
JOURNAL OF L
A
T
E
X CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1
Complex Knowledge Base Question Answering:
A Survey
Yunshi Lan*, Gaole He*, Jinhao Jiang, Jing Jiang, Wayne Xin Zhao Member, IEEE,
and Ji-Rong Wen Senior Member, IEEE,
Abstract— Knowledge base question answering (KBQA) aims to answer a question over a knowledge base (KB). Early studies mainly
focused on answering simple questions over KBs and achieved great success. However, their performance on complex questions is
still far from satisfactory. Therefore, in recent years, researchers propose a large number of novel methods, which looked into the
challenges of answering complex questions. In this survey, we review recent advances on KBQA with the focus on solving complex
questions, which usually contain multiple subjects, express compound relations, or involve numerical operations. In detail, we begin
with introducing the complex KBQA task and relevant background. Then, we describe benchmark datasets for complex KBQA task and
introduce the construction process of these datasets. Next, we present two mainstream categories of methods for complex KBQA,
namely semantic parsing-based (SP-based) methods and information retrieval-based (IR-based) methods. Specifically, we illustrate
their procedures with flow designs and discuss their major differences and similarities. After that, we summarize the challenges that
these two categories of methods encounter when answering complex questions, and explicate advanced solutions and techniques
used in existing work. Finally, we conclude and discuss several promising directions related to complex KBQA for future research.
Index Terms—Knowledge base question answering, knowledge base, question answering, natural language processing, survey.
F
1 INTRODUCTION
K
nowledge base (KB) is a structured database that con-
tains a collection of facts (alias triples) in the form (sub-
ject, relation, object). Large-scale KBs, such as Freebase [1],
DBPedia [2], Wikidata [3] and YAGO [4], have been con-
structed to serve many downstream tasks. Among them,
knowledge base question answering (KBQA) is a task that
aims to answer natural language questions with KBs acting
as its knowledge source. Nowadays, KBQA has attracted
intensive attention from researchers as it plays an important
role in many intelligent applications. For example, Amazon
Alexa, Apple Siri, and Microsoft Cortana are integrated
with the function of answering factoid questions from users.
Chatbots such as Microsoft Xiaoice and Zo have also demon-
strated a high degree of conversational capability, where
factoid question answering frequently occurs [5], [6].
Early work on KBQA focused on answering a simple
question, where only a single fact is involved. For example,
“Who was the nominee of The Jeff Probst Show?” is a simple
question which includes the subject “The Jeff Probst Show”,
the relation “nominee” and queries about the object entity
“Jeff Probst” of fact “(The Jeff Probst Show, nominee, Jeff Probst)”
• * Y. Lan and G. He contribute equally to this work.
• This work is done when Y. Lan was with School of Computing and
Information System, Singapore Management University. E-mail: ys-
lan.2015@phdcs.smu.edu.sg
• Jing Jiang is with School of Computing and Information System, Singa-
pore Management University. E-mail: jingjiang@smu.edu.sg.
• G.He is with the School of Information, Renmin University of China, and
Beijing Key Laboratory of Big Data Management and Analysis Methods.
E-mail: hegaole@ruc.edu.cn
• W.X. Zhao (corresponding author) , Jinhao Jiang and J. Wen are with
Gaoling School of Artificial Intelligence, Renmin University of China, and
Beijing Key Laboratory of Big Data Management and Analysis Methods.
E-mail: batmanfly@gmail.com.
Manuscript revised xxx.
The Jeff
Probst Show
TV
producer
spouse
is_a
married_date
nominee
Jeff Probst
Shelley
Wright
1996
Lisa Ann
Russell
married_date
2011
spouse
is_a
Talk show
Survivor
host
CBS Television
Distribution
distributed by
m ulti-hop num erical
constrained
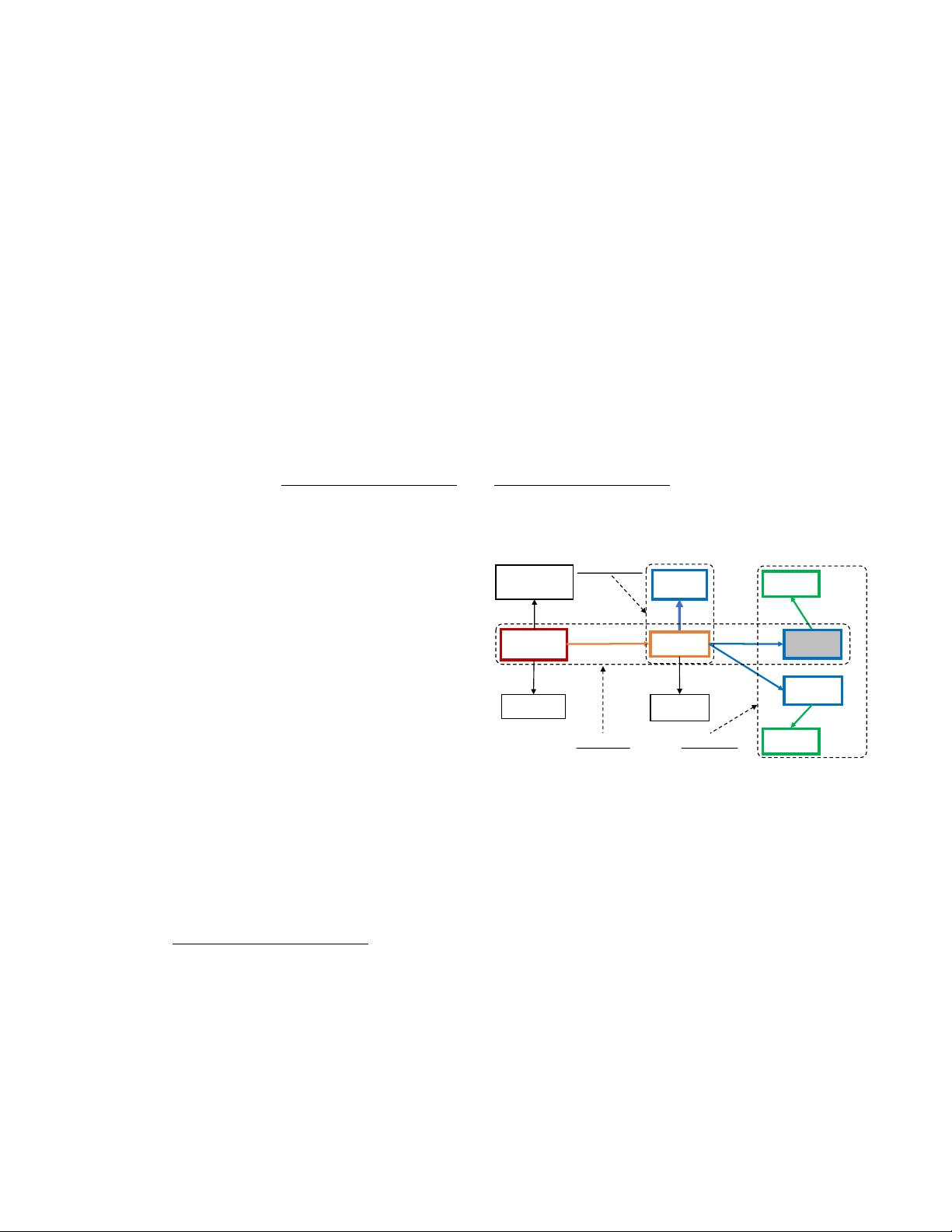
FIGURE 1: An example of complex KBQA for the question
“Who is the first wife of TV producer that was nominated for The
Jeff Probst Show?”. We present the related KB subgraph for
this question. The ground truth path heading to the answer
is annotated with colored borders. The topic entity and the
answer entity are shown in the bold font and shaded box
respectively. “multi-hop” reasoning, “constrained” relations
and “numerical” operation are highlighted in black dotted
box. We use different colors to indicate different reasoning
hops to reach each entity from the topic entity.
in KBs. Similarly, simple question “Who is the wife of Jeff
Probst?” can be answered using just the facts “(Jeff Probst,
spouse, Shelley Wright)” and “(Jeff Probst, spouse, Lisa Ann
Russell)”. It is not trivial to retrieve the correct entity from
the large-scale KBs, which consists of millions or even bil-
lions of facts. Therefore, researchers have spent much effort
in proposing different models to answer simple questions
over KBs [7], [8], [9], [10], [11].
Recently, researchers started paying more attention to
arXiv:2108.06688v1 [cs.CL] 15 Aug 2021

剩余19页未读,继续阅读
资源评论


syp_net
- 粉丝: 158
- 资源: 1187









最新资源
- 工具变量-商标实施DID数据集.xlsx
- 湖北师范大学计算机与信息工程学院综合实训3学期实训实验报告,高校计算机课程中的博客系统设计与实现在信息系统领域的应用实例
- MATLAB电力系统故障分析,仿真加报告
- PMP项目管理考试讲义-PMP教材
- 完结24周Java高级工程师体系课(附源码+电子书)
- 光伏MPPT仿真-灰狼+扰动观察法
- 毕业设计-基于深度学习的特征值识别的社交媒体谣言分析源码+全部数据
- 同步机无感 STM32低成本MD500E永磁同步控制方案,pmsm,高性价比变频器参考方案 md500e三电阻采样,移植了500e的永磁同步电机控制的关键代码,实现了精简版500e,默认电位器调速,用
- 分数阶PI^λ控制器,CLLC双向变器simulink仿真,模型与整数阶pi进行比较,到达稳态时间为0.01s以内 本仿真λ阶次选取为0.9 matlab版本2020b
- 项目管理专业(PMP)认证考试要点总结
- (顶刊复现)基于优化模型的配电网可靠性评估matlab代码 参考文献IEEE TRANSACTIONS ON SMART GRIDReliability Assessment for Distrib
- 机械设计16T冲床自动送料sw18全套技术资料100%好用.zip
- 机械设计4L斗式提升sw16可编辑全套技术资料100%好用.zip
- 机械设计120km速度级B型地铁拖车转向架sw14可编辑全套技术资料100%好用.zip
- 集团IT治理体系-构建高效三级IT管控架构与规则详解
- 无传感器FOC控制方案,磁链观测器,M0 内核单片机均可移植使用,低速准闭环启动,堵转保持力矩,持续正向出力,提供源码,原理图
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


