数据挖掘研究不同分类算法对不同数据集的分类效果评估

需积分: 0 152 浏览量
更新于2023-11-12
1
收藏 1.21MB DOCX 举报
在数据挖掘领域,分类算法是核心工具之一,用于预测离散型目标变量。本报告将深入探讨三种常见的分类算法——支持向量机(SVM)、决策树和随机森林,并通过对比在不同数据集上的表现来评估它们的分类效果。这些算法在实际应用中有着广泛的应用,例如在西南交通大学的课程中,学生会进行这样的分析项目。
1.1 支持向量机(SVM)
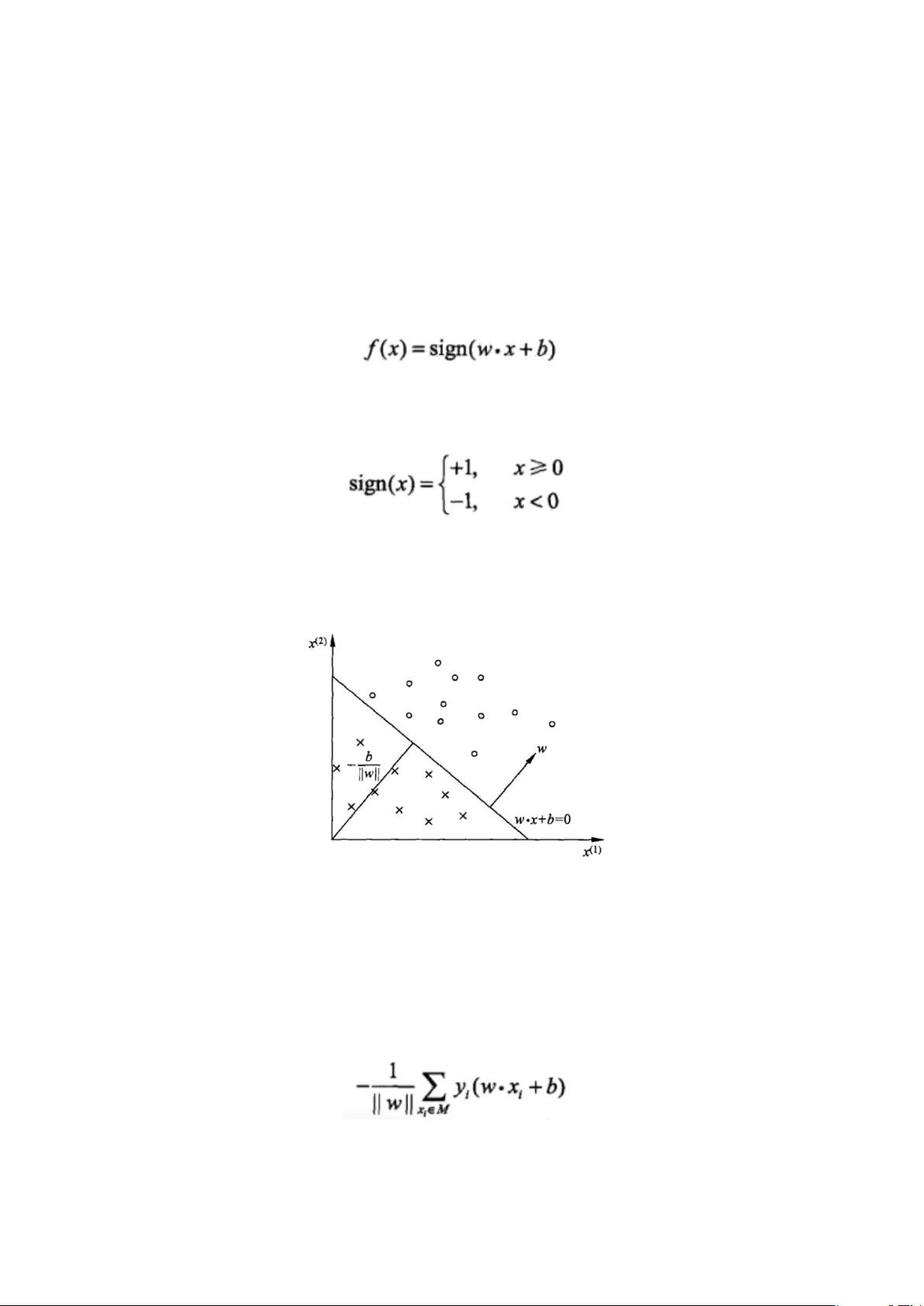
支持向量机是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,即找到一个超平面,使得不同类别的样本在这个超平面上的距离最大。SVM 的优势在于它能够处理高维数据,并且在小样本情况下有较好的泛化能力。感知机模型是SVM的前身,其核心是寻找一个能够将两类数据分开的最优超平面。
1.1.1 感知机模型
感知机是最简单的线性分类器,通过迭代更新权重向量以找到能够正确划分训练样本的决策边界。当数据线性可分时,感知机能够快速收敛,但在非线性数据上性能受限。
1.1.2 支持向量机
支持向量机通过引入核函数将原始低维数据映射到高维空间,使得原本难以区分的样本在新空间中变得可分。这种技术大大扩展了SVM的适用范围,使其能处理非线性问题。
1.2 决策树算法
决策树是一种基于树形结构进行决策的机器学习算法,通过一系列规则进行划分,直至达到预设的停止条件。决策树易于理解和解释,但在复杂问题上可能过拟合。
1.2.1 算法原理介绍分析
决策树通过学习数据的属性值,构建一棵树状模型,每个内部节点代表一个特征测试,每个分支代表一个特征值,而叶节点则代表一个类别决定。
1.2.2 训练思想
决策树的训练过程包括特征选择和树的剪枝,旨在找到一个既能准确分类又避免过拟合的树结构。
1.3 随机森林算法
随机森林是一种集成学习方法,通过构建多个决策树并取其平均结果来提高预测准确性。
1.3.1 算法原理介绍分析
随机森林在构建每棵树时引入随机性,如随机选取子集特征和样本,使得每棵树都有不同的偏差,但整体降低了方差。
1.3.2 算法特点
随机森林能够处理大量输入变量,减少过拟合风险,同时提供变量重要性评估。
1.3.3 随机森林推广
随机森林可以扩展到回归任务和多分类任务,且在大规模数据集上表现出色。
2. 数据集
本报告将使用以下四个经典数据集进行实验:
2.1 Iris 数据集
Iris数据集包含150个样本,每个样本有4个特征,分别属于3种鸢尾花类别。这是机器学习中常用的小型多类分类数据集。
2.2 breast_cancer 数据集
这个数据集涉及乳腺癌的诊断,包含30个特征和两个类别(恶性/良性),常用于二分类问题。
2.3 毒蘑菇数据集
这个数据集用于识别有毒和无毒的蘑菇,具有大量特征,是处理复杂分类问题的典型实例。
2.4 gigits 数据集
gigits数据集包含了手写数字的图像,通常用于图像识别和多分类问题。
通过对这些数据集应用不同的分类算法,我们可以对比它们在处理不同类型数据时的表现,从而得出哪种算法在特定场景下更为适用。这有助于我们在实际工作中选择最佳的模型,提高预测准确性和效率。



126 浏览量
2021-02-10 上传
2021-07-14 上传
131 浏览量
2021-07-14 上传
177 浏览量
2023-02-03 上传
2011-03-24 上传
129 浏览量
2021-07-14 上传
132 浏览量
116 浏览量
2016-05-08 上传
150 浏览量
187 浏览量
145 浏览量
148 浏览量
2008-12-27 上传
139 浏览量
资源评论











