Atlas2.2.0编译、安装及使用(集成ElasticSearch,导入Hive数据).doc
版权申诉
103 浏览量
2022-07-12
11:32:52
上传
评论
收藏 747KB DOC 举报

Bert 不完全手册 5. BERT 推理提速?训练提速!内存压缩!Albert
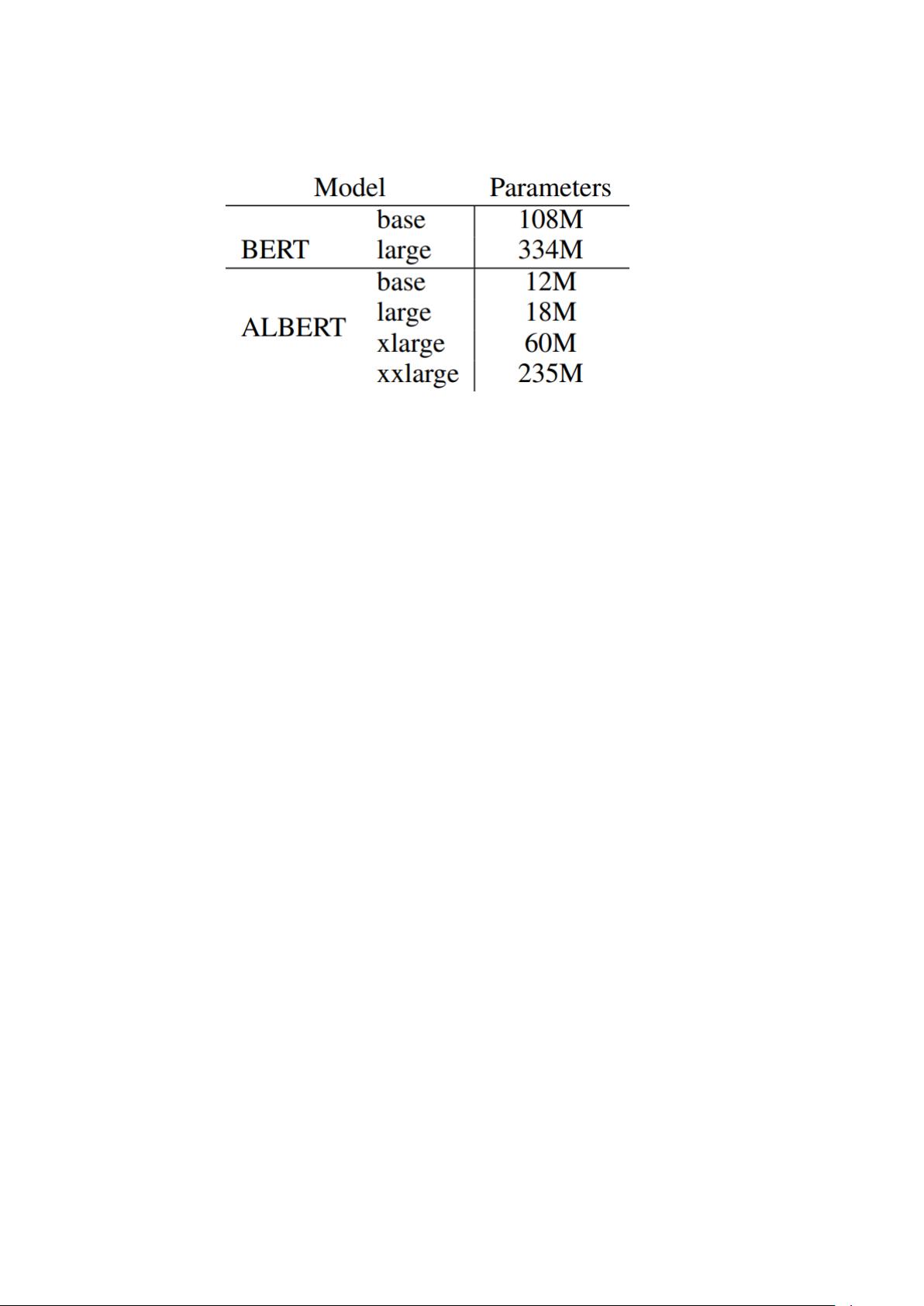
Albert 是 A Lite Bert 的缩写,通过词向量矩阵分解,以及 transformer block 的参
数共享,大大降低了 Bert 的参数量级。在我读 Albert 论文之前,因为 Albert 和蒸馏,剪枝
一起被归在模型压缩方案,导致我一直以为 Albert 也是为了优化 Bert 的推理速度,但其实
Albert 主要用在模型参数(内存)压缩,以及训练速度优化,在推理速度上并没有提升。正
在施工中的文本分类库里也加入了 Albert 预训练模型,有在 chinanews 上已经微调好可以开
箱即用的模型,同时支持半监督,领域迁移,降噪 loss,蒸馏等模型优化项,感兴趣戳这里
SimpleClassification
Albert 是 A Lite Bert 的缩写,确实 Albert 通过词向量矩阵分解,以及 transformer block 的
参数共享,大大降低了 Bert 的参数量级。在我读 Albert 论文之前,因为 Albert 和蒸馏,剪
枝一起被归在模型压缩方案,导致我一直以为 Albert 也是为了优化 Bert 的推理速度,但其
实 Albert 更多用在模型参数(内存)压缩,以及训练速度优化,在推理速度上并没有提升。
如果说蒸馏任务是把 Bert 变矮瘦,那 Albert 就是把 Bert 变得矮胖。正在施工中的文本分类
库里也加入了 Albert 预训练模型,有在 chinanews 上已经微调好可以开箱即用的模型,同时
支持半监督,领域迁移,降噪 loss,蒸馏等模型优化项,感兴趣戳这里 SimpleClassification
Albert 主要有以下三点创新
参数共享:降低 Transfromer Block 的整体参数量级
词向量分解:有效降低词向量层参数量级
Sentence-Order-Prediction 任务:比 NSP 更加有效的学习句间关系
下面我们分别介绍这三个部分
词向量分解
其实与其说是分解,个人觉得词向量重映射的叫法更合适一些。在之前 BERT 等预训练
模型中,词向量的维度 E 和之后隐藏层的维度 H 是相同的,因为在 Self-Attention 的过程中
Embedding 维度是一直保持不变的,所以要增加隐藏层维度,词向量维度也需要变大。但是
从包含的信息量来看,词向量本身只包含上下文无关的信息,并不需要像隐藏层一样存储大
量的上下文语义,所以相同维度的限制在词向量部分存在一定的参数冗余。所以笔者对词向






评论0
最新资源