







1
一、 选题分析
命名实体识别(Named entity identification,简称 NER)是信息提取、问答系统、句法分
析、机器翻译、面向 Semantic Web 的元数据标注等应用领域的重要基础工具,在自然语言
处理技术走向实用化的过程中占有重要地位;命名实体识别在处理英文实体时较为容易,由
于英文具有大小写的特征,并且单词之间具有明显的分隔标志——空格,而在中文里面,中
文没有明显的实体界限,并且中文实体没有统一的特征,无法使用固定模板进行特征的提取,
再加上近些年来网络用语的兴盛,中文经常夹杂着英文,这对中文命名实体识别带来了很大
的困难;为了简化问题,我们小组经过商议决定,不针对词组进行中文命名实体的识别,而
是针对每一个字符进行实体识别的标注,如此便可以避免模型在分词方面所带来的误差,我
们期望能够通过构造模型,将输入的中文文本进行逐字符地实体标注,以达到识别文本里面
的中文命名实体的效果。NER 一直是自然语言处理(NLP)领域中的研究热点,从早期基于
词典和规则的方法,到传统机器学习的方法,到近年来基于深度学习的方法,NER 研究进
展的大概趋势大致如图1所示,最终我们小组决定使用隐马尔可夫模型与条件随机场模型进
行中文命名实体识别。
(图1)
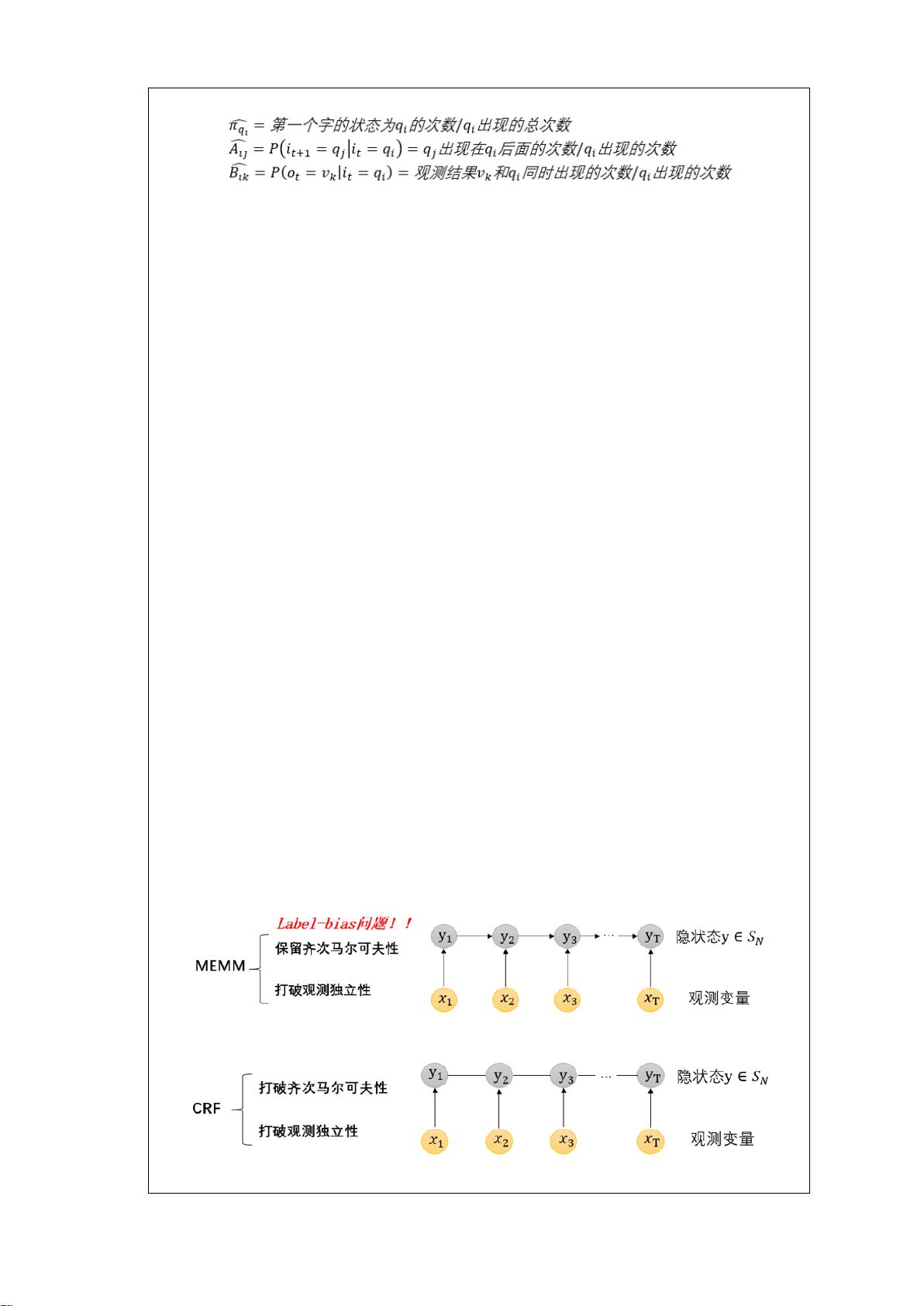
本人在实验中负责数据集的搜集、预处理,由于隐马尔可夫模型存在缺陷,为了解决其
缺陷,我决定使用条件随机场模型进行实验,我负责构造条件随机场模型,针对条件随机模
型进行参数的调整,并通过模型针对数据集进行预测,最后对模型进行五折交叉验证,负责
数据可视化部分。
二、实验基本原理与设计
⚫ 数据收集:将问题进行简化,即针对中文文本进行逐字的中文实体标注,所以在收集数
据集时针对本问题找到了逐字标注的数据集,其来源于 Github 上面的开原数据集(连
接:https://github.com/SophonPlus/ChineseNlpCorpus), 该数据集包含 5 万多条中文命名
实体识别标注数据(IOB2 格式,符合 CoNLL 2002 和 CRF++标准,格式如图2,其形
式为每行一个字符,后接其对应的实体类型标注。本数据集的标注分为四大类:包括人
名实体(PER)、地名实体(LOC)、机构名实体(ORG)以及其他非实体(O), 其中前
三种实体又分为实体头(B-实体)、实体剩余部分(I-实体),如图3。
(图2)
















- 1
- 2
前往页