hadoop源码分析-HDFS部分


Hadoop
源代码分析(一) 总括
关键字: 分布式 云计算
经济不行啦,只好潜心研究技术。
的核心竞争技术是它的计算平台。 的大牛们用了下面 篇文章,介绍了它们的计算设施。
:
:
:!
"#:
$%&:&
很快,' 上就出现了一个类似的解决方案,目前它们都属于 ' 的 (& 项目,对应的分别是:
)*+
)(,
"#)("
$%&)(&
目前,基于类似思想的 -. 项目还很多,如 / 用于用户分析的 (。
(, 作为一个分布式文件系统,是所有这些项目的基础。分析好 (, ,有利于了解其他系统。由于 (& 的 (, 和
$%& 是同一个项目,我们就把他们放在一块,进行分析。
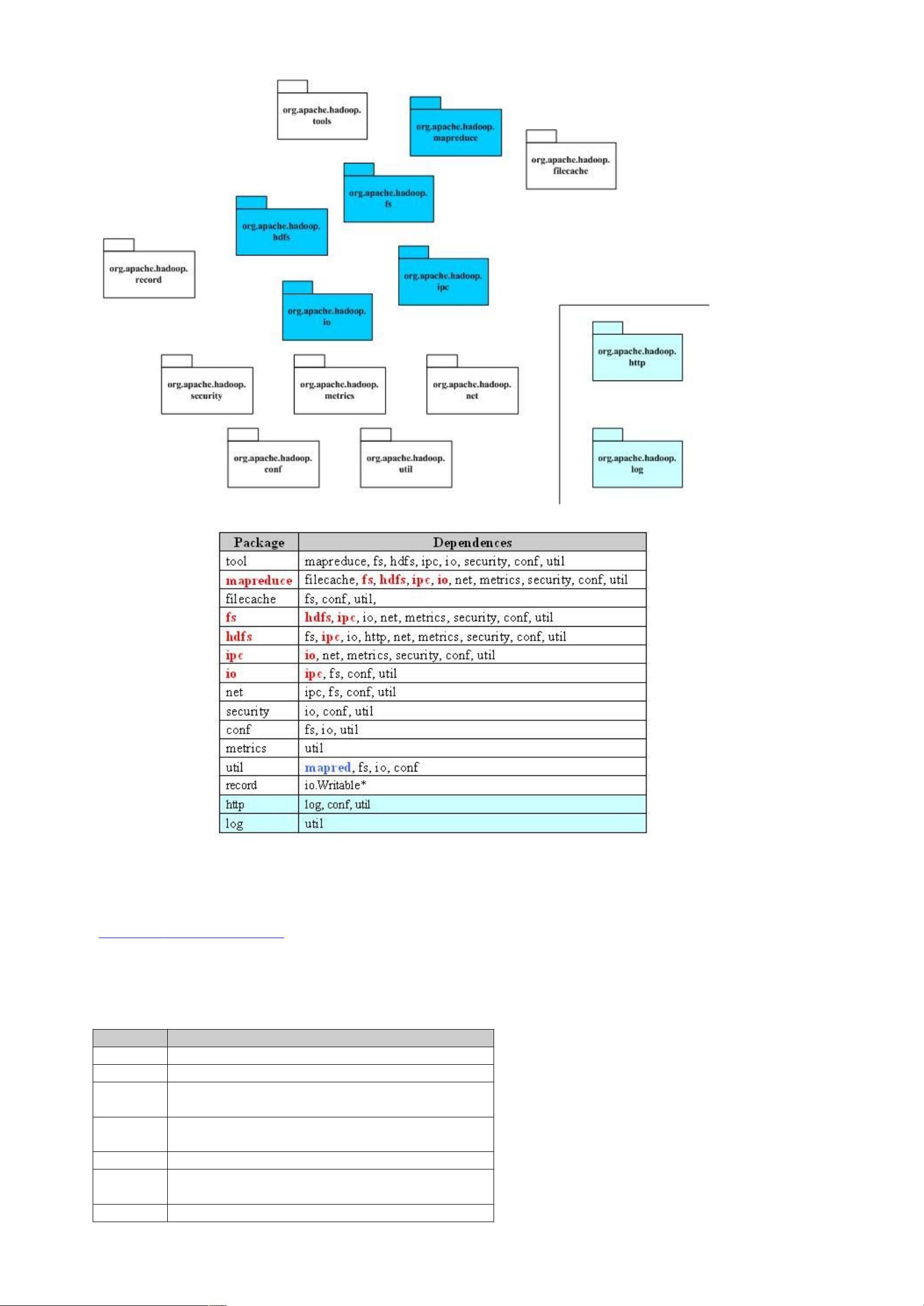
下图是 $%& 整个项目的顶层包图和他们的依赖关系。(& 包之间的依赖关系比较复杂,原因是 (, 提供了一
个分布式文件系统,该系统提供 '01,可以屏蔽本地文件系统和分布式文件系统,甚至象 '2. 3 这样的在线存储系统。
这就造成了分布式文件系统的实现,或者是分布式文件系统的底层的实现,依赖于某些貌似高层的功能。功能的相互引用,造
成了蜘蛛网型的依赖关系。一个典型的例子就是包 .!,.! 用于读取系统配置,它依赖于 !,主要是读取配置文件的时候,
需要使用文件系统,而部分的文件系统的功能,在包 ! 中被抽象了。
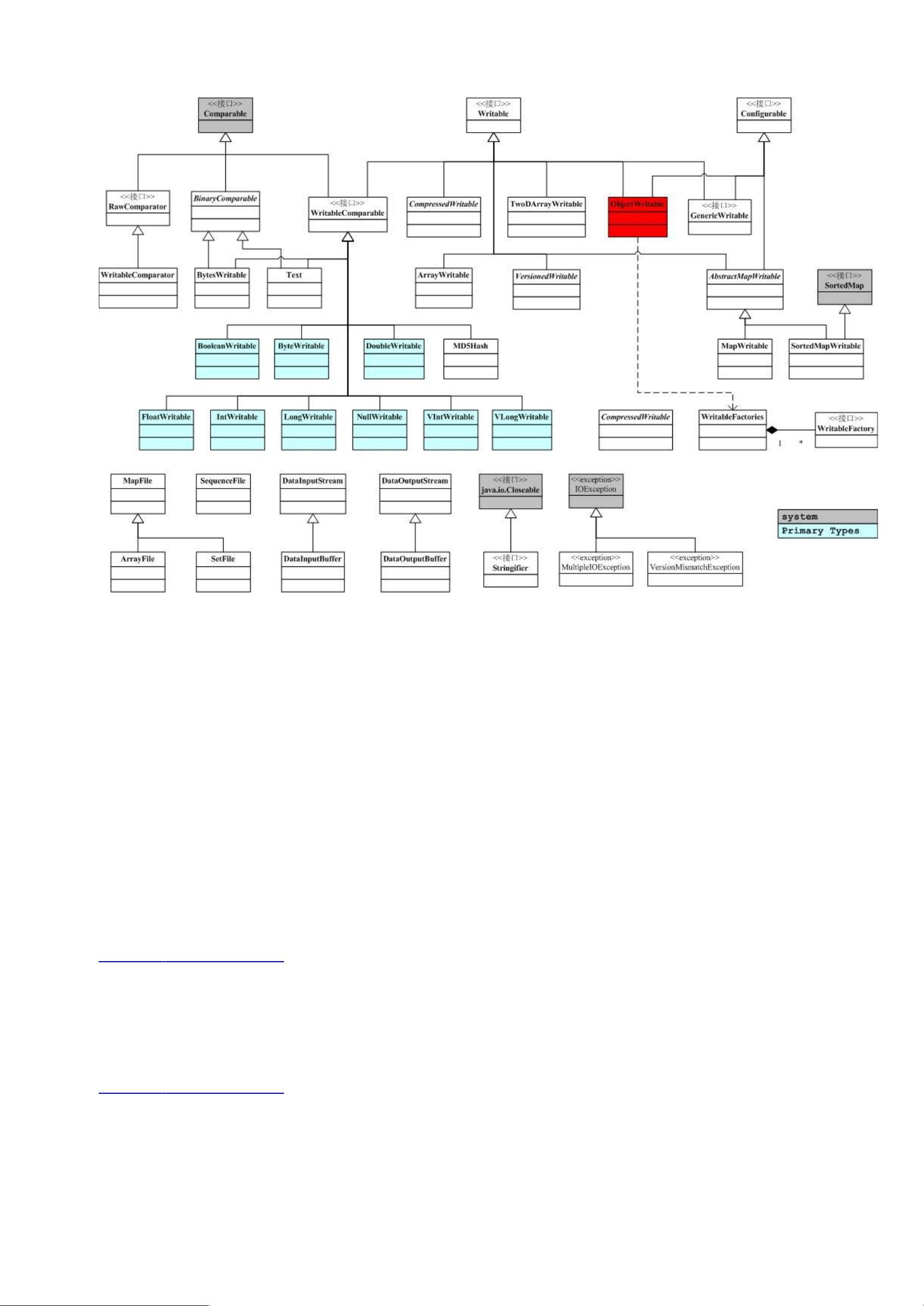
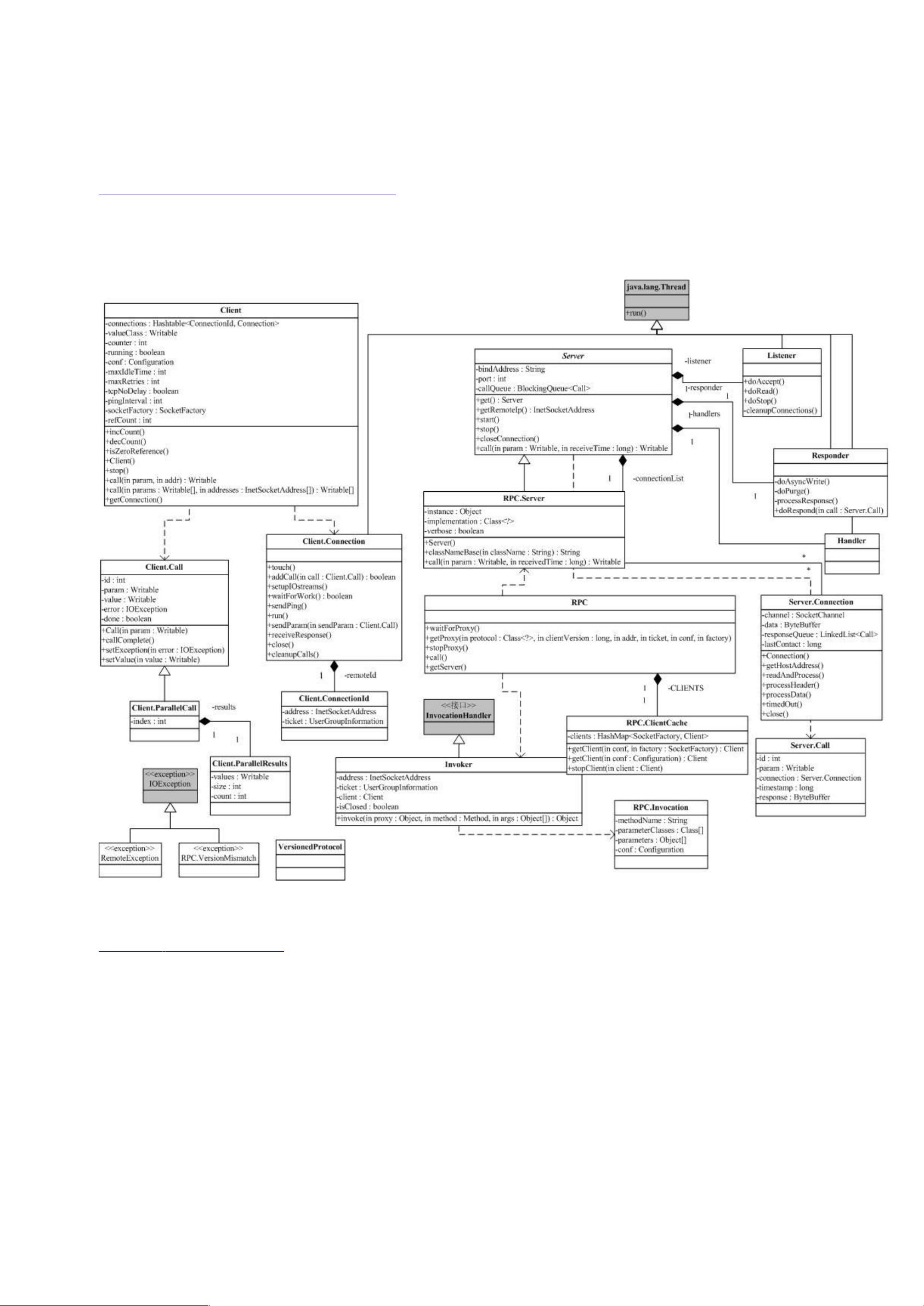
(& 的关键部分集中于图中蓝色部分,这也是我们考察的重点。

剩余63页未读,继续阅读
资源评论

 Choc3222013-10-24很好的资料,关于HDFS的讲解的
Choc3222013-10-24很好的资料,关于HDFS的讲解的











