



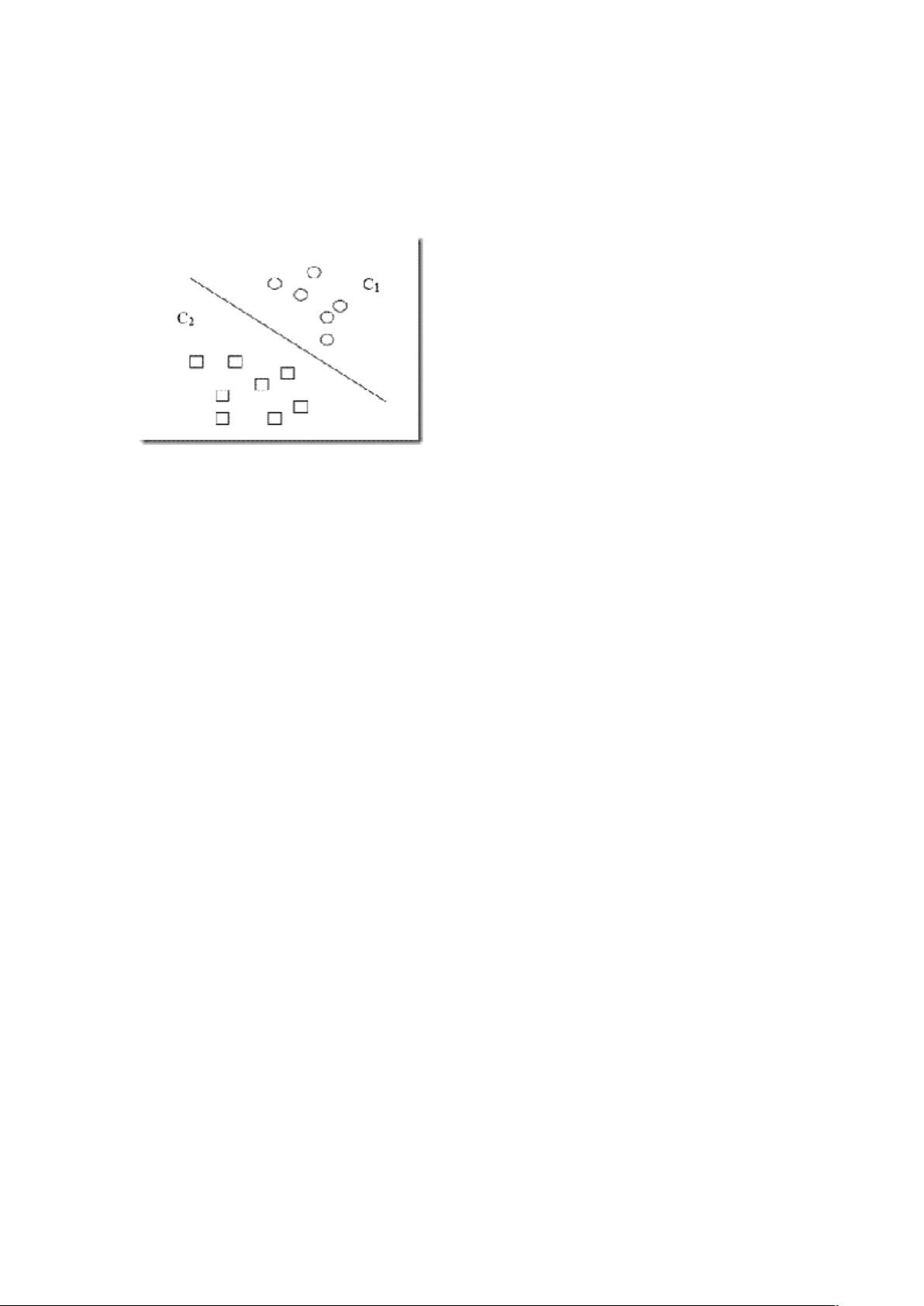
现在我们已经把一个本来线性不可分的文本分类问题,通过映射到高维空间而变成了线性可分的。就像下图这样:
圆形和方形的点各有成千上万个(毕竟,这就是我们训练集中文档的数量嘛,当然很大了)。现在想象我们有另一个
训练集,只比原先这个训练集多了一篇文章,映射到高维空间以后(当然,也使用了相同的核函数),也就多了一个
样本点,但是这个样本的位置是这样的:
就是图中黄色那个点,它是方形的,因而它是负类的一个样本,这单独的一个样本,使得原本线性可分的问题变成了
线性不可分的。这样类似的问题(仅有少数点线性不可分)叫做“近似线性可分”的问题。
以我们人类的常识来判断,说有一万个点都符合某种规律(因而线性可分),有一个点不符合,那这一个点是否就代
表了分类规则中我们没有考虑到的方面呢(因而规则应该为它而做出修改)?
其实我们会觉得,更有可能的是,这个样本点压根就是错误,是噪声,是提供训练集的同学人工分类时一打瞌睡错放
进去的。所以我们会简单的忽略这个样本点,仍然使用原来的分类器,其效果丝毫不受影响。
但这种对噪声的容错性是人的思维带来的,我们的程序可没有。由于我们原本的优化问题的表达式中,确实要考虑所
有的样本点(不能忽略某一个,因为程序它怎么知道该忽略哪一个呢?),在此基础上寻找正负类之间的最大几何间
隔,而几何间隔本身代表的是距离,是非负的,像上面这种有噪声的情况会使得整个问题无解。这种解法其实也叫做
“硬间隔”分类法,因为他硬性的要求所有样本点都满足和分类平面间的距离必须大于某个值。
因此由上面的例子中也可以看出,硬间隔的分类法其结果容易受少数点的控制,这是很危险的(尽管有句话说真理总
是掌握在少数人手中,但那不过是那一小撮人聊以自慰的词句罢了,咱还是得民主)。














