

云计算开源框架 Hadoop 介绍
目录
云计算开源框架 Hadoop 介绍 ........................................................................................................ 1
什么是 Hadoop? ............................................................................................................................. 1
为什么要选择 Hadoop? ................................................................................................................. 4
使用场景 ........................................................................................................................................... 4
环境 .................................................................................................................................................. 5
部署考虑 ........................................................................................................................................... 5
实施步骤 ........................................................................................................................................... 5
Hadoop 中的命令( Command)总结 ............................................................................................ 8
Hadoop 基本流程 ............................................................................................................................. 8
日志分析业务场景和代码范例 ..................................................................................................... 10
Hadoop 集群测试 ........................................................................................................................... 15
随想 ................................................................................................................................................ 16
什么是 Hadoop?
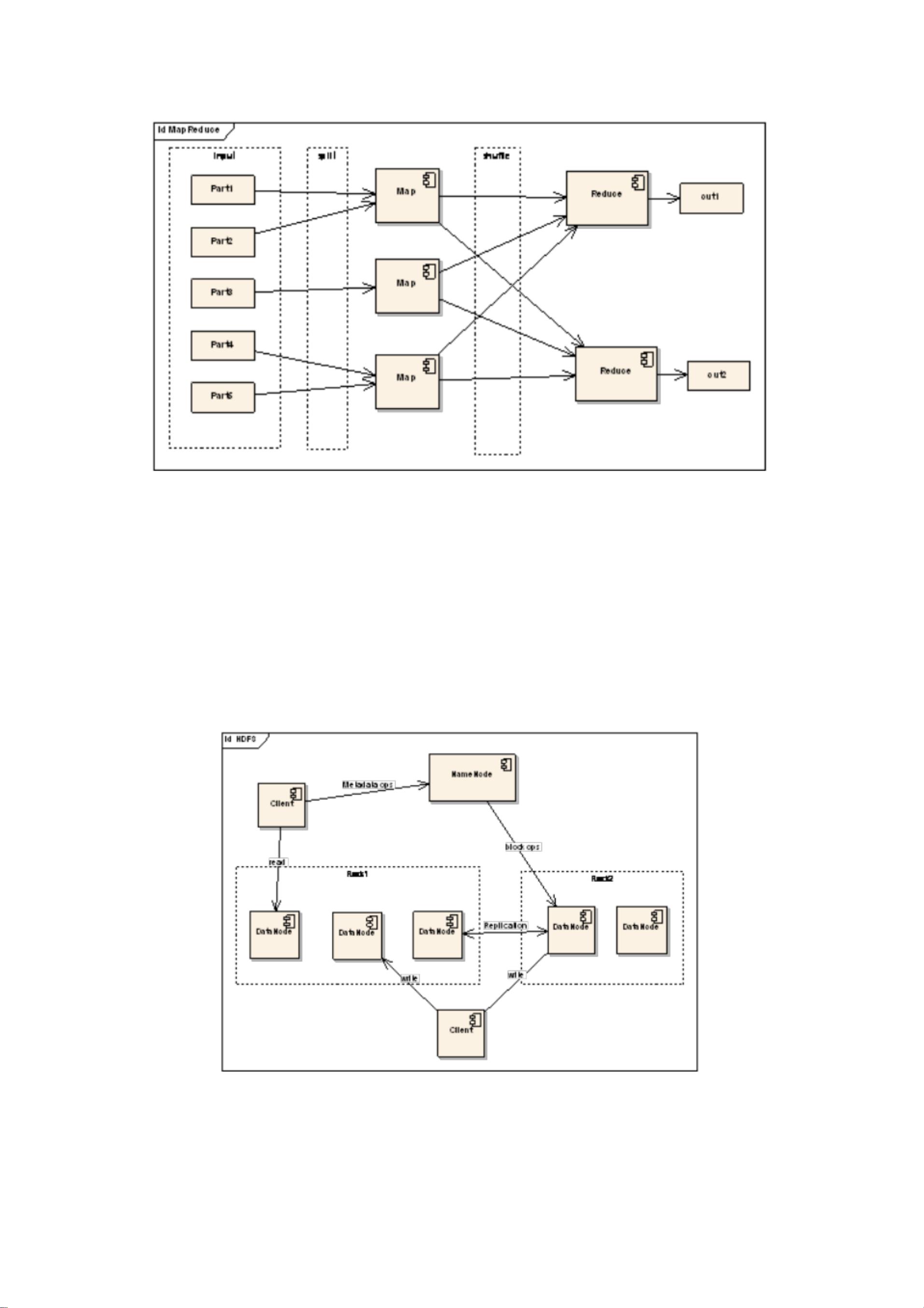
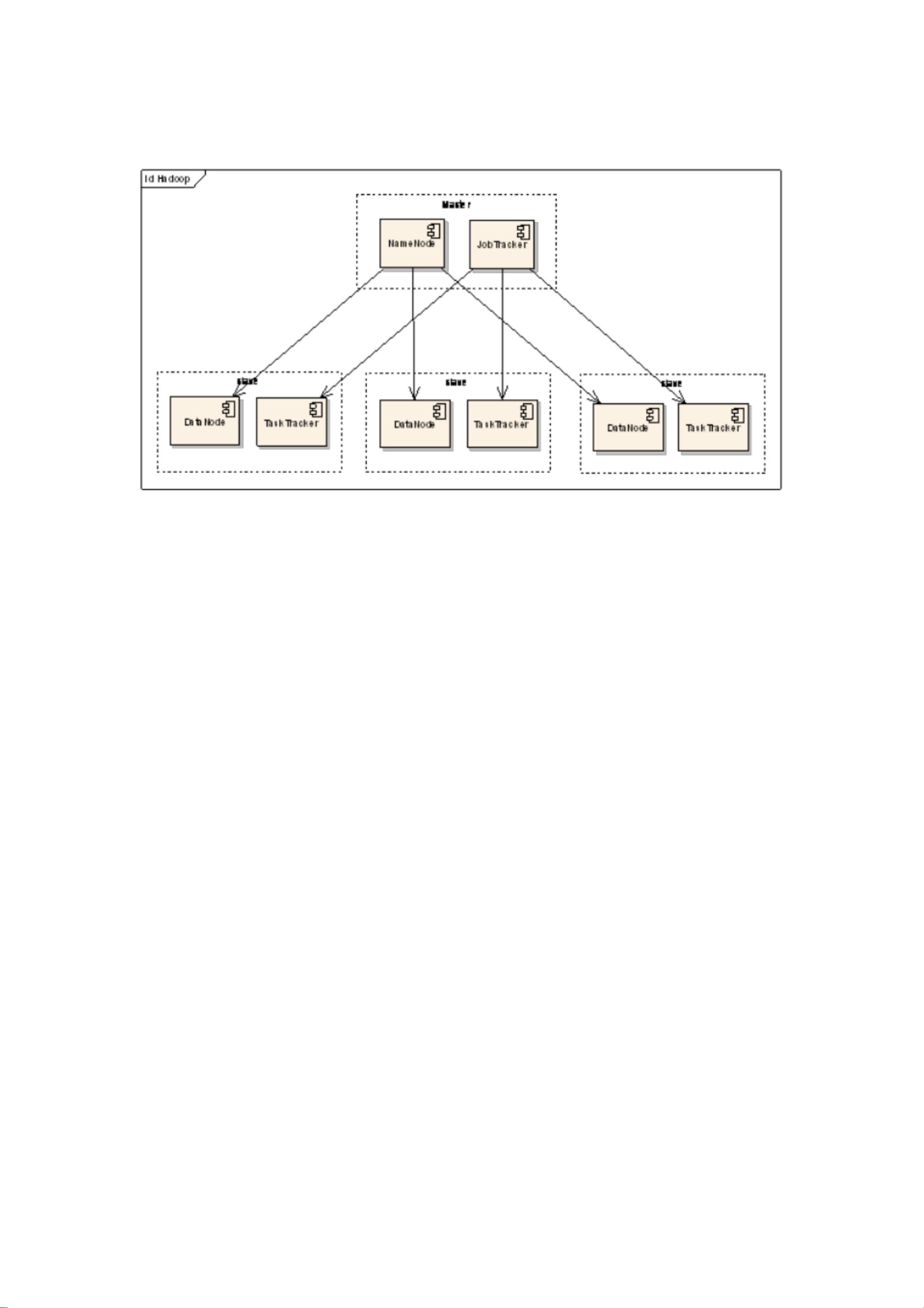
Hadoop 框架中最核心的设计就是: MapReduce 和 HDFS 。MapReduce 的思想是由 Google 的
一篇论文所提及而被广为流传的, 简单的一句话解释 MapReduce 就是 “任务的分解与结果
的汇总 ”。HDFS 是 Hadoop 分布式文件系统( Hadoop Distributed File System )的缩写,为分
布式计算存储提供了底层支持。
MapReduce 从它名字上来看就大致可以看出个缘由, 两个动词 Map 和 Reduce,“Map(展开)”
就是将一个任务分解成为多个任 务, “Reduce”就是将分解后多任务处理的结果汇总起来,
得出最后的分析结果。 这不是什么新思想, 其实在前面提到的多线程, 多任务的设计就可以
找到这 种思想的影子。不论是现实社会,还是在程序设计中,一项工作往往可以被拆分成
为多个任务,任务之间的关系可以分为两种:一种是不相关的任务,可以并行执 行;另一
种是任务之间有相互的依赖, 先后顺序不能够颠倒, 这类任务是无法并行处理的。 回到大学
时期,教授上课时让大家去分析关键路径,无非就是找最省时的 任务分解执行方式。在分
布式系统中, 机器集群就可以看作硬件资源池, 将并行的任务拆分, 然后交由每一个空闲机
器资源去处理,能够极大地提高计算效率,同时 这种资源无关性,对于计算集群的扩展无
疑提供了最好的设计保证。其实我一直认为 Hadoop 的卡通图标不应该是一个小象,应该是
蚂蚁,分布式计算就好比 蚂蚁吃大象,廉价的机器群可以匹敌任何高性能的计算机,纵向
扩展的曲线始终敌不过横向扩展的斜线。 任务分解处理以后, 那就需要将处理以后的结果再
汇总起 来,这就是 Reduce 要做的工作。

剩余15页未读,继续阅读
资源评论


资料大全
- 粉丝: 17
- 资源: 26万+











