
Selenium
⾃动化爬取
BOSS
招聘数据:⼀个完整的指南(实测有效)
ˇˇˇ ˇˇˇ
⼀、简介
随着互联⽹的普及,越来越多的招聘信息来源于各⼤招聘⽹站。然⽽,这些招聘信息往往以⽂本形式存在,使得⼈⼯阅读和分析变得耗时且低效。为了提⾼招聘数据的处理
效率,本⽂将介绍如何使⽤Selenium 进⾏ BOSS 招聘数据的⾃动化爬取。
⽽且BOOS的反爬机制很厉害,cookie经常发⽣变化,使⽤selenium通过⾃动化操作浏览器来获取⻚⾯上的数据会更简单⼀点
⼆、技术栈
本⽂将介绍使⽤的技术栈,Python、Selenium、Pandas 、Random
三、难点
在通过使⽤
Selenium⾃动操作浏览器访问BOOS
招聘时,
BOOS会通过各种⼿段包括浏览器指纹识别技术或者访问⾏为来判定操作对象是否是机器⼈,判断成⽴之后会返回
⼀些错误的⻚⾯信息或者验证码之类的,所以在获取招聘数据之前,应该先学会伪装⾃⼰,让浏览器⽆法识别到是机器⼈在操作,
具体细节可以参考该⽂章selenium实战指南:如何防⽌被浏览器检测?
四、代码实现
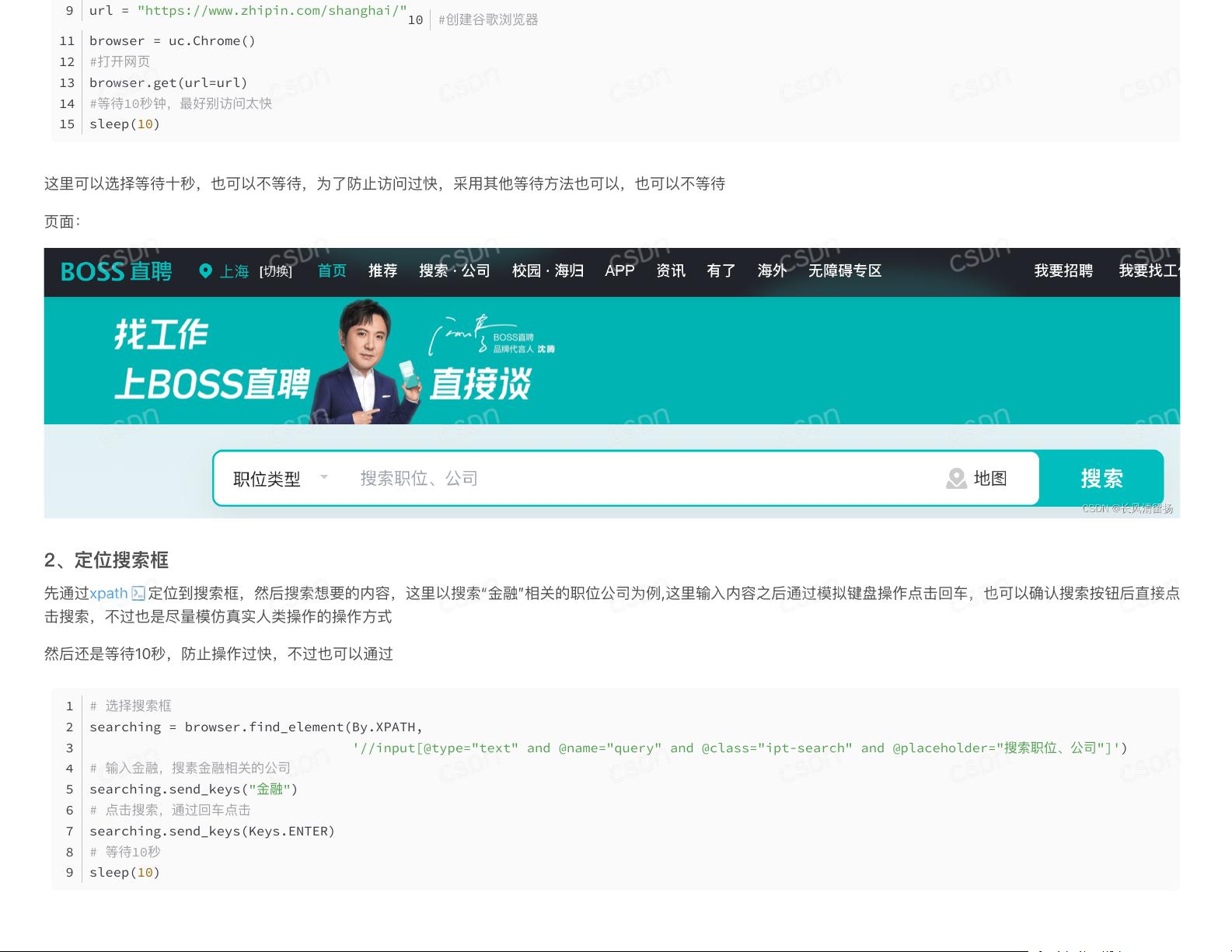
1、打开⾕歌浏览器
1 from selenium.webdriver.common.by import By
2 from selenium.webdriver.common.keys import Keys
3 from time import sleep
4 import pandas as pd
5 import undetected_chromedriver as uc
6 import random
7
8 #BOOS招聘⽹站
内容来源:csdn.net
作者昵称:⻓⻛清留扬
原⽂链接:https://blog.csdn.net/qq_51431069/article/details/138142078
作者主⻚:https://blog.csdn.net/qq_51431069
第1页 共14页 2024/9/20, 17:07

剩余13页未读,继续阅读
资源评论













