





深度学习笔记:优化方法总结(Momentum,AdaGrad,
RMSProp,Adam)
虽然局部极小值和鞍点会阻碍我们的训练,但病态曲率会减慢训练的速度,以
至于从事机器学习的人可能会认为搜索已经收敛到一个次优的极小值。让我们深入
了解什么是病态曲率。
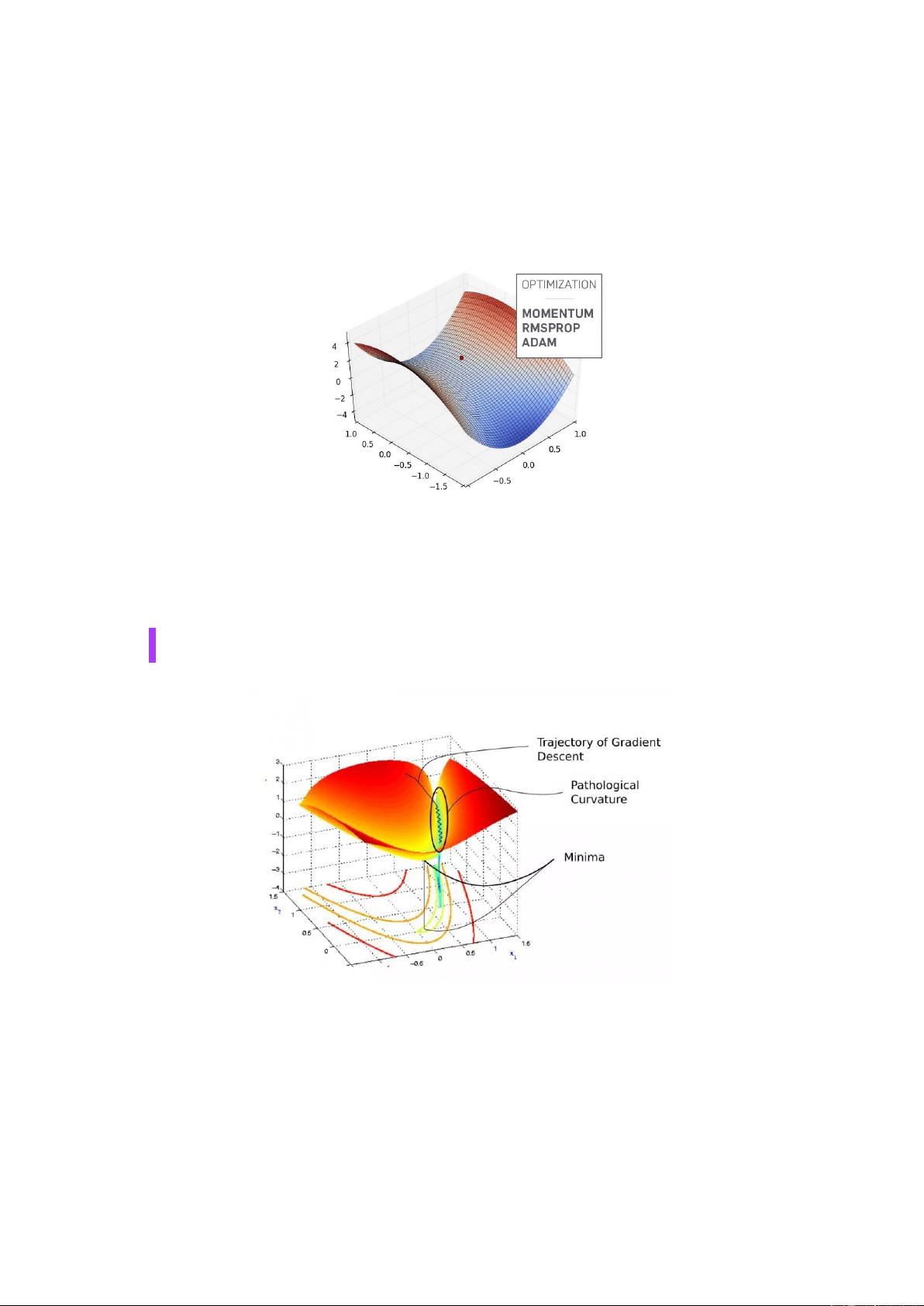
病态曲率
考虑以下损失曲线图。
**病态曲率**
如你所知,我们在进入一个以蓝色为标志的像沟一样的区域之前是随机的。这
些颜色实际上代表了在特定点上的损失函数的值,红色代表最高的值,蓝色代表最
低的值。
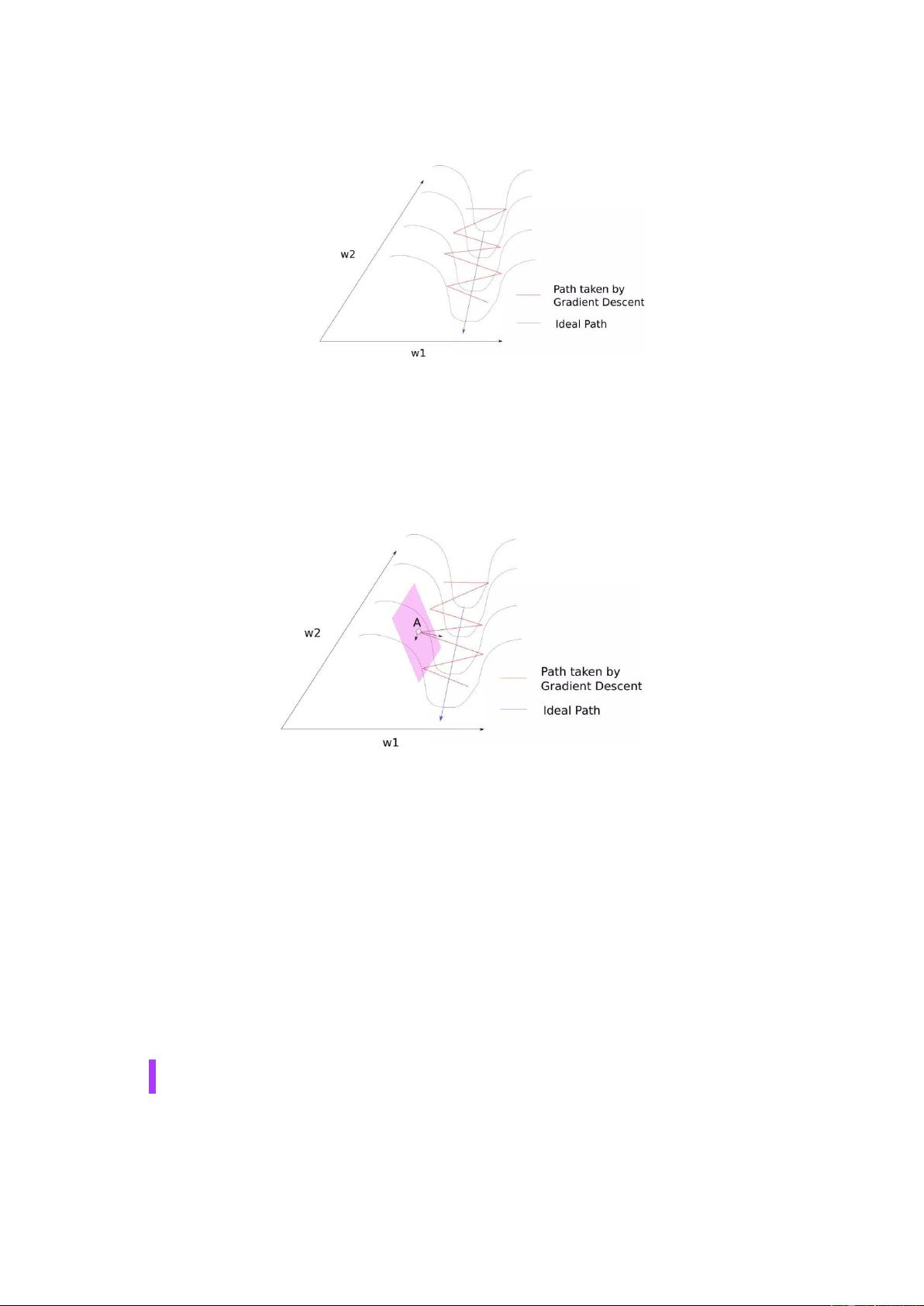
我们想要下降到最低点,因此,需要穿过峡谷。这个区域就是所谓的病态曲率。
剩余6页未读,继续阅读
资源评论

- #完美解决问题
- #运行顺畅
- #内容详尽
- #全网独家
- #注释完整

tox33
- 粉丝: 64









最新资源
- pandas实战项目源代码
- 汽车电子中ST品牌ECU、BMS、VCU的CAN BootLoader与XCP协议开发详解
- 华为企业架构设计方法及实例.pptx
- COMSOL中相场方法模拟裂缝多孔介质渗吸:守恒条件与水平集方法对比
- 智能硬件基于STM32F407ZGT6的智能空气净化器C++实现:集成PM2.5甲醛监测、APP远程控制及冷暖风一体功能设计
- Excel从入门到精通-72节课.zip
- FPGA串口读写驱动代码:支持多协议的波特率可调UART实现与优化
- 基于MATLAB与YALMIP+CPLEX的电动汽车有序充放电优化以最小化负荷峰谷差
- SIMATIC-S7-PLCSIM-V20 UPD1更新包2025.04-链接地址
- 机器人与计算机视觉领域的g2o库位姿图优化实践指南
- MCGS触摸屏与台达VFD-M变频器Modbus通讯实现及应用
- Microchip数字电源LLC控制方案详解:500W功率实现及其核心技术解析
- 三轴机械手台达PLC源码解析:坐标管理与运动控制关键技术
- 机械工程领域基于MATLAB的AR+MED滤波与谱分析在滚动轴承故障检测中的应用
- 智能驾驶领域中基于多项式与三角函数的泊车路径拟合及动态示意
- Abaqus UMAT子程序实现材料弹性模量随时间周期变化的结构响应仿真
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈
























