

2020/1/2 AI基础:一文看懂BERT
https://mp.weixin.qq.com/s?__biz=MzIwODI2NDkxNQ==&mid=2247486959&idx=2&sn=030848835e4666ccc48f88815d80c31f&chksm=970486
…
1/21
AI基础:一文看懂BERT
0.
导
语
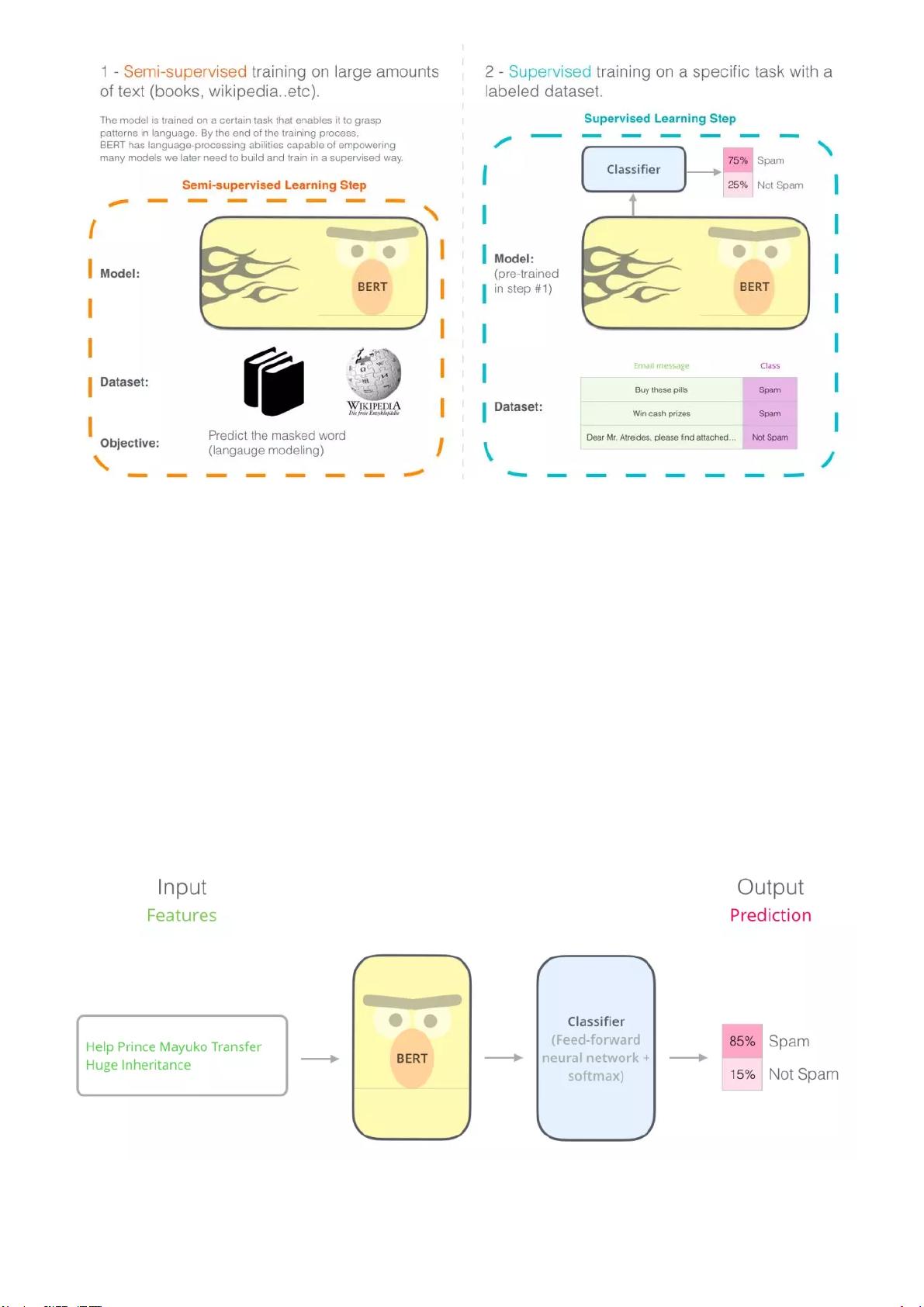
自google在2018年10月底公布BE RT在11项nlp任务中的卓越表现后,BERT(Bidirectional
Encoder Representation from Transformers)就成为NLP领域大火,在本文中,我们将研究
BERT模型,理解它的工作原理。
我最近在编写AI基础系列,这个是NLP(自然语言处理)的非常重要的部分。(黄海广)
目
前
已
经
发
布
:
AI
基
础
:
Python
开
发
环
境
设
置
和
小
技
巧
AI
基
础
:
Python
简
易
入
门
AI
基
础
:
Numpy
简
易
入
门
AI
基
础
:
Pandas
简
易
入
门
AI
基
础
:
Scipy(
科
学
计
算
库
)
简
易
入
门
AI
基
础
:
数
据
可
视
化
简
易
入
门
(
matplotlib
和
seaborn
)
AI
基
础
:
特
征
工
程
-
类
别
特
征
AI
基
础
:
特
征
工
程
-
数
字
特
征
处
理
AI
基
础
:
特
征
工
程
-
文
本
特
征
处
理
AI
基
础
:
词
嵌
入
基
础
和
Word2Vec
AI
基
础
:
图
解
Transformer
后
续
持
续
更
新
作者:jinjiajia95
出处:https://blog.csdn.net/weixin_40746796/article/details/89951967
原作者:Jay Alammar
原链接:https://jalammar.github.io/illustrated-bert/
机器学习初学者 2019-12-08机器学习初学者

剩余20页未读,继续阅读
资源评论


不安分实验室
- 粉丝: 130
- 资源: 23









最新资源
- 全桥变器,可以实现零电压开关和零电流开关ZVS和ZCS 波形好,和仿真详细对应说明
- 三相桥式全控整流器及其详细的说明等
- No.825 基于S7-200 PLC和组态王自动扶梯控制系统 带解释的梯形图程序,接线图原理图图纸,io分配,组态画面
- STM32+AD7124+热电偶方案+Pt100冷端补偿解析工程源码,源码包含Pt100、NTC热敏、热电偶处理驱动源码, 支持热电偶类型T、J、E、N、K、B、如果用于别的R、S 8种类型,并有Pt
- 暂态稳定性仿真分析 基于MATLAB Simulink的单机无穷大系统 可仿真、分析不同故障切除时间下,三相短路、两相短路接地、两相短路、单相接地短路故障状态下的暂态稳定性 可任意调节故障切除时间
- 带负载转矩前馈补偿的永磁同步电机FOC 1.采用滑模负载转矩观测器,可快速准确观测到负载转矩 赠送龙伯格负载转矩观测器用于对比分析 2.将观测到的负载转矩用作前馈补偿,可提高系统抗负载扰动能力;
- 双边工作自动裁断机全套设计资料100%好用.zip
- 基于STM32F4核心板的经典项目程序,远比网上搜索的开发板例程更有价值,历时2年时间打造 适合学生学习,工程师提高技术等等 项目内容为:用stm32f407单片机核心板和gy-91模块做一个功能
- 基于FAST与MATLAB SIMULINK联合仿真模型非线性风力发电机的PID独立变桨和统一变桨控制下仿真模型+参考文献,对于5WM非线性风机风机进行控制 链接simulink的scope出转速对比
- 永磁同步电机调速控制软件工程PMSM,该工程主要基于DSP28335硬件控制平台,两电平IPM模块主回路,DSP控制器控制, 配过压和过流保护,小功率电机调速控制,工程软件配注释,提供对应硬件原理图
- 汇川MD500E变频器开发方案 源码+解析, MD500E代码方案和解析文档+仿真资料 资料全 包含pmsm的foc控制算法,电阻、电感、磁链等参数的辩识算法,死区补偿算法过调制处理算法
- 超值福利 关键词:场景生成 缩减 微网优化调度,综合能源优化,matlab cplex等优化程序,全部打包带走,神经网络光伏预测,可提供优化学习资料 火火 运行环境:matlab 欢迎咨询
- Java项目:基于servlet+jsp+tomcat实现的网上点餐系统分享给需要的同学【完整源码+数据库】
- droop下垂并网控制,采用电压电流双环spwm控制.2018b版本
- 西门子1200PLC控制加KPT1200触摸屏,污水处理厂自控项目实例,含一台200SMART200加触摸屏泵站程序画面 内涵全套电气控制图纸 改建成已运行项目,所有应用均经过实际验证 应用包括
- 全套S7-1200一拖三恒压供水程序样例+PID样例+触摸屏样例 34 1、此程序采用S7-1200PLC和KTP1000PN触摸屏人机执行PID控制变频器实现恒压供水. 包括plc程序,触摸屏
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


