

Develop a NLP Model in Python &
Deploy It with Flask, Step byStep
Flask API, Document Classification,
SpamFilter
By far, we have developed many machine learning models, generated
numeric predictions on the testing data, and tested the results. And
we did everything offline. In reality, generating predictions is only
part of a machine learning project, although it is the most important
part in my opinion.
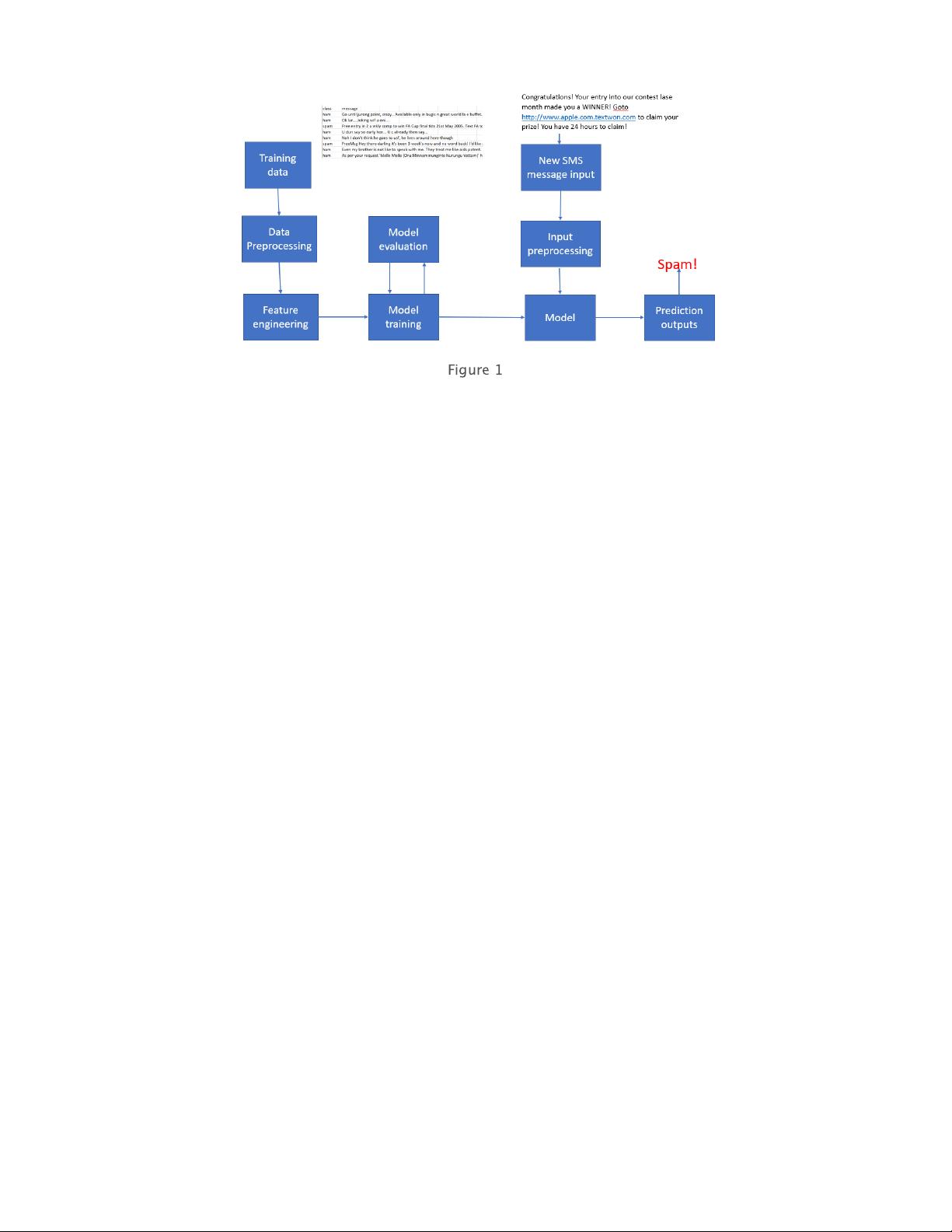
Considering a system using machine learning to detect spam SMS
text messages. Our ML systems workflow is like this: Train offline ->
Make model available as a service -> Predict online.
A classifier is trained offline with spam and non-spam messages.
The trained model is deployed as a service to serve users.
Susan Li
F
o
ll
ow
Dec 17, 2018
·
6 min read
•
•

剩余14页未读,继续阅读
资源评论


tox33
- 粉丝: 64
- 资源: 304









最新资源
- Linux Lab-linux
- ioGame-unity
- kdump-anaconda-addon-anaconda
- northstar-ai
- basic_framework-keil5安装教程
- 守月亮修行杂谈(2012年-2020年)
- 《Web开发实训》项目总结报告.doc
- 新年烟花LED效果,10分频,10khz变1khz,Multisim仿真
- vba自定清单.zip
- XamarinBleCodeBehind-main.zip
- mmexport1734999482214.png
- python-4.FBI树-虽然但是,不是那个.py
- IMG_20241220_204418_edit_64163654257396.png
- python-5.火星人-这题面,好抽象.py
- python-6.奖学金-语文给你多少?我数英给你…….py
- Screenshot_20241216_213107.jpg
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


