

理“ Druid 元数据”之乱
本文主要从 Druid 元数据相关概念、Druid 架构、Druid 元数据存储介质三部分阐
述 Druid 元数据信息,进而更全面、更系统的了解 Druid 系统内部各组件之间的协作关系和
运行机制。
vivo 互联网大数据团队-Zheng Xiaofeng
一、背景
Druid 是一个专为大型数据集上的高性能切片和 OLAP 分析而设计的数据存储系统。
由于 Druid 能够同时提供离线和实时数据的查询,因此 Druid 最常用作为 GUI 分析、业
务监控、实时数仓的数据存储系统。
此外 Druid 拥有一个多进程,分布式架构,每个 Druid 组件类型都可以独立配置和扩展,
为集群提供最大的灵活性。
由于 Druid 架构设计和数据(离线,实时)的特殊性,导致 Druid 元数据管理逻辑比较复
杂,主要体现在 Druid 具有众多的元数据存储介质以及众多不同类型组件之间元数据传输逻
辑上。
本文的目的是通过梳理 Druid 元数据管理这个侧面从而进一步了解 Druid 内部的运行机
制。
二、 Druid 元数据相关概念
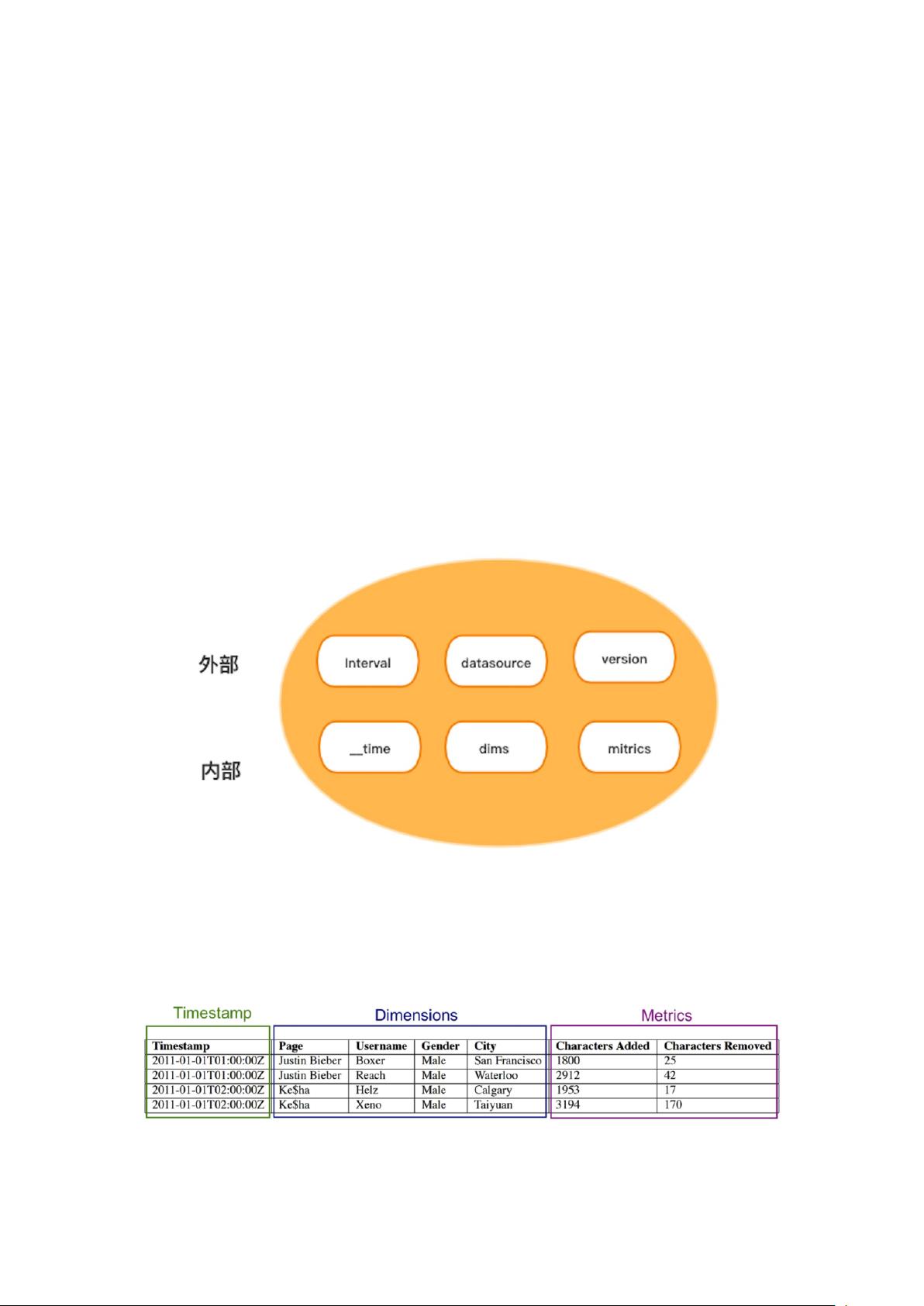
2.1 Segment
Segment 是 Druid 管理数据的最基本单元,一个 Datasource 包含多个 Segment,每个
Segment 保存着 Datasource 某个时间段的数据,这个特定时间段的数据组织方式是通过
Segment 的 payload(json)来定义的,payload 内部定义了某个 Segment 的维度,指标等信
息。
同一个 Datasource 的不同 Segment 的 payload 信息(维度、指标)可以不相同,Segment
信息主要包含下面几部分:
【时间段(Interval)】:用于描述数据的开始时间和结束时间。

剩余19页未读,继续阅读
资源评论


书博教育
- 粉丝: 1
- 资源: 2837









最新资源
- 人、垃圾、非垃圾检测18-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 金智维RPA server安装包
- 二维码图形检测6-YOLO(v5至v9)、COCO、CreateML、Darknet、Paligemma、TFRecord数据集合集.rar
- Matlab绘制绚丽烟花动画迎新年
- 厚壁圆筒弹性应力计算,过盈干涉量计算
- 网络实践11111111111111
- GO编写图片上传代码.txt
- LabVIEW采集摄像头数据,实现图像数据存储和浏览
- 几种不同方式生成音乐的 Python 源码示例.txt
- python红包打开后出现烟花代码.txt
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


