## 作者
Albert Guo
## 专题系列导引
  爬虫课题描述可见:
> [Python爬虫【零】课题介绍 -- 对“微博辟谣”账号的历史微博进行数据采集](https://blog.csdn.net/u010086122/article/details/114957255)
  课题解决方法:
> **微博移动版爬虫**
> > [Python爬虫【一】爬取移动版“微博辟谣”账号内容(API接口)](https://blog.csdn.net/u010086122/article/details/114997159)
>
> **微博PC网页版爬虫**
> > [Python爬虫【二】爬取PC网页版“微博辟谣”账号内容(selenium同步单线程)](https://blog.csdn.net/u010086122/article/details/114902317)
> > [Python爬虫【三】爬取PC网页版“微博辟谣”账号内容(selenium单页面内多线程爬取内容)](https://blog.csdn.net/u010086122/article/details/114966538)
> > [Python爬虫【四】爬取PC网页版“微博辟谣”账号内容(selenium多线程异步处理多页面)](https://blog.csdn.net/u010086122/article/details/114981525)
---
## 工程介绍
此工程是为了解决一个学习性质的爬虫课题:**爬取‘微博辟谣’账号的历史微博**。具体要求如下:
```
采集范围:
1. ‘微博辟谣’账号原创或转发的历史全部贴子。
2. 需要踢除微博月度工作报告。剔除的样例如下:
采集格式:
采集方框中的如下文本信息。分为4列。每行一条记录。
1. 若为该账号原创帖,则采集账号本身、文本内容、发布时间、转发数。
2. 若为转发的贴子,需要采集包含:原贴发布账号、原贴文本内容、原贴发布时间、原贴转发数。
```
原贴提取内容如下红框

转发贴提取内容:
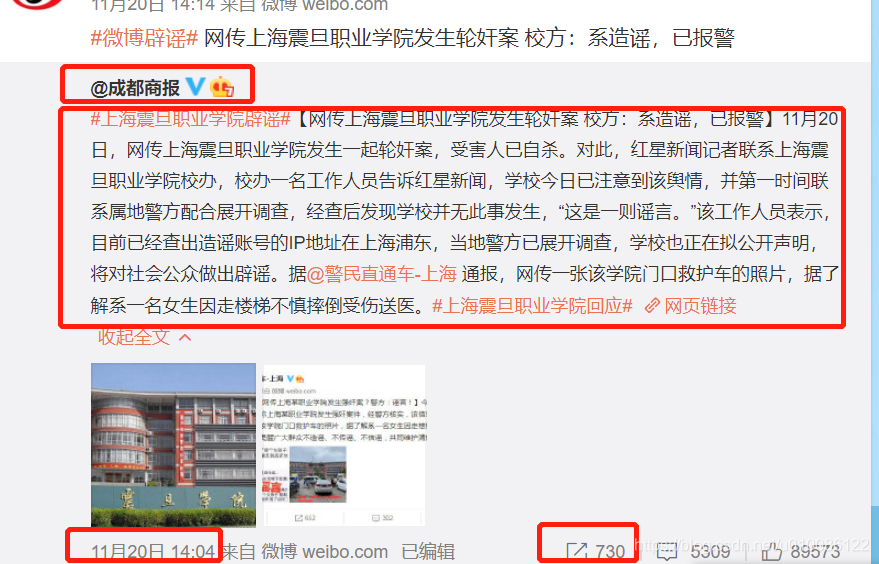
## 注意事项
1. 为了防止过快访问被微博服务器检测到恶意爬取,最好每次调用完成处理后,等待1s左右的时间(如果能用ip池做代理绕开服务器爬取检测更好)
2. 移动版微博API设置了只能拉取2000条数据(前80页)。超过2000条数据,since_id不会再返回;接口入参用page传参也是如此,因此数据不全问题无法回避。
3. 使用selenium爬取PC网页版微博时,必须先按照本地电脑的操作系统类型以及已经安装好的Chrome版本,**下载好匹配的selenium驱动并配置好环境变量**,才能正常启动驱动;否则报错。chrome驱动下载地址: [https://npm.taobao.org/mirrors/chromedriver](https://npm.taobao.org/mirrors/chromedriver)
4. 受本地电脑运行速度、wifi网络速度影响,在不同环境下,本程序执行selenium爬取PC网页版微博的**运行速度也不一样**。而浏览器对Web页面渲染是渐进式加载的,有时候页面未完全加载完成,浏览器已经有了显示,爬虫程序也开始了后续操作。**此时可能js、css仍未生效,因此在用selenium操作时,可能会出现“爬取错误,页面报错”的情况**。这种情况并非只在登录时会发生,而是在整个爬取过程中,都有可能出现,**引起爬取报错失败**。因此各位需要结合自己本地网络和电脑配置情况,**调整程序等待时间(time.sleep()的数值)**,确保页面完全加载完成后,后续填表或者爬取的逻辑才会执行
> - 因此各位需要结合自己本地网络和电脑配置情况,**调整程序等待时间**,确保页面完全加载完成后,后续填表或者爬取的逻辑才会执行
> - 用try-except处理爬取异常的情况,尽量保留部分data数据写入excel
> - 也可以用selenium提供的隐式等待执行方法:driver.implicitly_wait(30) # 隐性等待,最长等30秒
> - 也可以用selenium提供的隐式等待执行方法:WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located(locator))
5. selenium爬取网页是模拟人操作页面浏览的方式,进行信息提取。因此实际执行中发现,如果程序执行find_element_by_XXX()、click()等查询和点击操作时,如果driver弹出的浏览器,有不限于如下的一些情况**(被最小化隐藏、被其他程序页面覆盖浏览器、要操作的对象还在滚动条区域内,没页面中显示、被其他可以click的标签比如消息提醒button布局覆盖、driver窗口被拉太瘦以至于下拉最底后js无法展示“下一页”按钮......)**,则selenium的操作会无法生效,甚至报错can't find element,导致程序异常。这个问题在电脑全屏打开其他窗口时尤其容易发生,例如在看pycharm后端日志、打开其他浏览器全屏搜索问题。
> 因此在程序运行时,请保持driver浏览器始终在最顶端,显示窗口足够大,并在中途不要操作,等待爬取完成;同时,driver浏览器窗口需要保持一定的大小,当触发登录点击按钮、下拉到最低端点击下一页按钮时,都需要在chrome浏览器内能肉眼观测到这个元素
6. 多线程程序涉及登录态cookie复制、多窗口多并发等问题,从实际执行结果来看稳定性并不如前面几种方法可靠。博主已尽量做到多种极端情况判断,提高了稳定性,但多线程程序仍以实验性质为主,读者尽量不采用此种方式来实际获取数据
7. 本程序初稿编时间为2020年12月,整理发表时间为2021年3月20日,此时间点程序运行正常。但微博HTML页面会随时间而更新,因此有可能导致本程序selenium步骤执行失效。本程序旨在抛砖引玉,希望读者能从中获取灵感,开发出适合自己的版本
---
### 声明
  此问题为探讨研究性质课题,因此**专题内所提供的文章、源码、方法、工程、爬取到的数据,都仅供兴趣爱好了解或个人学习研究使用,所有版权归属作者或原文博主。不得将其用于任何商业用途,也不可用于爬取私人数据,或用于网络攻击工具,否则相关法律后果由使用者自行承担!**
微博数据采集python+selenium工程:WBCrawler.zip

版权申诉
 WBCrawler.zip (15个子文件)
WBCrawler.zip (15个子文件)  WBCrawler-share
WBCrawler-share  main.py 1KB pc __init__.py 0B batch_crawl.py 11KB line_crawl.py 7KB crawl_handle.py 4KB readme.md 6KB common util.py 9KB __init__.py 0B property.py 3KB m m_crawler.py 7KB __init__.py 0B .gitignore 41B excel
main.py 1KB pc __init__.py 0B batch_crawl.py 11KB line_crawl.py 7KB crawl_handle.py 4KB readme.md 6KB common util.py 9KB __init__.py 0B property.py 3KB m m_crawler.py 7KB __init__.py 0B .gitignore 41B excel  m_WB_result.xlsx 6KB WB_result.xlsx 9KB batch_WB_result.xlsx 9KB
m_WB_result.xlsx 6KB WB_result.xlsx 9KB batch_WB_result.xlsx 9KB












- 1
- 2
- 3
- 4
- 5
前往页