

LETTER Communicated by Yann Le Cun
A Fast Learning Algorithm for Deep Belief Nets
Geoffrey E. Hinton
hinton@cs.toronto.edu
Simon Osindero
osindero@cs.toronto.edu
Department of Computer Science, University of Toronto, Toronto, Canada M5S 3G4
Yee-Whye Teh
tehyw@comp.nus.edu.sg
Department of Computer Science, National University of Singapore,
Singapore 117543
We show how to use “complementary priors” to eliminate the explaining-
away effects that make inference difficult in densely connected belief nets
that have many hidden layers. Using complementary priors, we derive a
fast, greedy algorithm that can learn deep, directed belief networks one
layer at a time, provided the top two layers form an undirected associa-
tive memory. The fast, greedy algorithm is used to initialize a slower
learning procedure that fine-tunes the weights using a contrastive ver-
sion of the wake-sleep algorithm. After fine-tuning, a network with three
hidden layers forms a very good generative model of the joint distribu-
tion of handwritten digit images and their labels. This generative model
gives better digit classification than the best discriminative learning al-
gorithms. The low-dimensional manifolds on which the digits lie are
modeled by long ravines in the free-energy landscape of the top-level
associative memory, and it is easy to explore these ravines by using the
directed connections to display what the associative memory has in mind.
1 Introduction
Learning is difficult in densely connected, directed belief nets that have
many hidden layers because it is difficult to infer the conditional distribu-
tion of the hidden activities when given a data vector. Variational methods
use simple approximations to the true conditional distribution, but the ap-
proximations may be poor, especially at the deepest hidden layer, where
the prior assumes independence. Also, variational learning still requires all
of the parameters to be learned together and this makes the learning time
scale poorly as the number of parameters increases.
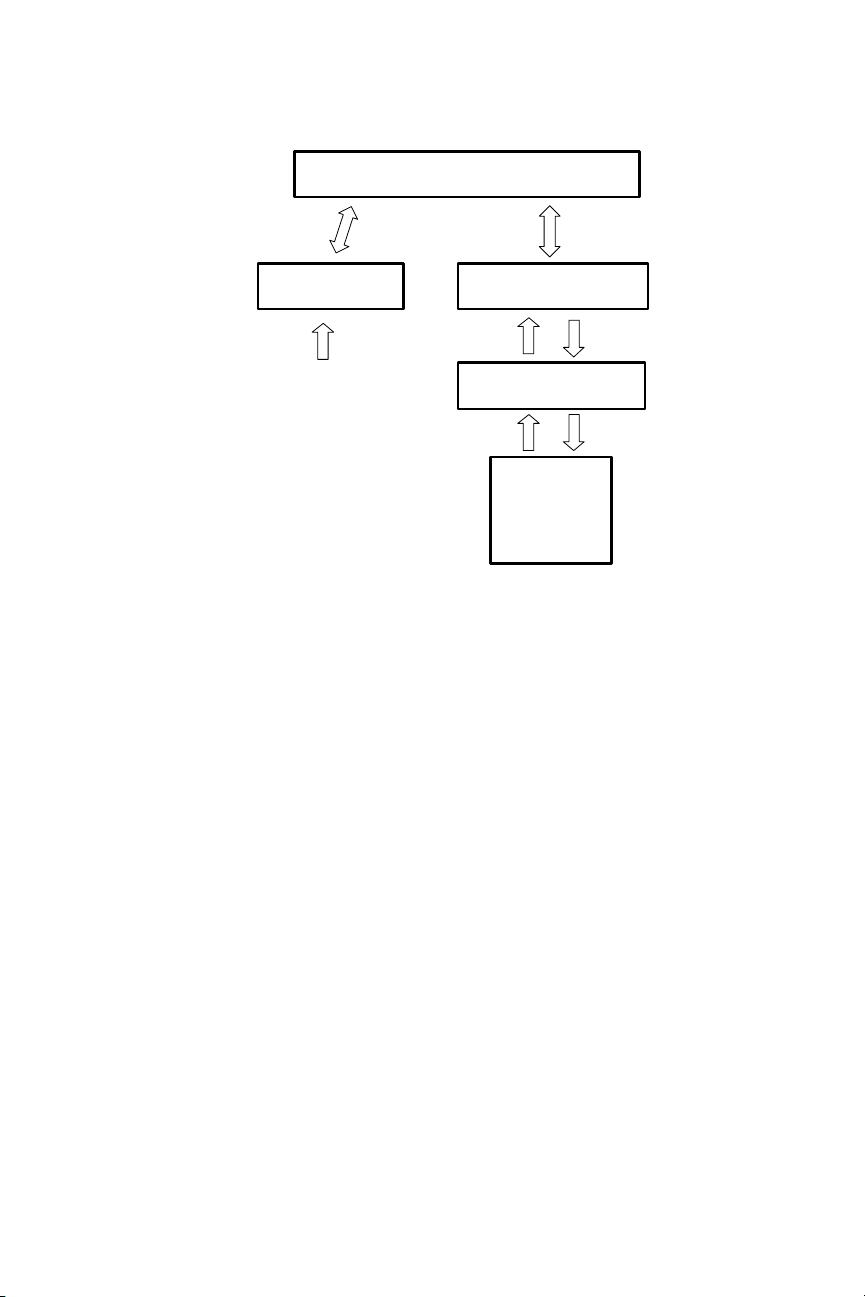
We describe a model in which the top two hidden layers form an undi-
rected associative memory (see Figure 1) and the remaining hidden layers
Neural Computation 18, 1527–1554 (2006)
C
2006 Massachusetts Institute of Technology


剩余27页未读,继续阅读
资源评论

 redlz25002023-03-28可以,恰到好处地有用
redlz25002023-03-28可以,恰到好处地有用












