






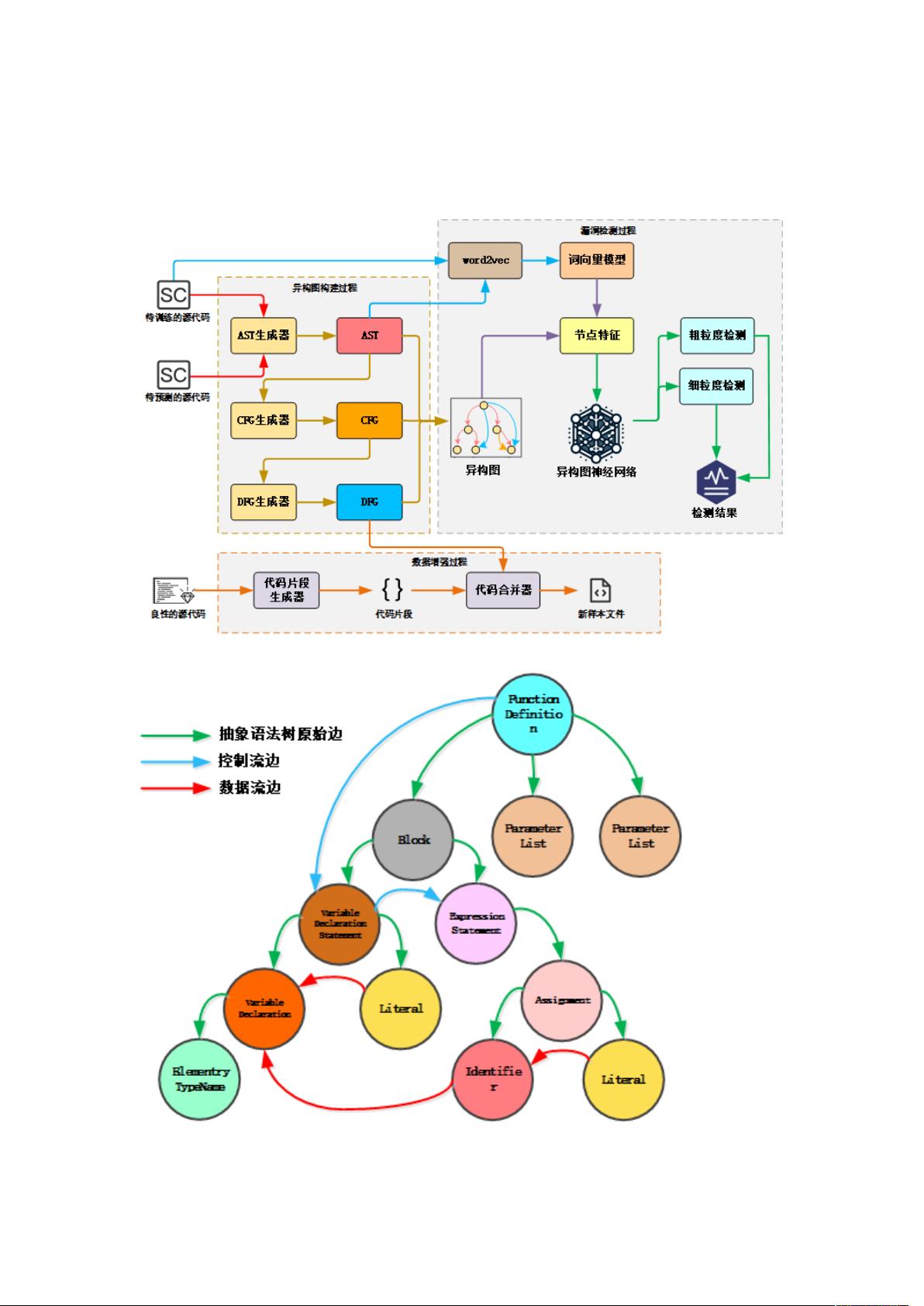
为 Smart Contract 提取以 AST、CFG、DFG 为基础的异构图,使用图神经网络进行多粒度的
分类,实现行级别以及合约级别的漏洞检测任务。
总体框架图如下所示:
得到的异构图案例如下所示:
Usage
在 dataset.zip 中已经压缩了 28 组数据集。分别是 7 种漏洞类型,每组漏洞类型都分为原始

合约级别,增强以后合约级别、原始行级别、增强后行级别。每个文件夹中都存有对应的 cmd
命令,可用于运行、测试。
根据虚拟环境的复现过程操作以后,使用对应的虚拟环境以及参数调用对应的 main.py 即可。
(lunikhod) root@0efc54cd086a:~/MVD-HG# python main.py --help
usage: main.py [-h] [--run_mode RUN_MODE] [--create_corpus_mode
CREATE_CORPUS_MODE] [--train_mode TRAIN_MODE] [--data_dir_name
DATA_DIR_NAME] [--attack_type_name ATTACK_TYPE_NAME]
[--create_code_snippet] [--data_augmentation] [--gpu_id GPU_ID] [--
coefficient COEFFICIENT] [--target_dir TARGET_DIR] [--target_file TARGET_FILE]
参数表
optional arguments:
-h, --help show this help message and exit
--run_mode RUN_MODE 运行模式: 1.create:创建数据集的时候用的。 2.train:训练模式
(这个是文件级别的)。 3.predict:预测模式。 4.truncated:语言模型受损,需要重新训练。
5.line_classification_train:行级别的漏洞检测。
6.contract_classification_train:合约级别的漏洞检测。
--create_corpus_mode CREATE_CORPUS_MODE
创建文件的模式: 1.create_corpus_txt:仅仅创建语料库文件。
2.generate_all: 生成所有的向量文件。
--train_mode TRAIN_MODE
针对创建文件的模式一起使用的,如果创建文件的模式是
generate_all 那么这里应该标注是合约级别还是行级别,因为 built_vector_dataset 的时候需要
根据不同的任务类型,读取不一样的 json 文件
--data_dir_name DATA_DIR_NAME
数据文件夹的名字,为了可以多进程启动运行:
--attack_type_name ATTACK_TYPE_NAME
本次要操作的漏洞的类型,专门只操作这种漏洞。
--create_code_snippet
本次操作是否是用来创建合约的片段的
--data_augmentation 本次操作是否是用来拓展数据集的
--gpu_id GPU_ID 本次操作的 gpu 用哪个
--coefficient COEFFICIENT
系数
--target_dir TARGET_DIR
目标文件夹
--target_file TARGET_FILE
目标文件
Expermental Results
数据集组成
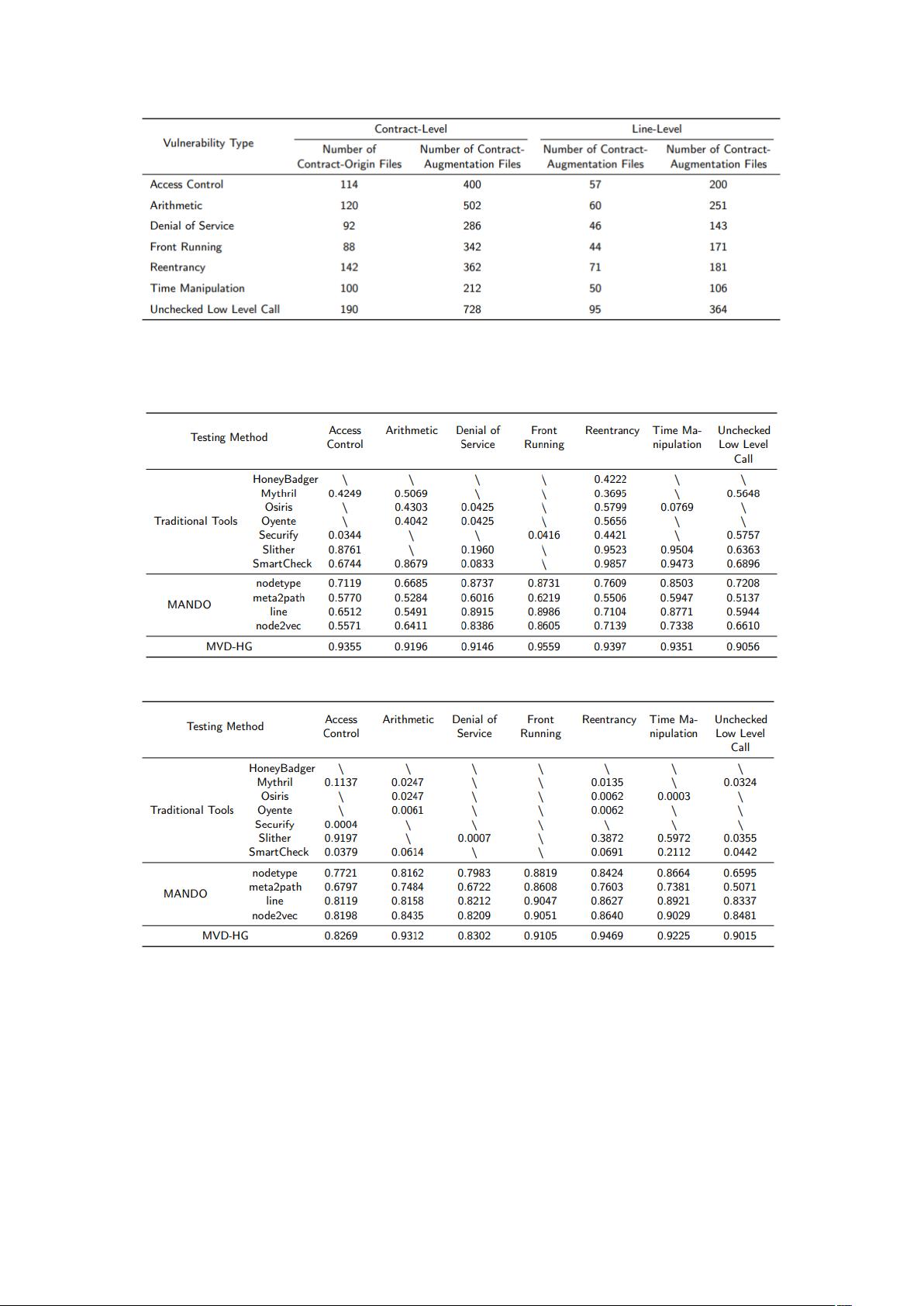
原始合约级别漏洞检测结果,'\'代表不具备该漏洞类型的检测能力。
原始行级别漏洞检测结果,'\'代表不具备该漏洞类型的检测能力。
使用数据增强以后的合约级别漏洞检测结果,'\'代表不具备该漏洞类型的检测能力。













