Hadoop框架是大数据处理领域中的核心组件,它由Apache软件基金会开发并维护,主要用于处理和存储海量数据。Hadoop的设计理念是分布式计算,它允许在廉价硬件上运行,实现高可靠性和高扩展性。Hadoop的出现,使得企业能够高效地处理PB级别的数据,为大数据分析提供了强大的工具。
**大数据概念**:大数据是指数据量巨大、增长速度快、类型多样且价值密度低的数据集合。它通常包括结构化、半结构化和非结构化数据,传统的数据处理工具难以应对这样的数据规模和复杂性。
**Hadoop核心**:Hadoop的核心主要由两个部分组成,即Hadoop Distributed File System(HDFS)和MapReduce。
**HDFS(Hadoop Distributed File System)**:是Hadoop的主要存储系统,它将大文件分布在多台服务器上,通过冗余存储确保数据的可靠性。HDFS的基本概念包括NameNode(元数据管理)、DataNode(数据存储)和Secondary NameNode(辅助NameNode,用于备份元数据)。
**HDFS特点**:
1. **高容错性**:数据自动复制,节点故障时可以自动恢复。
2. **高吞吐量**:并行处理大量数据,适合大规模数据读写。
3. **低成本**:利用普通硬件构建大规模集群。
4. **可扩展性**:易于扩展存储和计算能力。
**HDFS三个基本概念**:
1. **块(Block)**:HDFS将大文件分割成多个块,每个块默认大小为128MB。
2. **副本(Replication)**:每个数据块通常有多个副本,以提高容错性。
3. **命名节点(NameNode)**:负责管理文件系统的命名空间和块信息。
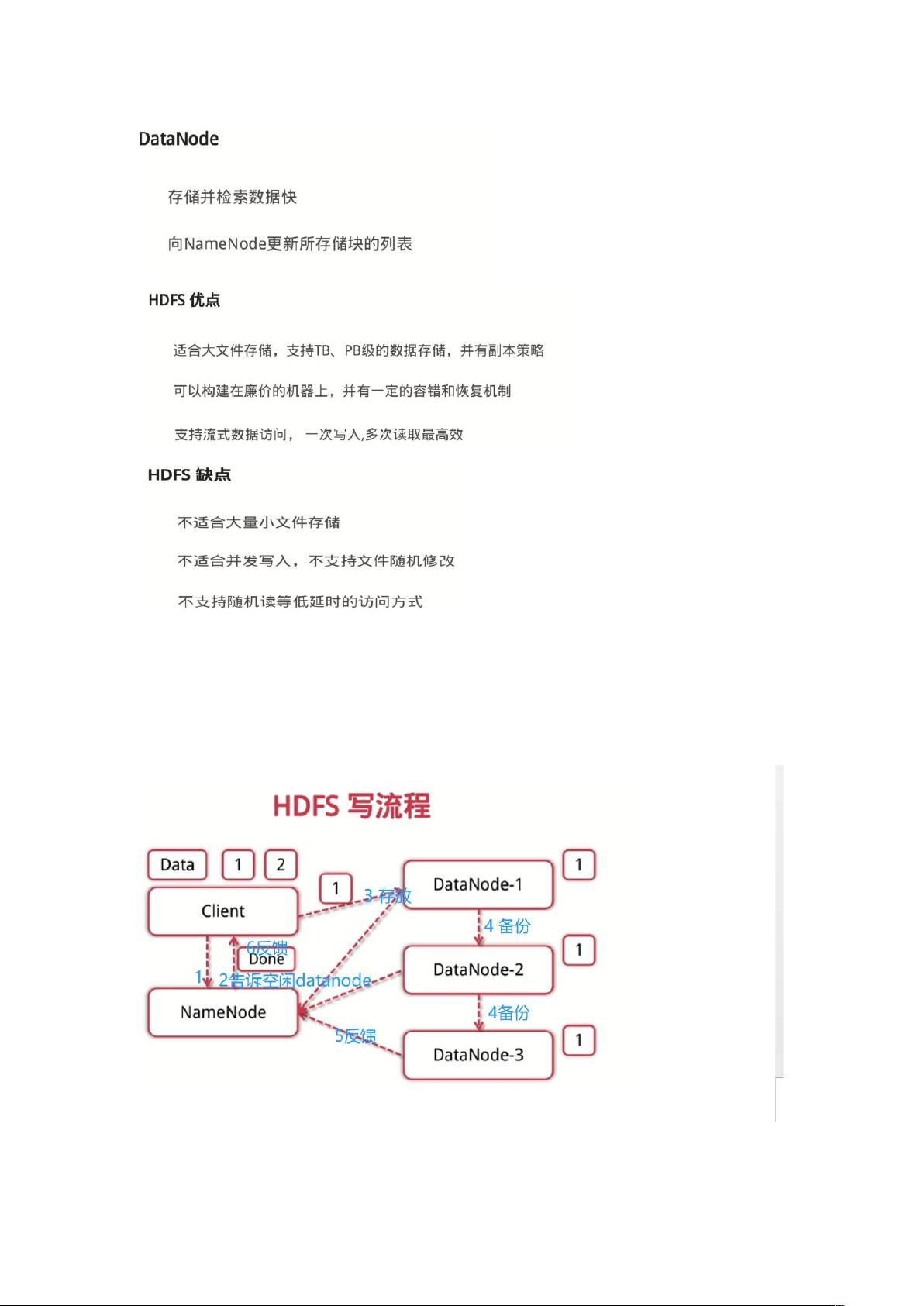
**HDFS写流程**:客户端将文件拆分为块,每个块复制到多个DataNode,并将元数据更新到NameNode。
**HDFS读流程**:客户端从NameNode获取文件块位置,然后并行从各个DataNode读取数据。
**Shell命令操作HDFS**:
- `copyFromLocal`:将本地文件系统中的文件复制到HDFS。
- `cat`:查看HDFS中文件的内容。
- `copyToLocal`:将HDFS中的文件复制回本地文件系统。
- `chmod`:更改HDFS文件或目录的权限。
**MapReduce**:是Hadoop用于处理和生成大数据的编程模型,它将任务分解为map阶段和reduce阶段,实现了数据的分布式处理。
**MapReduce实战**:
1. `Map`方法:接收键值对输入,进行转换并生成中间键值对。
2. `Reduce`方法:对中间键值对进行聚合,输出最终结果。
**MapReduce程序提交到Hadoop**:
通过`hadoop jar your-jar-file.jar your-class-name input output`命令提交MapReduce程序。
**Hadoop生态圈**:Hadoop生态还包括其他组件,如YARN(资源调度器),HBase(NoSQL数据库),Spark(快速大数据处理框架)等,它们共同构成了一个完整的大数据处理生态系统。
**Hbase**:是一个基于HDFS的分布式、高性能、列式存储的NoSQL数据库,适用于实时查询和分析大规模数据。
**Nosql**:非关系型数据库,适合处理大数据和高并发场景,如MongoDB、Cassandra等。
**Spark**:是一个用于大规模数据处理的快速、通用和可扩展的开源框架,支持批处理、交互式查询、流处理和机器学习等多种应用场景。
Hadoop框架及其生态圈提供了一个全面的解决方案,涵盖了数据存储、处理、分析和查询等大数据生命周期的各个环节,为企业的大数据战略提供了坚实的基础。









评论0
最新资源