# README
[TOC]
## ID3决策树
ID3 使用的分类标准是信息增益,它表示得知特征 A 的信息而使得样本集合不确定性减少的程度。
数据集的信息熵:

其中 $C_{k}$ 表示集合 D 中属于第 k 类样本的样本子集。
针对某个特征 A,对于数据集 D 的条件熵 $H(D|A)$
为:
其中 $D_{i}$ 表示 D 中特征 A 取第 i 个值的样本子集, $D_{ik}$表示$D_{i}$中属于第 k 类的样本子集。
信息增益 = 信息熵 - 条件熵:
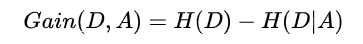
信息增益越大表示使用特征 A 来划分所获得的“纯度提升越大”。
**手写代码解释:**
这里实现了ID3算法的基本思想,通过递归构建决策树,并使用信息增益作为划分标准。在预测阶段,对每个样本遍历决策树,根据特征值选择相应的分支,直到达到叶子节点,返回预测的类别。
```python
class ID3DecisionTree:
def __init__(self, epsilon=0.1):
self.epsilon = epsilon # 信息增益阈值,如果小于该值,则停止划分
self.tree = None # 决策树
self.feature_names = None # 特征名称
def fit(self, X, y):
self.feature_names = X.columns # 存储特征名称
X = X.values # 将 DataFrame 转换为 NumPy 数组
y = y.values # 将 Series 转换为 NumPy 数组
self.tree = self._build_tree(X, y) # 构建决策树
def _build_tree(self, X, y):
if len(np.unique(y)) == 1: # 如果所有样本属于同一类别,返回该类别
return y[0]
if X.shape[1] == 0: # 如果没有更多特征可用于划分,返回出现次数最多的类别
return Counter(y).most_common(1)[0][0]
best_feature, best_threshold = self._choose_best_feature(X, y) # 选择最佳划分特征和阈值
if best_feature is None: # 如果无法找到合适的划分特征,返回出现次数最多的类别
return Counter(y).most_common(1)[0][0]
feature_name = self.feature_names[best_feature] # 获取最佳划分特征的名称
tree = {feature_name: {}} # 创建字典表示当前节点
left_mask = X[:, best_feature] < best_threshold # 左子树的样本掩码
right_mask = X[:, best_feature] >= best_threshold # 右子树的样本掩码
X_left, y_left = X[left_mask], y[left_mask] # 左子树的样本和标签
X_right, y_right = X[right_mask], y[right_mask] # 右子树的样本和标签
tree[feature_name]['< ' + str(best_threshold)] = self._build_tree(X_left, y_left) # 递归构建左子树
tree[feature_name]['>= ' + str(best_threshold)] = self._build_tree(X_right, y_right) # 递归构建右子树
return tree
def _choose_best_feature(self, X, y):
best_gain = -1 # 最佳信息增益
best_feature = None # 最佳划分特征
best_threshold = None # 最佳划分阈值
for feature in range(X.shape[1]): # 遍历所有特征
thresholds = np.unique(X[:, feature]) # 获取当前特征的所有取值作为候选阈值
for threshold in thresholds: # 遍历所有候选阈值
gain = self._information_gain(X, y, feature, threshold) # 计算当前特征和阈值的信息增益
if gain > best_gain: # 如果当前信息增益更大,更新最佳划分特征、阈值和信息增益
best_gain = gain
best_feature = feature
best_threshold = threshold
if best_gain < self.epsilon: # 如果最佳信息增益小于阈值,则停止划分
return None, None
return best_feature, best_threshold
def _information_gain(self, X, y, feature, threshold):
parent_entropy = self._entropy(y) # 计算父节点的熵
left_mask = X[:, feature] < threshold # 左子树的样本掩码
right_mask = X[:, feature] >= threshold # 右子树的样本掩码
n_left = left_mask.sum() # 左子树的样本数
n_right = right_mask.sum() # 右子树的样本数
if n_left == 0 or n_right == 0: # 如果左子树或右子树没有样本,信息增益为0
return 0
child_entropy = (n_left / len(y)) * self._entropy(y[left_mask]) + (n_right / len(y)) * self._entropy(y[right_mask]) # 计算子节点的熵
return parent_entropy - child_entropy # 返回信息增益
def _entropy(self, y):
_, counts = np.unique(y, return_counts=True) # 获取每个类别的样本数
probabilities = counts / len(y) # 计算每个类别的概率
return -(probabilities * np.log2(probabilities)).sum() # 计算熵
def predict(self, X):
X = X.values # 将 DataFrame 转换为 NumPy 数组
return [self._traverse_tree(x, self.tree) for x in X] # 对每个样本遍历决策树进行预测
def _traverse_tree(self, x, node):
if not isinstance(node, dict): # 如果当前节点是叶子节点,直接返回类别
return node
feature_name = list(node.keys())[0] # 获取当前节点的特征名称
feature = self.feature_names.get_loc(feature_name) # 获取当前特征的索引
thresholds = list(node[feature_name].keys()) # 获取当前节点的所有阈值
threshold_left = [t for t in thresholds if t.startswith('<')][0] # 获取左子树的阈值
threshold_right = [t for t in thresholds if t.startswith('>=')][0] # 获取右子树的阈值
if x[feature] < float(threshold_left.split(' ')[1]): # 如果样本的特征值小于左子树阈值,递归遍历左子树
return self._traverse_tree(x, node[feature_name][threshold_left])
else: # 否则,递归遍历右子树
return self._traverse_tree(x, node[feature_name][threshold_right])
```
> 1. 初始化决策树对象,设置信息增益阈值、决策树和特征名称。
> 2. 在 `fit` 方法中,将数据集转换为 NumPy 数组,并调用 `_build_tree` 方法构建决策树。
> 3. 在 `_build_tree` 方法中,递归构建决策树。如果所有样本属于同一类别或没有更多特征可用于划分,则返回相应的类别。否则,调用 `_choose_best_feature` 方法选择最佳划分特征和阈值,并根据阈值将数据集划分为左右子树,递归构建子树。
> 4. 在 `_choose_best_feature` 方法中,遍历所有特征和候选阈值,计算每个特征和阈值的信息增益,选择信息增益最大的特征和阈值作为最佳划分。如果最佳信息增益小于阈值,则停止划分。
> 5. 在 `_information_gain` 方法中,计算特定特征和阈值的信息增益。首先计算父节点的熵,然后根据阈值将数据集划分为左右子树,计算子节点的熵,最后返回信息增益(父节点熵减去子节点熵)。
> 6. 在 `_entropy` 方法中,计算给定数据集的熵。首先获取每个类别的样本数,计算每个类别的概率,然后计算熵。
> 7. 在 `predict` 方法中,对每个样本遍历决策树进行预测。在 `_traverse_tree` 方法中,根据当前节点的特征和阈值,递归遍历左子树或右子树,直到达到叶子节点,返回相应的类别。
**缺点**
- <font color='dd0000'>**ID3 没有剪枝策略,容易过拟合**</font>;
- 信息增益准则对可取值数目较多的特征有所偏好,类似“编号”的特征其信息增益接近于 1;
- 只能用于处理离散分布的特征;
- 没有考虑缺失值。
**结果:**
�
本科《机器学习》课程实验。在1000个车辆数据集上,使用决策树完成4分类.zip

需积分: 5 199 浏览量
2024-04-25
19:08:40
上传
评论
收藏 45KB ZIP 举报
 这是我在本科《机器学习》课程中的实验。在有1000个车辆数据的数据集上,使用决策树完成4分类,并进行性能评估。于是,我手写了ID3、CHAID、C4.5、CART这四个基本的决策树,并根据已有库实现RandomForest、XGBoost、GBDT、LightGBM这四个较复杂的.zip (15个子文件)
这是我在本科《机器学习》课程中的实验。在有1000个车辆数据的数据集上,使用决策树完成4分类,并进行性能评估。于是,我手写了ID3、CHAID、C4.5、CART这四个基本的决策树,并根据已有库实现RandomForest、XGBoost、GBDT、LightGBM这四个较复杂的.zip (15个子文件)  content
content  ID3.py 7KB CHAID.py 8KB LICENSE 11KB rGBDT.py 4KB RandomForest.py 4KB dataset
ID3.py 7KB CHAID.py 8KB LICENSE 11KB rGBDT.py 4KB RandomForest.py 4KB dataset  car_1000.txt 30KB val.csv 22KB CreateVal.py 1KB description.txt 4KB car_evaluation.csv 52KB C4.5.py 8KB CART.py 7KB LightGBM.py 5KB README.md 51KB XGBoost.py 5KB
car_1000.txt 30KB val.csv 22KB CreateVal.py 1KB description.txt 4KB car_evaluation.csv 52KB C4.5.py 8KB CART.py 7KB LightGBM.py 5KB README.md 51KB XGBoost.py 5KB资源评论













