






数据挖掘实验报告
姓 名:
学 号:
专 业:
一、数据源介绍
本实验的数据源是 Wine recognion data,即红酒识别数据。这些数据是对意大利同一
地区种植的,来自三个不同品种的葡萄酒进行化学分析的结果。数据集“wine.data”中,共
有 178 行,每一行代表一种红酒的样品信息。共有 14 列属性信息,第一列是样例的类标号
属性,所有样例分属于三类,用“1”、“2”、“3”表示。后面 13 列对应着所有样例的 13 个属
性信息值,分别为 Alcohol、Malic acid、Ash、Alcalinity of ash、Magnesium、Total phenols、
Flavanoids、Non$avanoid phenols、 Proanthocyanins、Color intensity、Hue、OD280/OD315
of diluted wines、Proline,即酒精、苹果酸、灰、灰分碱度、镁、总酚、黄酮、非类黄酮酚、
原花青素、颜色强度、色调、稀释葡萄酒的 OD280 / OD315、脯氨酸。在所有样例中,有
59 个属于第一类,有 71 个属于第二类,有 48 个属于第三类。
二、数据挖掘文件结构
补充:源数据文件需存放在 F 盘下,才能运行;或者修算法主函数中的调用目录路径。
对样例集的分类采用了逻辑回归分类算法(含正则化)和朴素贝叶斯分类算法,两种
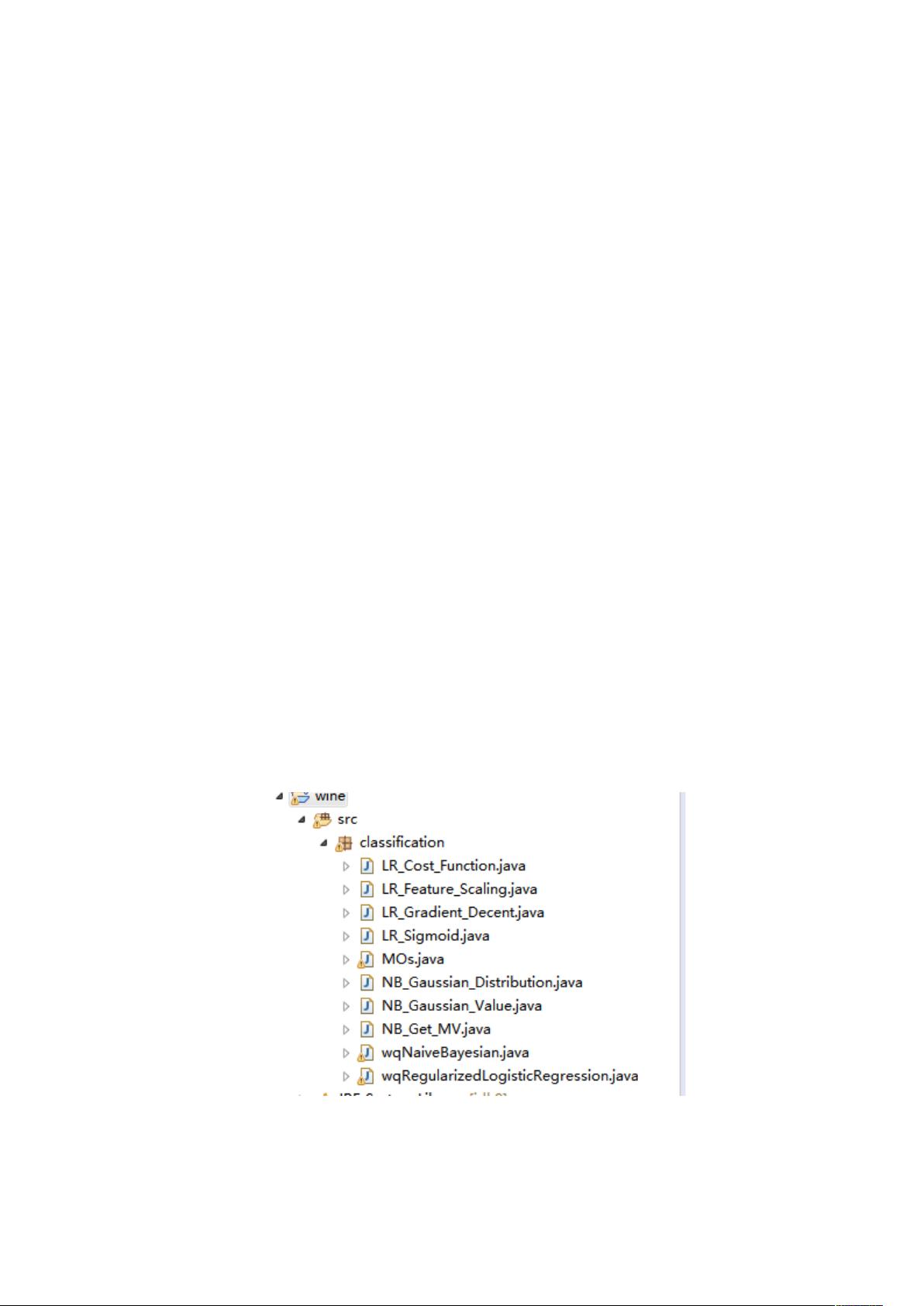
算法的文件结构图如下:
其中,wqRegularizedLogiscRegression.java 是逻辑回归分类算法的主程序,以 LR 开头
的 java 文件是该方法调用的类;wqNaiveBayesian.java 是朴素贝叶斯分类算法的主程序,以

NB 开头的 java 文件是该方法调用的类。
MOs.java 是集成一系列关于矩阵操作(Matrix Operaons)方法的类,因为 java 自身不
能进行矩阵运算。虽然网上有个叫 Jama.jar 的矩阵包,但其是对 Matrix 类定义的对象进行
操作,而在实际的算法编译中,我们需要对矩阵中某些元素进行数值意义上的运算、比较
等操作。对象和数值之间的互相转换不仅复杂,还影响阅读。所以,为了保持类型的统一
和提高可读性,定义了一个矩阵操作类。类成员函数包括矩阵与矩阵之间、矩阵与数值之
间基本的四则运算,矩阵元素上的指数运算、对数运算、幂运算,矩阵全体、行、列求和
计算矩阵相同元素个数,矩阵与矩阵行连接、列连接,矩阵转置,获取全 0 矩阵、全 1 矩
阵、矩阵,获取矩阵每行最大元素的索引,输出矩阵等。
三、逻辑回归分类算法
1、算法过程解释
数据处理:因为样例集数据没有缺失值,而且都是数值属性,所以没有对数据进行预
处理。
类标属性分离:将样例划分为两个矩阵——X:属性矩阵(添加全 1 列到到首列);
y:类标号矩阵。 为权值矩阵。用矩阵表示的好处是,借助于 MOs 类,实现向量化
(Vectorization)操作,即对样例同时进行相同操作,而不需要一个一个地计算。使用
矩阵计算来代替 for 循环,可以简化计算过程,提高效率。
假设函数(hypothesis function):在逻辑回归中,假设函数为: 。
激活函数(activation function):Sigmoid 函数有一个漂亮的 S 型曲线,可以
很好地反映样例属于一个类别的可能性,故选其作为激活函数: 。在
类 LR_Sigmoid 中构造此函数,如下:
public static double[][] s(double h[][]) {
double[][] s = MOs.dividedByOne(MOs.mPlus(MOs.e(MOs.mMulti(h,
-1)), 1));
return s;
}
代价函数(cost function):代价函数 反映预测值和实际值之间误差的大小,
也反映分类器分类效果的好坏,数学公式为:

,m 为样例个数。在类 LR_Cost_Funcon
中构造此函数,如下:
public static double cost(double theta[][], double X[][], double y[]
[], double lambda) {
double J = 0.0;
double m = X.length;// 这里 m=178
double[][] hypothesis = LR_Sigmoid.s(MOs.mMulti(X, theta));
double[][] J1 = MOs.mMulti(MOs.transpose(y),
MOs.log(hypothesis));
double[][] J2 = MOs.mMulti(MOs.transpose(MOs.mMinus(1, y)),
MOs.log(MOs.mMinus(1, hypothesis)));
double[][] J3 = MOs.mMulti(MOs.mPlus(J1, J2), -1 / m);//
J1、J2、J3 名为数组,其实都只有一个数
J = J3[0][0];
return J;
}
梯度下降法(Gradient Descent):梯度下降法是解决无约束优化问题时,最常
采用的方法之一。在最小化损失函数时,可以通过梯度下降法来一步步地迭代求解,进而
得 到 最 小 化 的 损 失 函 数 , 和 模 型 参 数 值 。 权 值 更 新 的 数 学 公 式 为 :
, 为学习率。在类 LR_Gradient_Descent 中构造此
函数,如下:
public static double[][] newTheta(double theta[][], double X[][],
double y[][], double lambda, double alpha) {
int m = X.length;
int n = theta.length;
double[][] newT = new double[n][1];
double[][] hypothesis = LR_Sigmoid.s(MOs.mMulti(X, theta));
double[][] grad = MOs.mMulti(MOs.transpose(X),
MOs.mMinus(hypothesis, y));
newT=MOs.mMinus(theta, MOs.mMulti(grad, alpha/m));
return newT;
}
特征缩放(feature scaling):虽然数据不需要预处理,但数据属性之间的数值跨
度太大的话,就会导致梯度下降走很多弯路,才能到达最优解目标。在此,进行特征缩放,
对每一列数据做线性归一变换,使所有数据值分布在[0,1]之间。线性归一化的数学公式为:
X=(X-MinValue)/(MaxValue-MinValue)。在类 LR_Feature_Scaling 中构造此函数,
如下:
public static double[][] fs(double x[][]) {

int lineNum = x.length;
int colNum = x[1].length;
double max = 0;
double min = 100;
for (int j = 1; j < colNum; j++) {
for (int i = 0; i < lineNum; i++) {
if (max < x[i][j])
max = x[i][j];
if (min > x[i][j])
min = x[i][j]; // 找出每列最大、最小值
}
for (int k = 0; k < lineNum; k++)
x[k][j] = (x[k][j] - min) / (max - min);
max = 0;
min = 100;
}
return x;
}
OneVsAll:逻辑回归分类算法实际上用于解决二分类问题,而数据集分为三类。不
过,对于多分类类问题,我们可以将其看做成二分类问题——保留其中的一类,剩下的所
有样例作为另一类。这样,就会产生三个分类器,每个分类器都会把一个类别的样例同其
他类别的样例分离开来。
交叉验证:为了减少误差,训练采用“5 折交叉验证”,即将 178 条数据分为 5 份大小
相似的互斥子集,每次选其中一份作为测试集,其他四份作为训练集。这样,就可以获得
5 组训练/测试集,从而进行 5 次训练和测试,最终返回的是这五个测试结果的均值。分为
5 份的原因是,若少于 5 次,训练次数太少,结果不具有代表性;若大于 5 次,由于训练
样本较少,测试集中每个样本占有的百分率较大,容易影响最终结果的精度。
分层采样:训练/测试集通过分层采样获得,使训练/测试集的划分尽可能保持数据分
布的一致性,避免因数据划分过程中引入额外的偏差而对最终结果产生影响。由于数据集
中样本是按类标号顺序排列,所以通过对样例在数据集中的序号与 5 相除所得的余数划分
子集(当然也可以用随机数法划分)。
预测类标号:在迭代得到权值矩阵后,将其分别应用到训练集和测试集上,选取最大
值对应的索引作为预测类标号,然后和实际类标号作比较,得出准确率;
调试参数得出结果:利用梯度下降法,通过不断比较结果,选取梯度下降较快的学习
率为 0.5,迭代次数为 45 次。最终得出精度、等结果。
2、算法核心代码
在此,仅展示主函数里的核心代码,为了简洁起见,删除了只用于输出结果的输

















