实现图的遍历算法 深度优先遍历

实现图的遍历算法
1. 需求分析
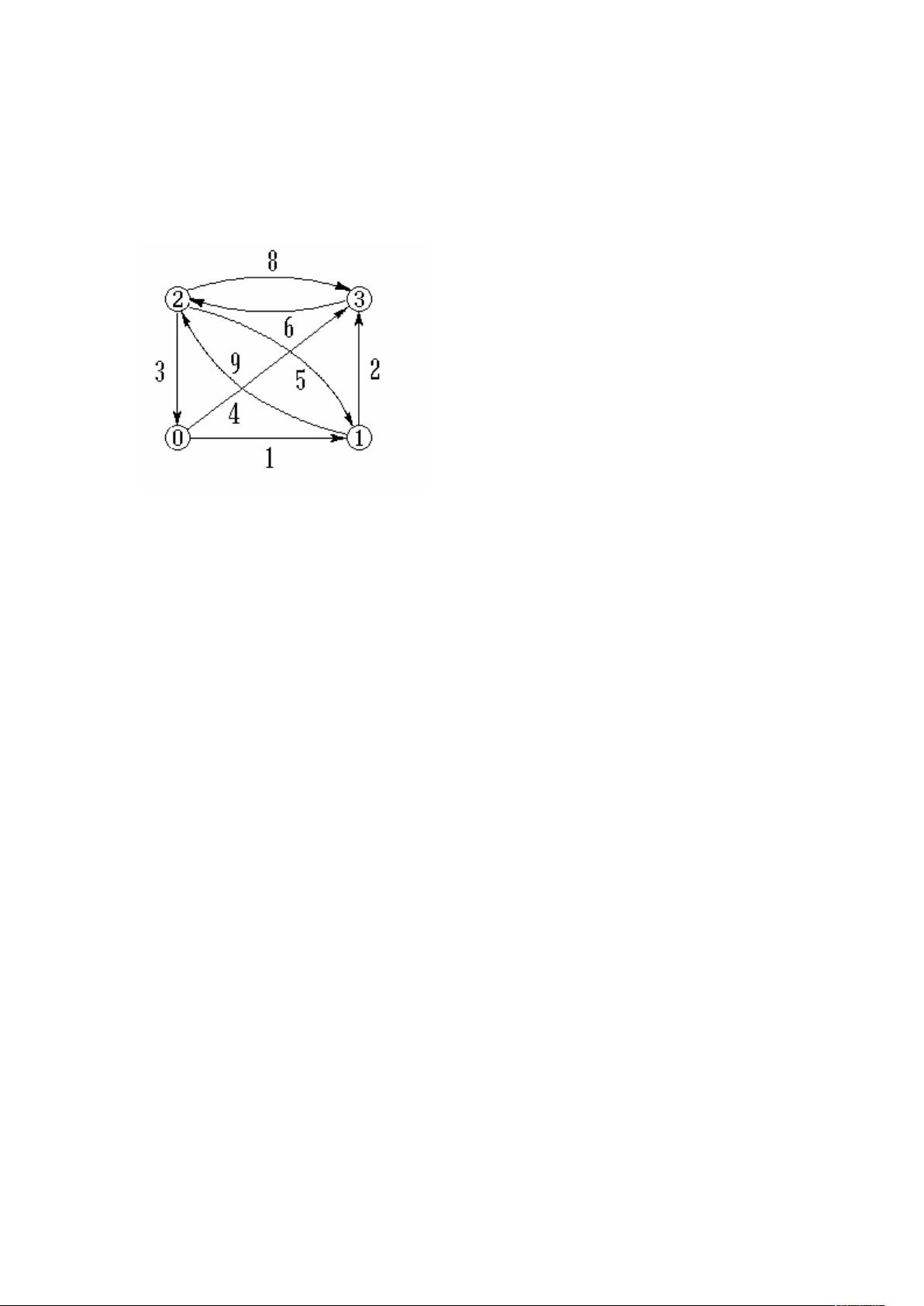
对于下图 G,编写一个程序输出从顶点 0 开始的深度优先遍历序列(非递归算法)和广度
优先遍历序列(非递归算法)。
2. 系统设计
1.用到的抽象数据类型的定义
图的抽象数据类型定义:
ADT Graph{
数据对象 V:V 是具有相同特性的数据元素的集合,称为顶点集
数据关系 R:
R={VR}
VR={<v,w>|v,w∈V 且 P(v,w),<v,w>表示从 v 到 w 的弧,
谓词 P(v,w)定义了弧<v,w>的意义或信息}
基本操作 P:
CreatGraph(&G,V,VR)
初始条件:V 是图的顶点集,VR 是图中弧的集合
操作结果:按 V 和 VR 的定义构造图 G
DestroyGraph(&G)
初始条件:图 G 存在
操作结果:销毁图 G
InsertVex(&G,v)
初始条件:图 G 存在,v 和图中顶点有相同特征
操作结果:在图 G 中增添新顶点 v
……
InsertArc(&G,v,w)
初始条件:图 G 存在,v 和 w 是 G 中两个顶点
操作结果:在 G 中增添弧<v,w>,若 G 是无向的则还增添对称弧<w,v>
……
DFSTraverse(G,Visit())
初始条件:图 G 存在,Visit 是顶点的应用函数
操作结果:对图进行深度优先遍历,在遍历过程中对每个顶点调用函数 Visit 一次且仅一次。
一旦 Visit()失败,则操作失败

剩余10页未读,继续阅读
资源评论

 pym3332014-04-19doc文档中讲了许多东西。非常好
pym3332014-04-19doc文档中讲了许多东西。非常好- hannaiming2012-12-06这个文件很详细,很好
 bear_wp2011-09-25doc文档中讲了许多东西。不过如果是一cpp的形式给出的话会更好的。
bear_wp2011-09-25doc文档中讲了许多东西。不过如果是一cpp的形式给出的话会更好的。











