

HIVE 代码分析
梁堃
2011-12-02
目录
背景....................................................................................................................................2
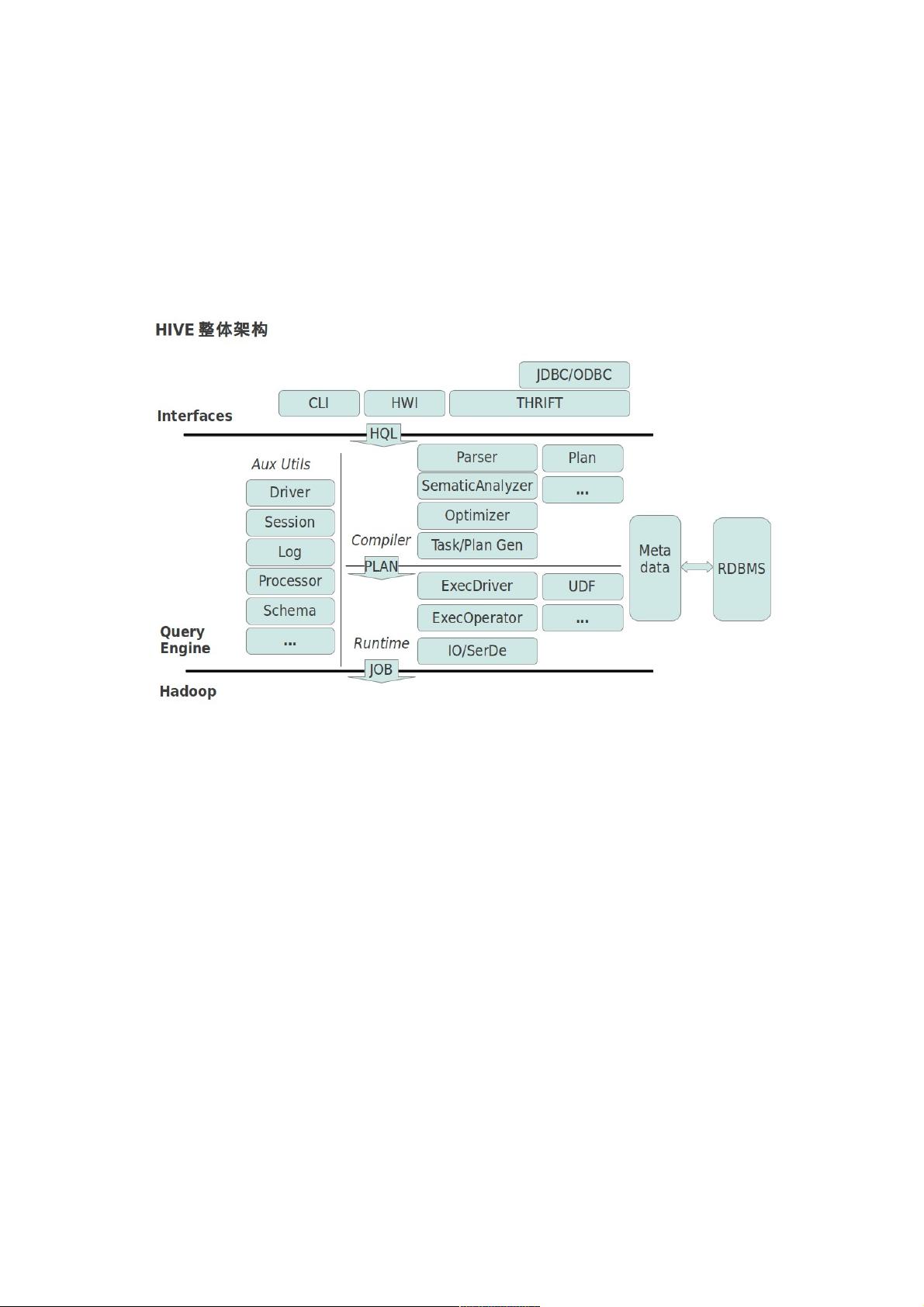
整体架构.............................................................................................................................2
主要流程.............................................................................................................................4
顶级流程.........................................................................................................................4
Session 管理...................................................................................................................4
命令处理器.....................................................................................................................5
Driver.............................................................................................................................6
编译流程.....................................................................................................................6
执行流程.....................................................................................................................8
编译器...............................................................................................................................10
前端..............................................................................................................................10
ParseDriver..............................................................................................................10
辅助类..................................................................................................................10
分析流程...............................................................................................................11
中后端..........................................................................................................................11
语义分析框架............................................................................................................12
BaseSemanticAnalyzer........................................................................................12
SemanticAnalyzer................................................................................................12
Optimizer.............................................................................................................13
遍历框架...............................................................................................................14
运行时...............................................................................................................................16
Task..............................................................................................................................16
Operator......................................................................................................................17
ExprNodeEvaluator.....................................................................................................19
对象模型...........................................................................................................................20
总结..................................................................................................................................22


剩余21页未读,继续阅读
资源评论













