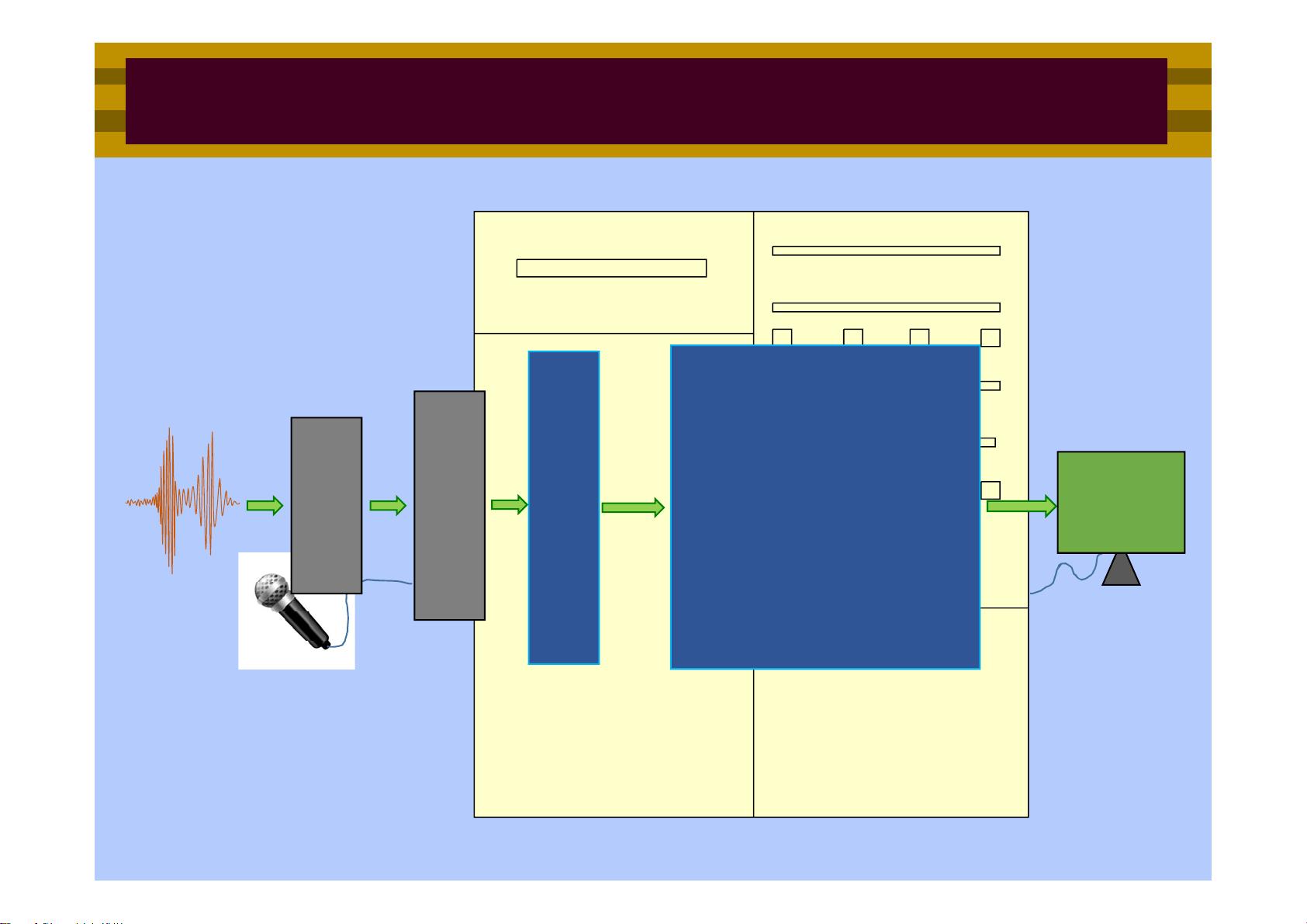
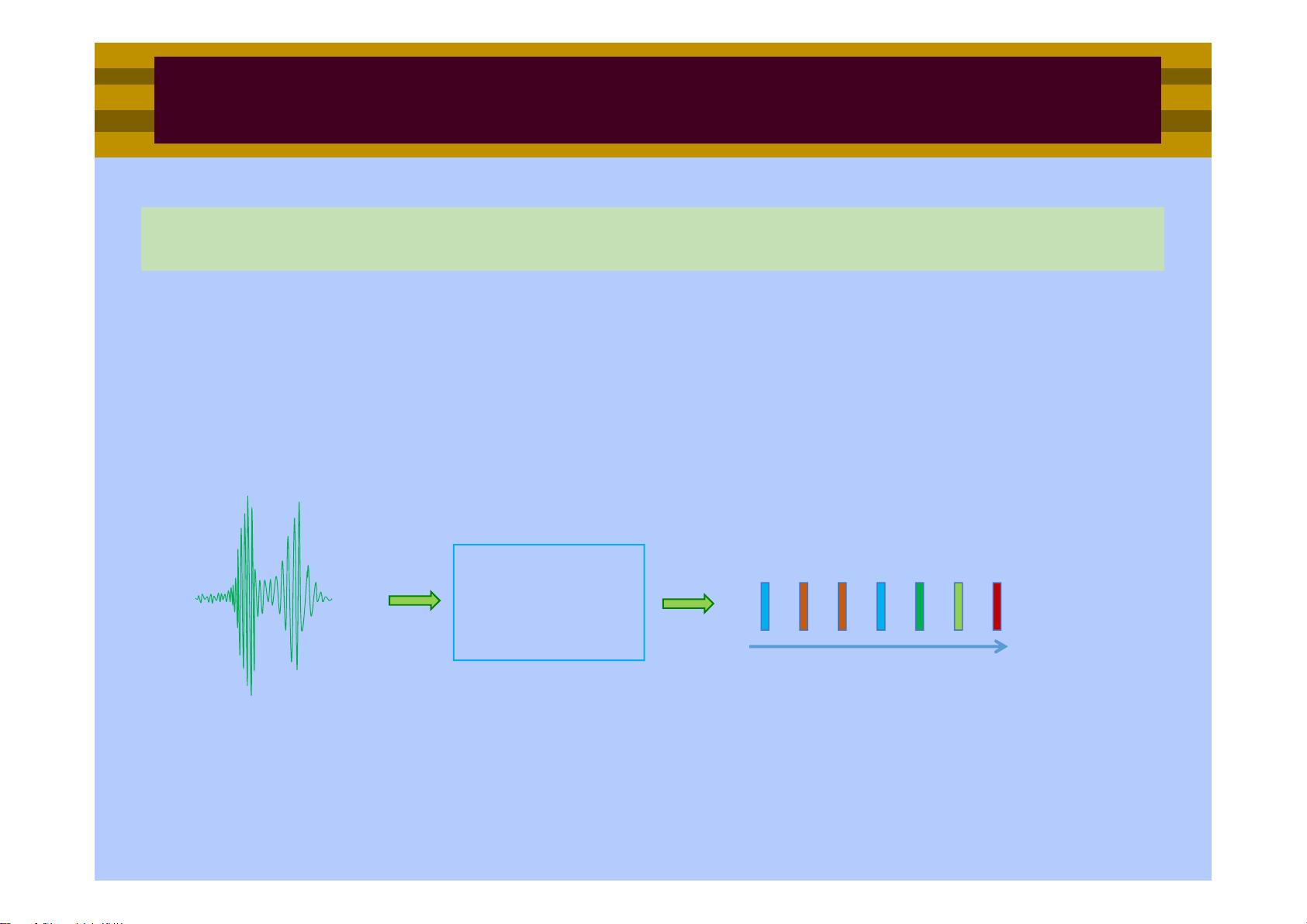
kaldi是一个流行的开源语音识别工具包,其支持多种语言和多样的语音识别系统构建。该教程首先介绍了语音识别系统的组成,包括其工作原理和系统框架。语音信号首先要通过特征提取,将连续的语音波形转换成计算机能处理的特征向量序列。特征提取的关键在于获取对识别有用的特征,并且降低处理的计算量和内存使用。其中,梅尔频率倒谱系数(MFCC)是一种常用的特征,它模拟了人耳的听觉特性,并通过梅尔尺度滤波器组提取频率包络信息。
特征提取的典型例子包括窗口函数的应用、离散傅里叶变换(DFT)、梅尔滤波器组、对数变换以及倒谱处理,这些步骤最终得到特征向量序列。窗口长度、帧移以及梅尔滤波器组的维度和帧率等参数需要根据具体应用场景进行调整。此外,特征向量的拼接技术(Splicing)用于扩展单个特征向量,包括前后的帧信息,以提供更多的上下文信息。
kaldi工具包基于统计语音识别原理,其中涉及到两个重要模型:音響模型和语言模型。音響模型主要关注在给定发音类别下特征量出现的概率,而语言模型则提供了识别目标范畴的先验概率。在概率最大化的过程中,利用贝叶斯定理进行变形,通过维特比算法(Viterbi algorithm)来寻找最可能的词序列,即识别结果。
HMM(隐马尔可夫模型)是kaldi中常用的模型,它用于建模时序数据,并且能够通过状态集合、状态转移概率和状态输出概率来描述。HMM音響模型通常采用“左到右”的形式,并且只考虑自转移或转至“下一个”状态的情况,同时定义了没有输出概率分布的初始状态和最终状态。
混合高斯模型(GMM)在kaldi中也被采用,它通过多个高斯分布的加权叠加,能够表达更复杂的概率分布。GMM的每个高斯分布具有自己的权重、均值和方差(共方差矩阵),GMM的目的是逼近样本数据的分布,提高语音识别的准确性。
在构建语音识别系统时,kaldi提供了一些针对特定应用的“食谱”(Recipes),比如针对日语对话语音识别的CSJ食谱。食谱中通常包括了必要的配置文件和脚本,帮助用户快速搭建起特定语言的语音识别系统。该教程还提供了通过实际例子和实践来加深对kaldi工具包使用方法的理解和掌握。
该教程涵盖了从语音信号处理、特征提取、模型构建到实际应用等多方面知识,为读者提供了一个全面学习和实践kaldi语音识别的平台。通过深入理解这些知识点,读者能够掌握如何使用kaldi工具包来构建性能优良的语音识别系统。