

特点:
1. 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存 3 份。 2. 运行在廉
价的机器上。 3. 适合大数据的处理。HDFS 默认会将文件分割成 block,64M 为 1 个
block。 然后将 block 按键值对存储在 HDFS 上,并将键值对的映射存到内存中。如果小文件
太多,那内存的负担会很重。 (笔记:HDFS 不适合小文件存储:小文件多,造成内存负担。)
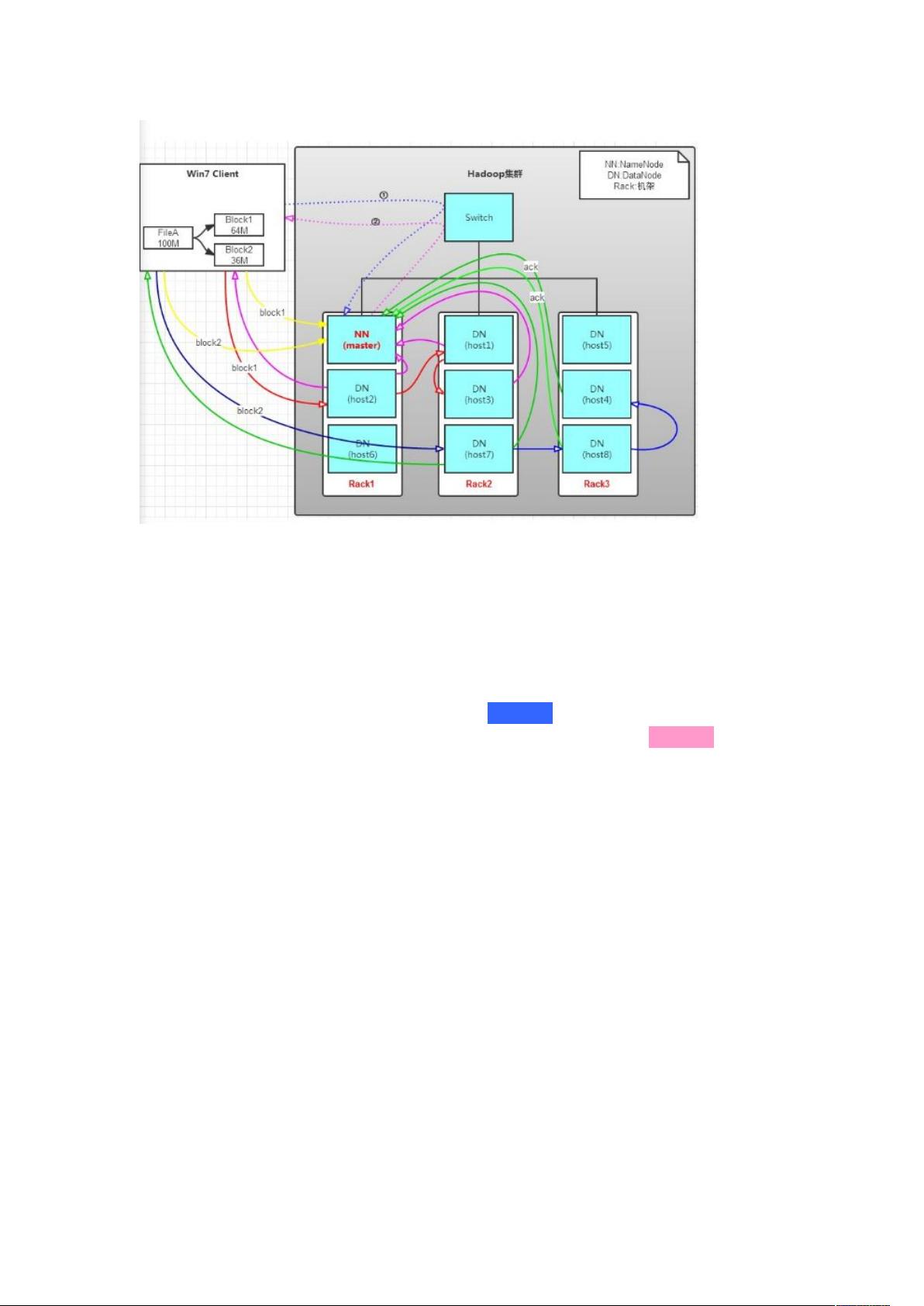
系统结构:
NameNode:
namenode 内存中存储的是 = fsimage + edits。
fsimage:元数据镜像文件:包含(文件系统的目录树)文件的 indoe 信息。对于文件来说
包括了数据块描述信息、修改时间、访问时间等;对于目录来说包括修改时间、访问权限
控制信息(目录所属用户,所在组等)等
edits:元数据的操作日志(针对文件系统做的修改操作记录):主要是在 NameNode 已经
启动情况下对 HDFS 进行的各种更新操作进行记录,HDFS 客户端执行所有的写操作都会
被记录到 edit 文件中。
在 NameNode 启动的时候,它会将 fsimage 文件中的内容加载到内存中,之后再执行 edits 文件中的
各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
存储地址:hdfs-site.xml 上的 dfs.name.dir 项,具体目录为$dfs.name.dir/current
/hadoop/hdfs/namenode/current
SecondaryNameNode:
小弟,分担大哥 namenode 的工作量。 SecondaryNameNode 负责定时默认 1 小时,从
namenode 上,获取 fsimage 和 edits 来进行合并,然后再发送给 namenode。 减少
namenode 的工作量。
NameNode 的冷备份。
注意:在 hadoop2.x 版本,当启用 hdfs ha 时,将没有这一角色。
b 是 a 的冷备份,如果 a 坏掉。那么 b 不能马上代替 a 工作。但是 b 上存储 a 的一些信息,减
少 a 坏掉之后的损失。
DataNode:
Slave 节点,奴隶,干活的。 1. 存储 client 发来的数据块 block; 2. 执行数据块的读
写操作。
剩余6页未读,继续阅读
资源评论


不想长大的敏
- 粉丝: 1
- 资源: 8









最新资源
- T型3电平逆变器,lcl滤波器滤波器参数计算,半导体损耗计算,逆变电感参数设计损耗计算 mathcad格式输出,方便修改 同时支持plecs损耗仿真,基于plecs的闭环仿真,电压外环,电流内环
- 毒舌(解锁版).apk
- 显示HEX、S19、Bin、VBF等其他汽车制造商特定的文件格式
- 8bit逐次逼近型SAR ADC电路设计成品 入门时期的第三款sarADC,适合新手学习等 包括电路文件和详细设计文档 smic0.18工艺,单端结构,3.3V供电 整体采样率500k,可实现基
- 操作系统实验 ucorelab4内核线程管理
- 脉冲注入法,持续注入,启动低速运行过程中注入,电感法,ipd,力矩保持,无霍尔无感方案,媲美有霍尔效果 bldc控制器方案,无刷电机 提供源码,原理图
- Matlab Simulink#直驱永磁风电机组并网仿真模型 基于永磁直驱式风机并网仿真模型 采用背靠背双PWM变流器,先整流,再逆变 不仅实现电机侧的有功、无功功率的解耦控制和转速调节,而且能实
- 157389节奏盒子地狱模式第三阶段7.apk
- 操作系统实验ucore lab3
- DG储能选址定容模型matlab 程序采用改进粒子群算法,考虑时序性得到分布式和储能的选址定容模型,程序运行可靠 这段程序是一个改进的粒子群算法,主要用于解决电力系统中的优化问题 下面我将对程序进行详
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


