TOD-Net An end-to-end transformer-based object detection network
43 浏览量
2023-11-25
15:40:36
上传
评论
收藏 6.45MB PDF 举报


Computers and Electrical Engineering 108 (2023) 108695
Available online 8 April 2023
0045-7906/© 2023 Elsevier Ltd. All rights reserved.
TOD-Net: An end-to-end transformer-based object
detection network
Museboyina Sirisha
a
,
*
, S.V. Sudha
b
a
School of Computer Science and Engineering, VIT-AP University, Amaravathi, Andhra Pradesh 522237, India
b
Professor and Dean, School of Computer Science and Engineering, VIT-AP University, Amaravathi, Andhra Pradesh 522237, India
ARTICLE INFO
Editor E. Cabal-Yepez
Keywords:
Object detection
Network learning
Feature representation
Transformer
Predictor module
Feature analysis
Local features
Scaling
Semantic analysis
Network layer
ABSTRACT
Various object detection approaches using a learning model intends to learn the semantic and
multi-scaling information to attain superior object saliency. This research employs a transformer-
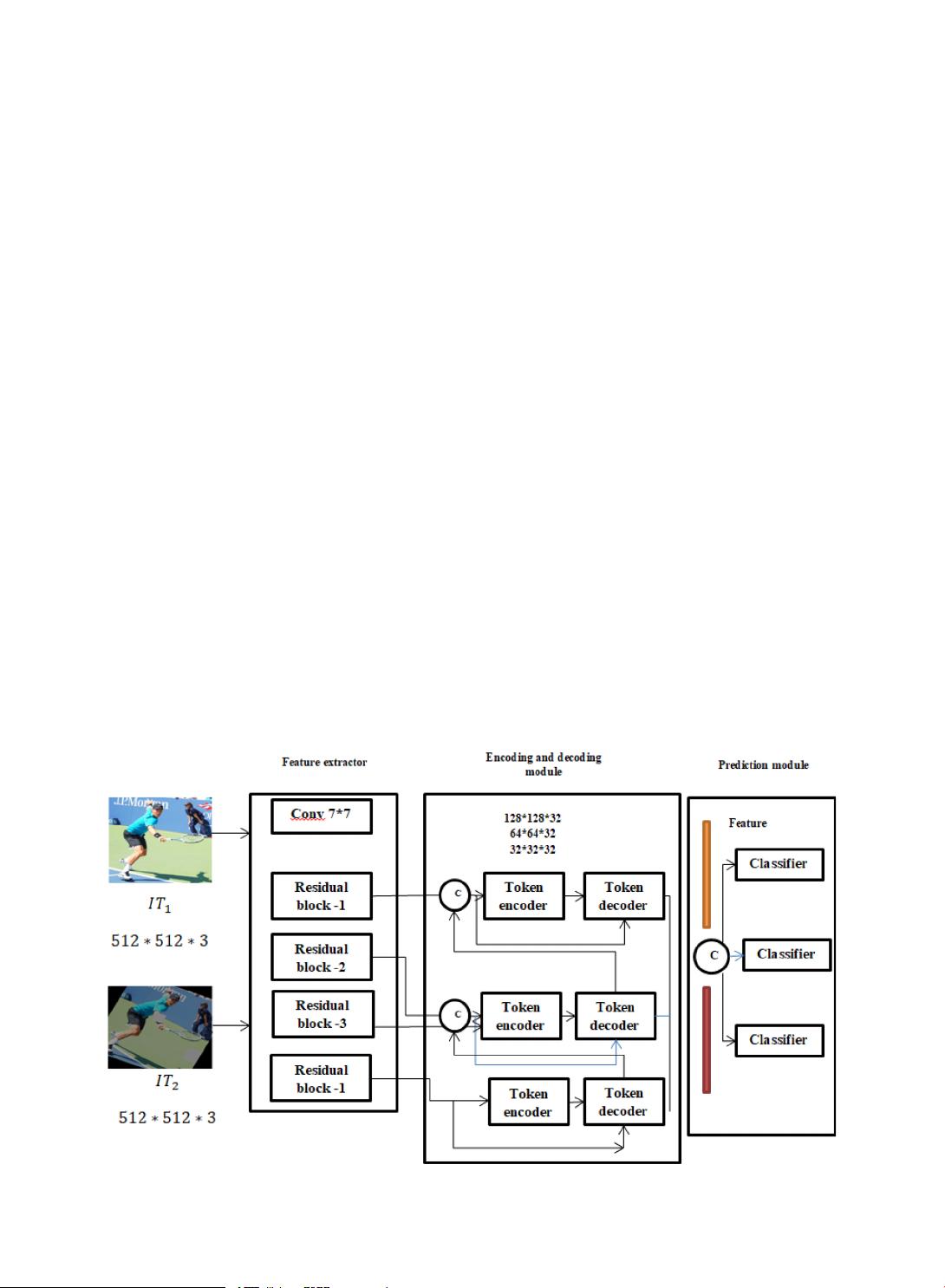
based network framework for object detection (TOD − Net) for object detection. It is composed of
encoders, decoders, and transformer and predictor module. The predictor model bridges the
connectivity between the encoder and the transformer module and offers better insight into the
transformer module’s local measures. Here, feature extraction is performed to measure the local
features and establishes dense modeling by analyzing local features. The model gives broader
knowledge of local and global features. Python programming was used to experiment with the MS
COCO dataset (Microsoft Common Objects in Context) where the experimentation gives better
results over existing models. In contrast to existing methods, the proposed method achieves
68.7% precision and 4% accuracy. The proposed model outperforms different prevailing ap-
proaches and establishes a better trade-off.
1. Introduction
Object detection remains one of the biggest challenges in computer vision. Object detection methods are broadly utilized in
different regions, like detecting faces, tracking objects [1], detecting pedestrians, autonomous driving, and medical imaging based on
deep learning.[1–3] The rapid development in the latest days is achieved using CNNs(Convolutional Neural networks), which started
from Alexnet [4], making considerable gains in detecting objects. A pre-trained backbone network requires a large volume of data like
ImageNet and a signicant processing time, broadly utilized to extract features [5] effectively. MobileNetV2 [6] utilizes the linear
bottleneck and the inverted residuals, making it suitable to be a lightweight backbone network in many object detection models. The
process of depth-wise separable convolution was applied to the inception in Xception [7], an approach that separates channels from
spaces in a network. In addition, the point-wise convolution and the channels are used by ShufeNet [8]. ResNet [9] improved
performance by using residual learning to construct a deeper neural network, while ResNeXt [10] introduced grouped convolutions
based on ResNet to enhance accuracy.ResNeXt achieves relative performance by maximizing the cardinality with the help of grouped
convolutions based on the ResNet. The method of image pyramid [11] uses the multi-scale map for the features to identify the
multi-scale objects from the higher layers to the lower layers at the increased cost of the memory space and computational load. The
study helps to integrate the efcient mapping of features for the higher and lower layers, which is performed actively to solve this
problem.
* Corresponding author.
E-mail address: musesirisha@gmail.com (M. Sirisha).
Contents lists available at ScienceDirect
Computers and Electrical Engineering
journal homepage: www.elsevier.com/locate/compeleceng
https://doi.org/10.1016/j.compeleceng.2023.108695
Received 25 November 2022; Received in revised form 20 March 2023; Accepted 22 March 2023

剩余11页未读,继续阅读
资源评论













