• 二元属性(离散属性点特例,仅取两个不同值)
对称的二元属性(两个值一样重要)
非对称的二元属性(通常一个比另一个更重要常用1表示)
2.数据类型
• 记录数据(数据矩阵、文档数据、事务数据(购物篮数据))
• 图数据(万维网-带有对象之间的联系、分子结构)
• 有序数据(时序数据、序列数据、基因序列数据、空间数据)
3. 数据的统计描述
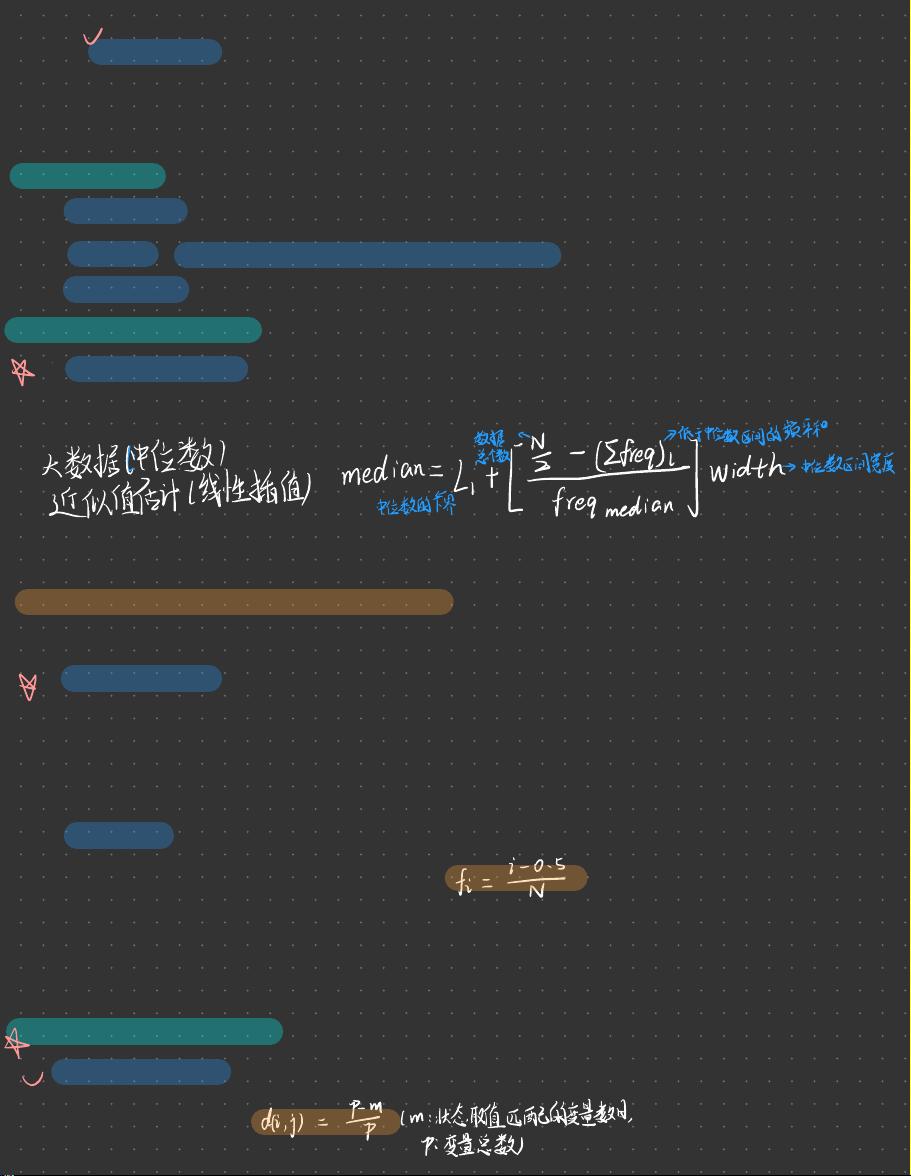
• 中心趋势度量(均值、众数、中位数、中列数-数据集最大和最小
的平均值)
众数:
一个数据集中可能有多个众数,对于非对称的单峰数据,有
平均值-众数=3(平均值-中位数)
• 数据的散布(极差、四分位数、四分位数极差、五数概括、盒
图)
四分位数极差:IQR=Q3-Q1
五数概括:[min,Q1,median,Q3,max]
• 可视化
分位数图(观察单变量数据分布)
分位数-分位数图(刻画一个分布到另一个是否有漂移)
直方图(刻画数据的整体分布情况)
散点图(数据的具体分布<=3维)
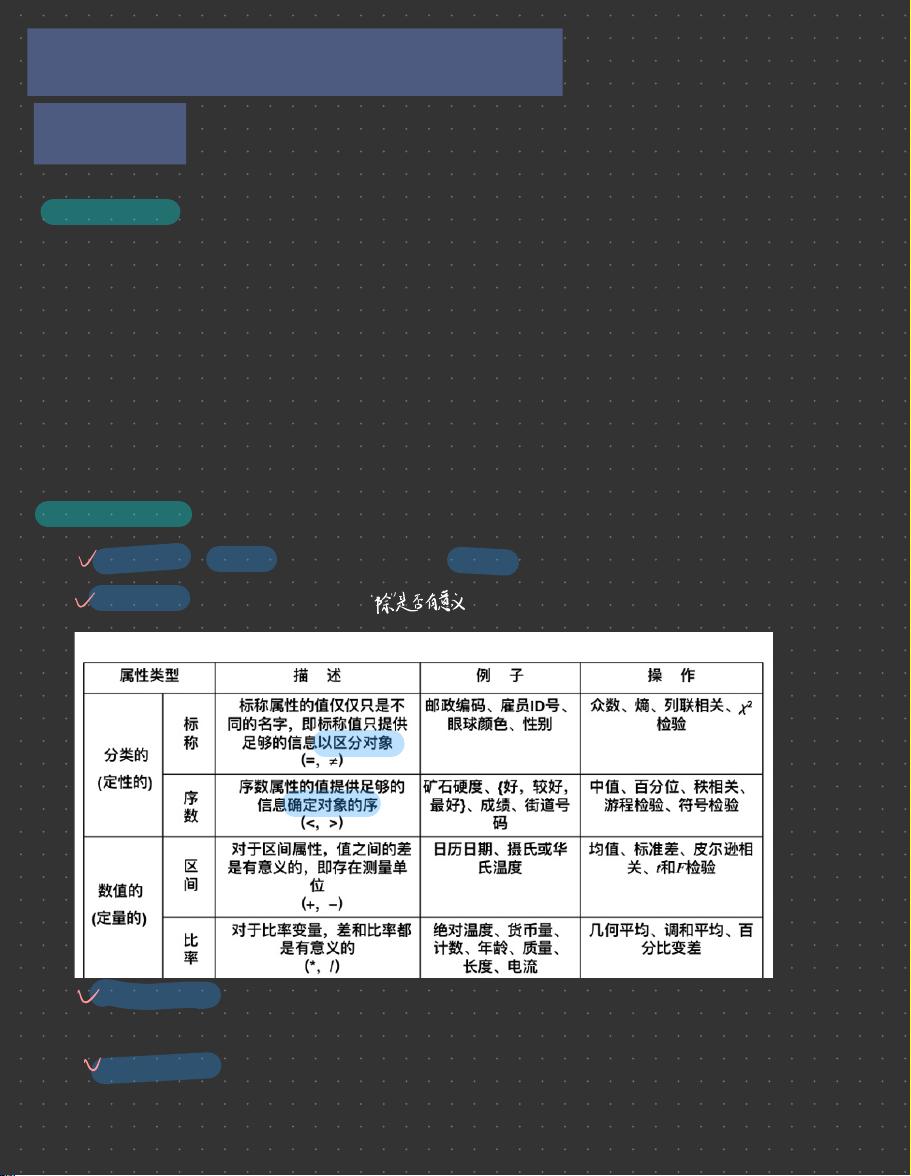
4. 数据的相似性度量
1)标称属性数据
相异性度量方法:
√
成
→
低于中位数运间的频率和
⼤数据
:
《
中位数
)
近似值估计
(
线性插值
1
media
L
,
+
[
☆
-
Efrealamedian
|
width
糷院数区间宽度
←
中位数的不界
θ
fi
=
i
⼀器
☆
U
dil
,
j
)
=
P
管
(
mi
状态取值匹配的变量数⽇
,
P
:
变量总数
)