞)
关于《Vue-Element UI集成ECharts实现数据统计分析页》文章的具体代码实现。(如果帮助到你,感谢关注点赞)
数学建模对乙醇偶合制备C4烯烃的问题研究
全国大学生数学建模对乙醇偶合制备C4烯烃的问题研究省一等奖,小白第一次建模。提交的所有完整版论文pdf,可供参考。
5星 · 资源好评率100%
STM32F103C8T6中文数据手册
Cortex-M3在架构上进行的多项改进,包括提升性能的同时又提高了代码密度的Thumb-2指令集,大幅度提高的中断响应,而且所有新功能都同时具有业界最优的功耗水平。目前ST是第一个推出基于这个内核的主要微控制器厂商。STM32F100C8T6B的目的是为MCU用户提供新的自由度。它提供了一个完整的32位产品系列,在结合了高性能、低功耗和低电压特性的同时,保持了高度的集成性能和简易的开发特性。1.
5星 · 资源好评率100%
(头歌)计算机组成原理存储系统设计(HUST)1-7关答案
头歌平台计算机组成原理存储系统设计(HUST)1-7关答案txt版,想要用logisim打开要先把文件拓展名换成.circ。对应关卡为:第1关—汉字字库存储芯片扩展实验,第2关—MIPS寄存器文件设计,第3关—MIPS RAM设计,第4关—全相联cache设计,第5关—直接相联cache设计,第6关—4路组相连cache设计,第7关—2路组相联cache设计。
5星 · 资源好评率100%
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈
安全验证
文档复制为VIP权益,开通VIP直接复制
信息提交成功















评论1
最新资源