



前言
HDFS 全称是 Hadoop Distribute File System ,是 Hadoop最重要的组件之一,也被称为分步式存
储之王。本文主要从 HDFS 高可用架构组成、HDFS 读写流程、如何保证可用性以及高频面试题出发,
提高大家对 HDFS 的认识,掌握一些高频的 HDFS 面试题。本篇文章概览如下图:
1.HA 架构组成
1.1HA架构模型
在 HDFS 1.X 时,NameNode 是 HDFS 集群中可能发生单点故障的节点,集群中只有一个
NameNode,一旦 NameNode 宕机,整个集群将处于不可用的状态。
在 HDFS 2.X 时,HDFS 提出了高可用(High Availability, HA)的方案,解决了 HDFS 1.X 时的单点问题。
在一个 HA 集群中,会配置两个 NameNode ,一个是 Active NameNode(主),一个是 Stadby
NameNode(备)。主节点负责执行所有修改命名空间的操作,备节点则执行同步操作,以保证与主节
点命名空间的一致性。HA 架构模型如下图所示:
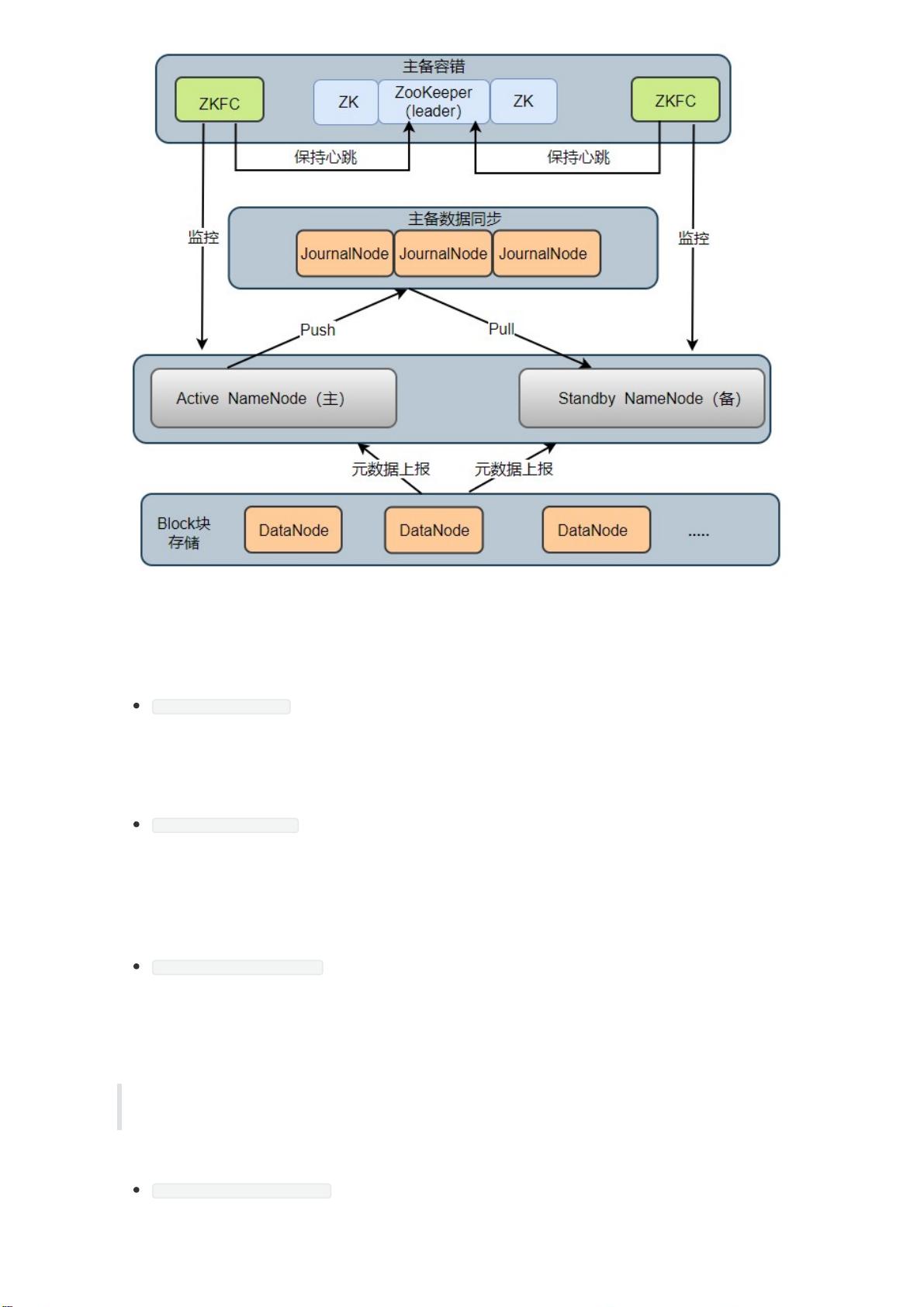
HA 集群中所包含的进程的职责各不相同。为了使得主节点和备用节点的状态一致,采用了 Quorum
Journal Manger (QJM)方案解决了主备节点共享存储问题,如图 JournalNode 进程,下面依次介绍
各个进程在架构中所起的作用:
Active NameNode: 它负责执行整个文件系统中命名空间的所有操作;维护着数据的元数据,包括
文件名、副本数、文件的 BlockId 以及 Block 块所对应的节点信息;另外还接受 Client 端读写请求
和 DataNode 汇报 Block 信息。
Standby NameNode: 它是 Active NameNode 的备用节点,一旦主节点宕机,备用节点会切换成
主节点对外提供服务。它主要是监听 JournalNode Cluster 上 editlog 变化,以保证当前命名空间
尽可能的与主节点同步。任意时刻,HA 集群只有一台 Active NameNode,另一个节点为
Standby NameNode。
JournalNode Cluster: 用于主备节点间共享 editlog 日志文件的共享存储系统。负责存储
editlog 日志文件, 当 Active NameNode 执行了修改命名空间的操作时,它会定期将执行的操作
记录在 editlog 中,并写入 JournalNode Cluster 中。Standby NameNode 会一直监听
JournalNode Cluster 上 editlog 的变化,如果发现 editlog 有改动,备用节点会读取 JournalNode
上的 editlog 并与自己当前的命名空间合并,从而实现了主备节点的数据一致性。
注意:QJM 方案是基于 Paxos 算法实现的,集群由 2N + 1 JouranlNode 进程组成,最多可以容
忍 N 台 JournalNode 宕机,宕机数大于 N 台,这个算法就失效了!
ZKFailoverController: ZKFC 以独立进程运行,每个 ZKFC 都监控自己负责的 NameNode,它
可以实现 NameNode 自动故障切换:即当主节点异常,监控主节点的 ZKFC 则会断开与

ZooKeeper 的连接,释放分步式锁,监控备用节点的 ZKFC 进程会去获取锁,同时把备用
NameNode 切换成 主 NameNode。
ZooKeeper: 为 ZKFC 进程实现自动故障转移提供统一协调服务。通过 ZooKeeper 中 Watcher 监
听机制,通知 ZKFC 异常NameNode 下线;保证同一时刻只有一个主节点。
DataNode: DataNode 是实际存储文件 Block 块的地方,一个 Block 块包含两个文件:一个是数
据本身,一个是元数据(数据块长度、块数据的校验和、以及时间戳),DataNode 启动后会向
NameNode 注册,每 6 小时同时向主备两个 NameNode 上报所有的块信息,每 3 秒同时向主备
两个 NameNode 发送一次心跳。
DataNode 向 NameNode 汇报当前块信息的时间间隔,默认 6 小时,其配置参数名如下:
1.2HA主备故障切换流程
HA 集群刚启动时,两个 NameNode 节点状态均为 Standby,之后两个 NameNode 节点启动 ZKFC 进
程后会去 ZooKeeper 集群抢占分步式锁,成功获取分步式锁,ZooKeeper 会创建一个临时节点,成功
抢占分步式锁的 NameNode 会成为 Active NameNode,ZKFC 便会实时监控自己的 NameNode。
HDFS 提供了两种 HA 状态切换方式:一种是管理员手动通过 DFSHAAdmin -faieover 执行状态切换;
另一种则是自动切换。下面分别从两种情况分析故障的切换流程:
1. 主 NameNdoe 宕机后,备用 NameNode 如何升级为主节点?
当主 NameNode 宕机后,对应的 ZKFC 进程检测到 NameNode 状态,便向 ZooKeeper 发生删除
锁的命令,锁删除后,则触发一个事件回调备用 NameNode 上的 ZKFC
ZKFC 得到消息后先去 ZooKeeper 争夺创建锁,锁创建完成后会检测原先的主 NameNode 是否真
的挂掉(有可能由于网络延迟,心跳延迟),挂掉则升级备用 NameNode 为主节点,没挂掉则将
原先的主节点降级为备用节点,将自己对应的 NameNode 升级为主节点。
2. 主 NameNode 上的 ZKFC 进程挂掉,主 NameNode 没挂,如何切换?
ZKFC 挂掉后,ZKFC 和 ZooKeeper 之间 TCP 链接会随之断开,session 也会随之消失,锁被删
除,触发一个事件回调备用 NameNode ZKFC,ZKFC 得到消息后会先去 ZooKeeper 争夺创建
锁,锁创建完成后也会检测原先的主 NameNode 是否真的挂掉,挂掉则升级 备用 NameNode 为
主节点,没挂掉则将主节点降级为备用节点,将自己对应的 NameNode 升级为主节点。
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in
milliseconds.</description>
</property>
1.3Block、packet及chunk 概念
在 HDFS 中,文件存储是按照数据块(Block)为单位进行存储的,在读写数据时, DFSOutputStream
使用 Packet 类来封装一个数据包。每个 Packet 包含了若干个 chunk 和对应的 checksum。
Block:HDFS 上的文件都是分块存储的,即把一个文件物理划分为一个 Block 块存储。Hadoop
2.X/3.X 默认块大小为 128 M,1.X 为 64M.
Packet:是 Client 端向 DataNode 或 DataNode 的 Pipline 之间传输数据的基本单位,默认 64
KB
Chunk:Chunk 是最小的单位,它是 Client 向 DataNode 或 DataNode PipLine 之间进行数据校
验的基本单位,默认 512 Byte ,因为用作校验,所以每个 Chunk 需要带有 4 Byte 的校验位,实
际上每个 Chunk 写入 Packtet 的大小为 516 Byte。
2.源码级读写流程
2.1HDFS 读流程
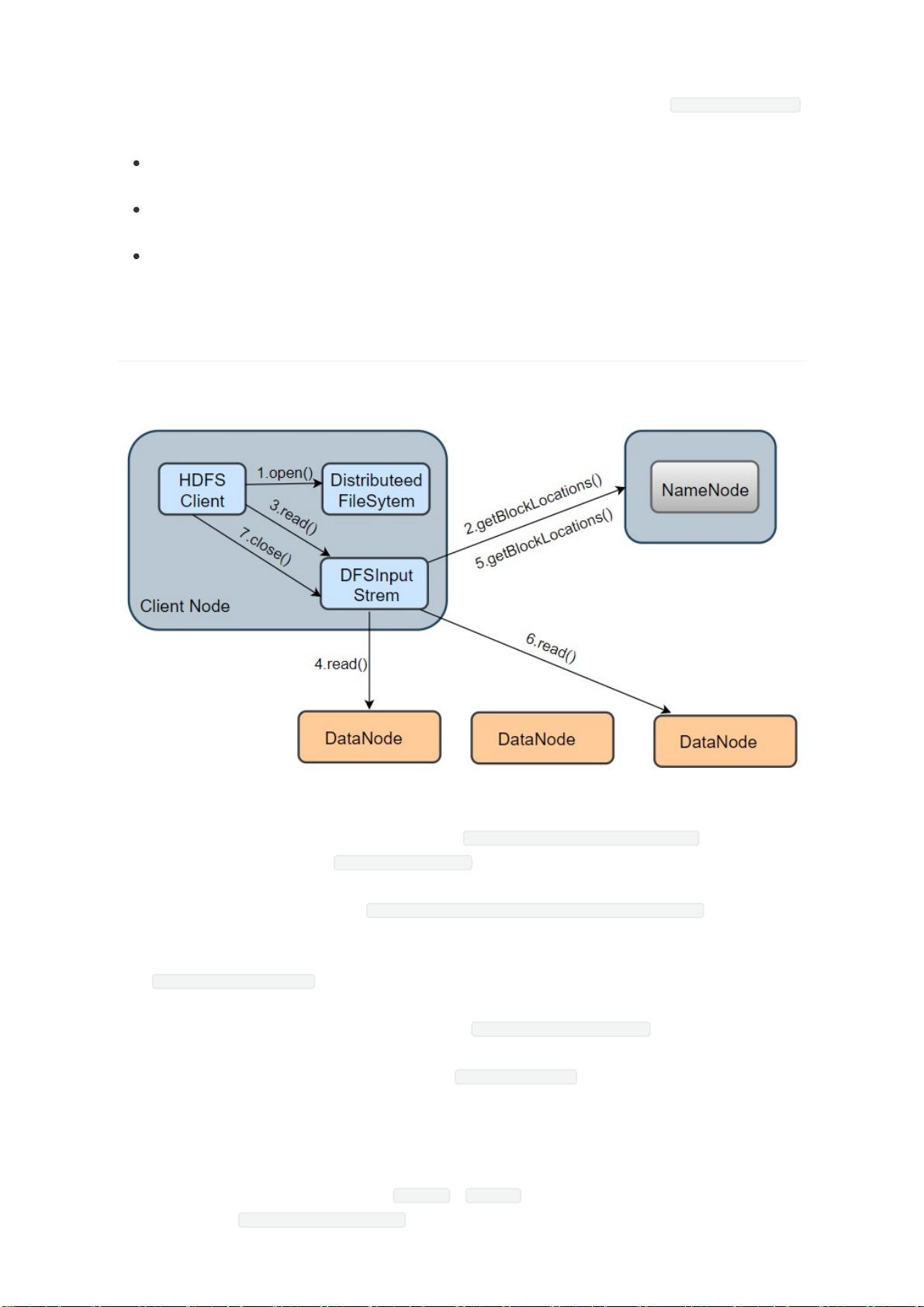
我们以从 HDFS 读取一个 information.txt 文件为例,其读取流程如上图所示,分为以下几个步骤:
1. 打开 information.txt 文件:首先客户端调用 DistributedFileSystem.open() 方法打开文
件,这个方法在底层会调用 DFSclient.open() 方法,该方法会返回一个 HdfsDataInputStream
对象用于读取数据块。但实际上真正读取数据的是 DFSInputStream ,而 HdfsDataInputStream
是 DFSInputStream 的装饰类( new HdfsDataInputStream(DFSInputStream) )。
2. 从 NameNode 获取存储 information.txt 文件数据块的 DataNode 地址:即获取组成
information.txt block 块信息。在构造输出流 DFSInputStream 时,会通过调用
getBlockLocations() 方法向 NameNode 节点获取组成 information.txt 的 block 的位置信
息,并且 block 的位置信息是按照与客户端的距离远近排好序。
3. 连接 DataNode 读取数据块: 客户端通过调用 DFSInputStream.read() 方法,连接到离客户端
最近的一个 DataNode 读取 Block 块,数据会以数据包(packet)为单位从 DataNode 通过流式
接口传到客户端,直到一个数据块读取完成; DFSInputStream 会再次调用 getBlockLocations()
方法,获取下一个最优节点上的数据块位置。
4. 直到所有文件读取完成,调用 close() 方法,关闭输入流,释放资源。
从上述流程可知,整个过程最主要涉及到 open() 、 read() 两个方法(其它方法都是在这两个方法的
调用链中调用,如 getBlockLocations() ),下面依次介绍这2个方法的实现。













