●
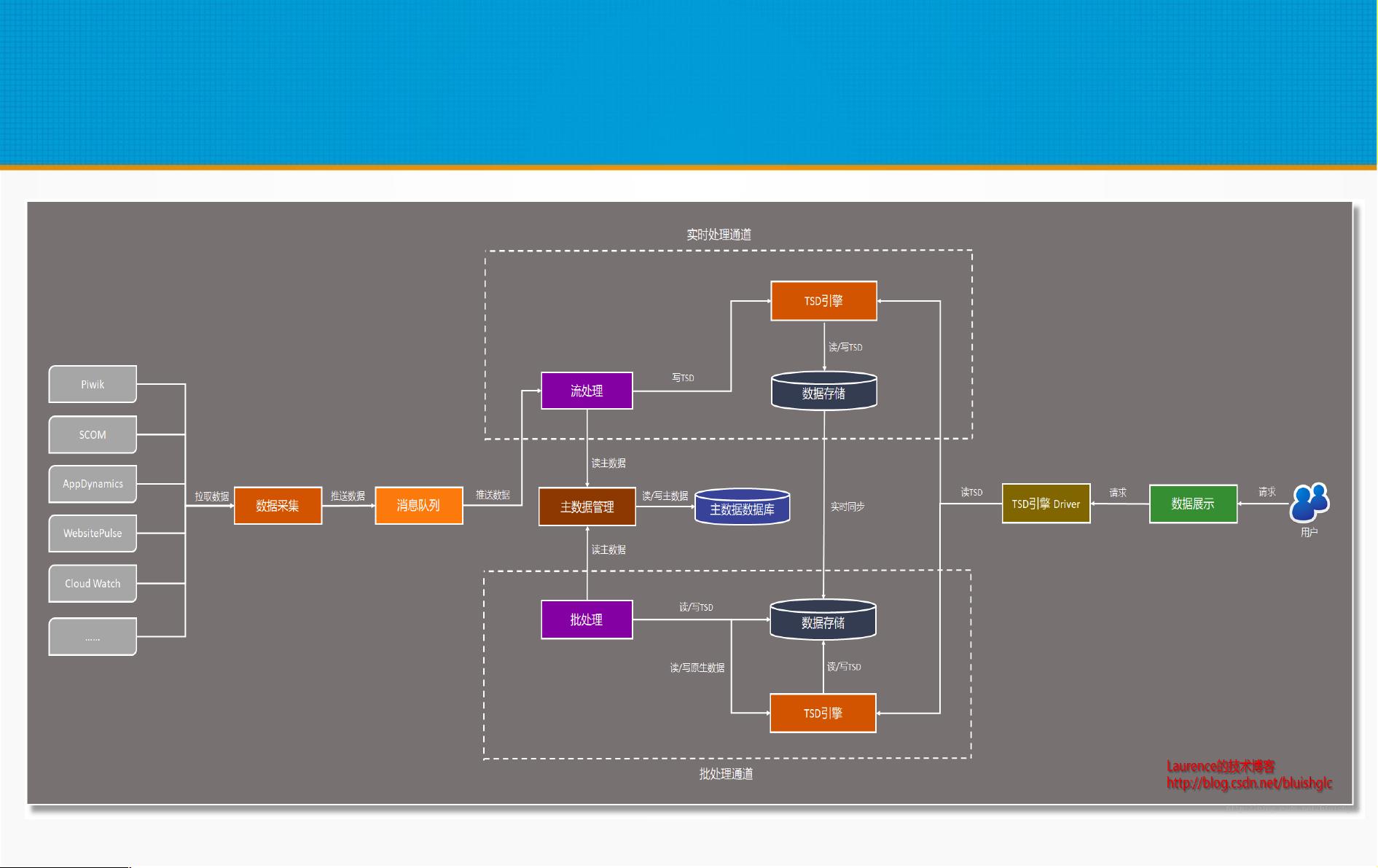
大数据平台 Lambda 架构
●
数据从底层的数据源开始,经过各种各样的格式进入大数据平台,在大数据平台中经过 Kafka 、 Flume 等数据组件进
行收集,然后分成两条线进行计算。一条线是进入流式计算平台(例如 Storm 、 Flink 或者 Spark Streaming ),去
计算实时的一些指标;另一条线进入批量数据处理离线计算平台(例如Mapreduce 、 Hive,Spark SQL ),去计算
T+1 的相关业务指标,这些指标需要隔日才能看见。
●
Lambda 架构经历多年的发展,其优点是稳定,对于实时计算部分的计算成本可控,批量处理可以用晚上的时间来整
体批量计算,这样把实时计算和离线计算高峰分开,这种架构支撑了数据行业的早期发展,但是它也有一些致命缺
点,并在大数据 3.0 时代越来越不适应数据分析业务的需求。缺点如下:
● 实时与批量计算结果不一致引起的数据口径问题:因为批量和实时计算走的是两个计算框架和计算程序,算出的结
果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
● 批量计算在计算窗口内无法完成:在 IOT 时代,数据量级越来越大,经常发现夜间只有4、 5 个小时的时间窗口,
已经无法完成白天 20 多个小时累计的数据,保证早上上班前准时出数据已成为每个大数据团队头疼的问题。
● 数据源变化都要重新开发,开发周期长:每次数据源的格式变化,业务的逻辑变化都需要针对ETL 和 Streaming 做
开发修改,整体开发周期很长,业务反应不够迅速。
● 服务器存储大:数据仓库的典型设计,会产生大量的中间结果表,造成数据急速膨胀,加大服务器存储压力。











评论1
最新资源