Learning Deep Features for Discriminative Localization
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba
Computer Science and Artificial Intelligence Laboratory, MIT
{bzhou,khosla,agata,oliva,torralba}@csail.mit.edu
Abstract
In this work, we revisit the global average pooling layer
proposed in [13], and shed light on how it explicitly enables
the convolutional neural network to have remarkable local-
ization ability despite being trained on image-level labels.
While this technique was previously proposed as a means
for regularizing training, we find that it actually builds a
generic localizable deep representation that can be applied
to a variety of tasks. Despite the apparent simplicity of
global average pooling, we are able to achieve 37.1% top-5
error for object localization on ILSVRC 2014, which is re-
markably close to the 34.2% top-5 error achieved by a fully
supervised CNN approach. We demonstrate that our net-
work is able to localize the discriminative image regions on
a variety of tasks despite not being trained for them.
1. Introduction
Recent work by Zhou et al [33] has shown that the con-
volutional units of various layers of convolutional neural
networks (CNNs) actually behave as object detectors de-
spite no supervision on the location of the object was pro-
vided. Despite having this remarkable ability to localize
objects in the convolutional layers, this ability is lost when
fully-connected layers are used for classification. Recently
some popular fully-convolutional neural networks such as
the Network in Network (NIN) [13] and GoogLeNet [24]
have been proposed to avoid the use of fully-connected lay-
ers to minimize the number of parameters while maintain-
ing high performance.
In order to achieve this, [13] uses global average pool-
ing which acts as a structural regularizer, preventing over-
fitting during training. In our experiments, we found that
the advantages of this global average pooling layer extend
beyond simply acting as a regularizer - In fact, with a little
tweaking, the network can retain its remarkable localization
ability until the final layer. This tweaking allows identifying
easily the discriminative image regions in a single forward-
pass for a wide variety of tasks, even those that the network
was not originally trained for. As shown in Figure 1(a), a
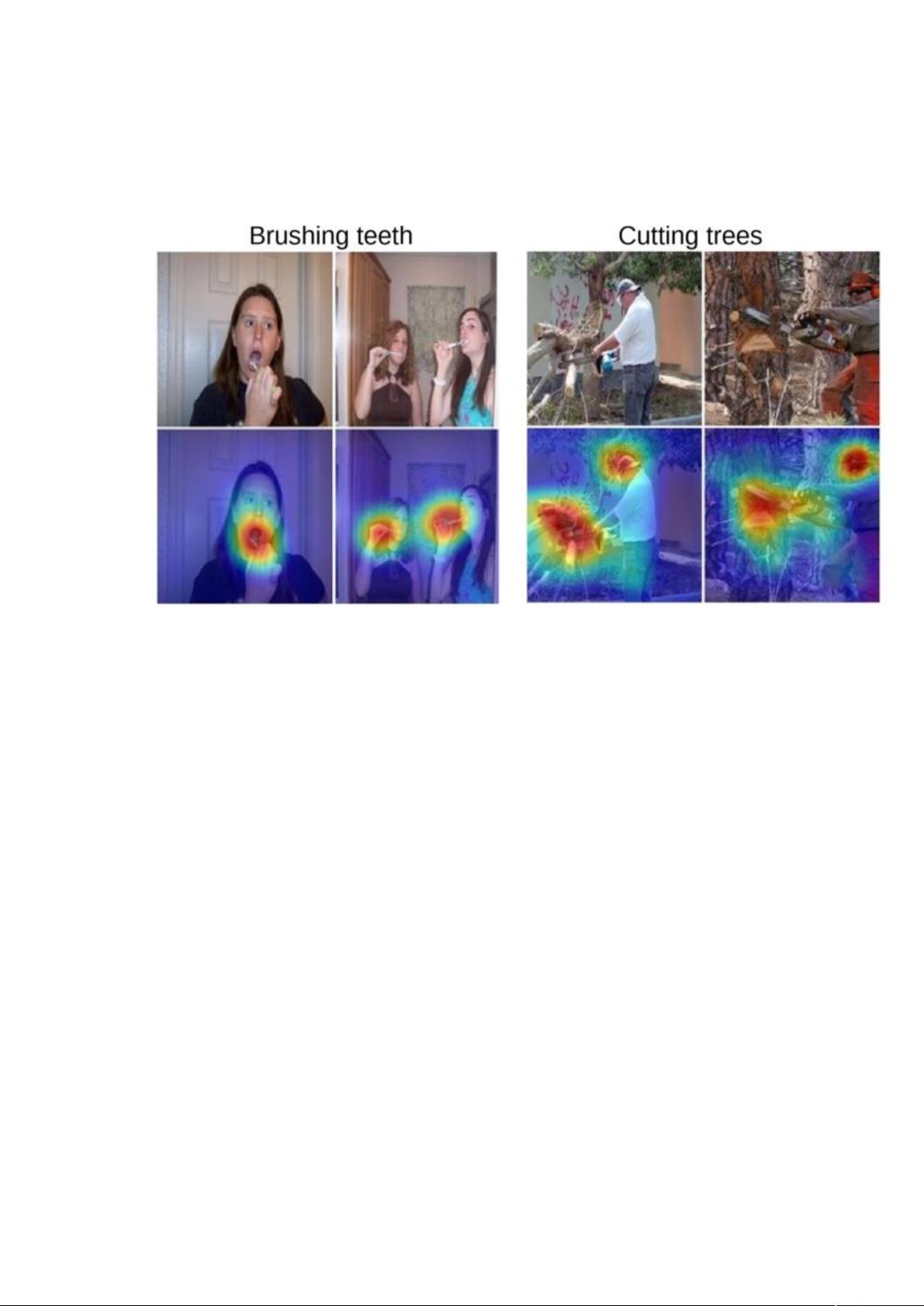
Brushing teeth Cutting trees
Figure 1. A simple modification of the global average pool-
ing layer combined with our class activation mapping (CAM)
technique allows the classification-trained CNN to both classify
the image and localize class-specific image regions in a single
forward-pass e.g., the toothbrush for brushing teeth and the chain-
saw for cutting trees.
CNN trained on object categorization is successfully able to
localize the discriminative regions for action classification
as the objects that the humans are interacting with rather
than the humans themselves.
Despite the apparent simplicity of our approach, for the
weakly supervised object localization on ILSVRC bench-
mark [20], our best network achieves 37.1% top-5 test er-
ror, which is rather close to the 34.2% top-5 test error
achieved by fully supervised AlexNet [10]. Furthermore,
we demonstrate that the localizability of the deep features in
our approach can be easily transferred to other recognition
datasets for generic classification, localization, and concept
discovery.
1
.
1.1. Related Work
Convolutional Neural Networks (CNNs) have led to im-
pressive performance on a variety of visual recognition
tasks [10, 34, 8]. Recent work has shown that despite being
trained on image-level labels, CNNs have the remarkable
ability to localize objects [1, 16, 2, 15]. In this work, we
show that, using the right architecture, we can generalize
this ability beyond just localizing objects, to start identi-
fying exactly which regions of an image are being used for
1
Our models are available at: http://cnnlocalization.csail.mit.edu
1
arXiv:1512.04150v1 [cs.CV] 14 Dec 2015