


1、绪论
机器学习是从人工智能中产生的一个重要学科分支,是实现智能化的关键。
经典定义:利用经验改善系统自身的性能。
随着该领域的发展,目前主要研究(智能数据分析)的理论和算法,并已成为智
能数据分析技术的源泉之一。
机器学习源于“人工智能”,达特茅斯会议标志着人工智能这一学科的诞生。
人工智能的“三起三落”:
第一阶段:推理期(符号主义)
黄金十年(1956-1960s)
.符号主义成为主流
.启发式搜索成为基本方法
.定理证明、基于模板的对话机器人
第二阶段:知识期(专家系统)。专家系统=知识库+推理机
1970s-1980s:Knowledge Engineering
第三阶段:学习期(机器学习)
1990s-now:Machine Learning
机器学习是作为“突破知识工程瓶颈”之利器而出现的。
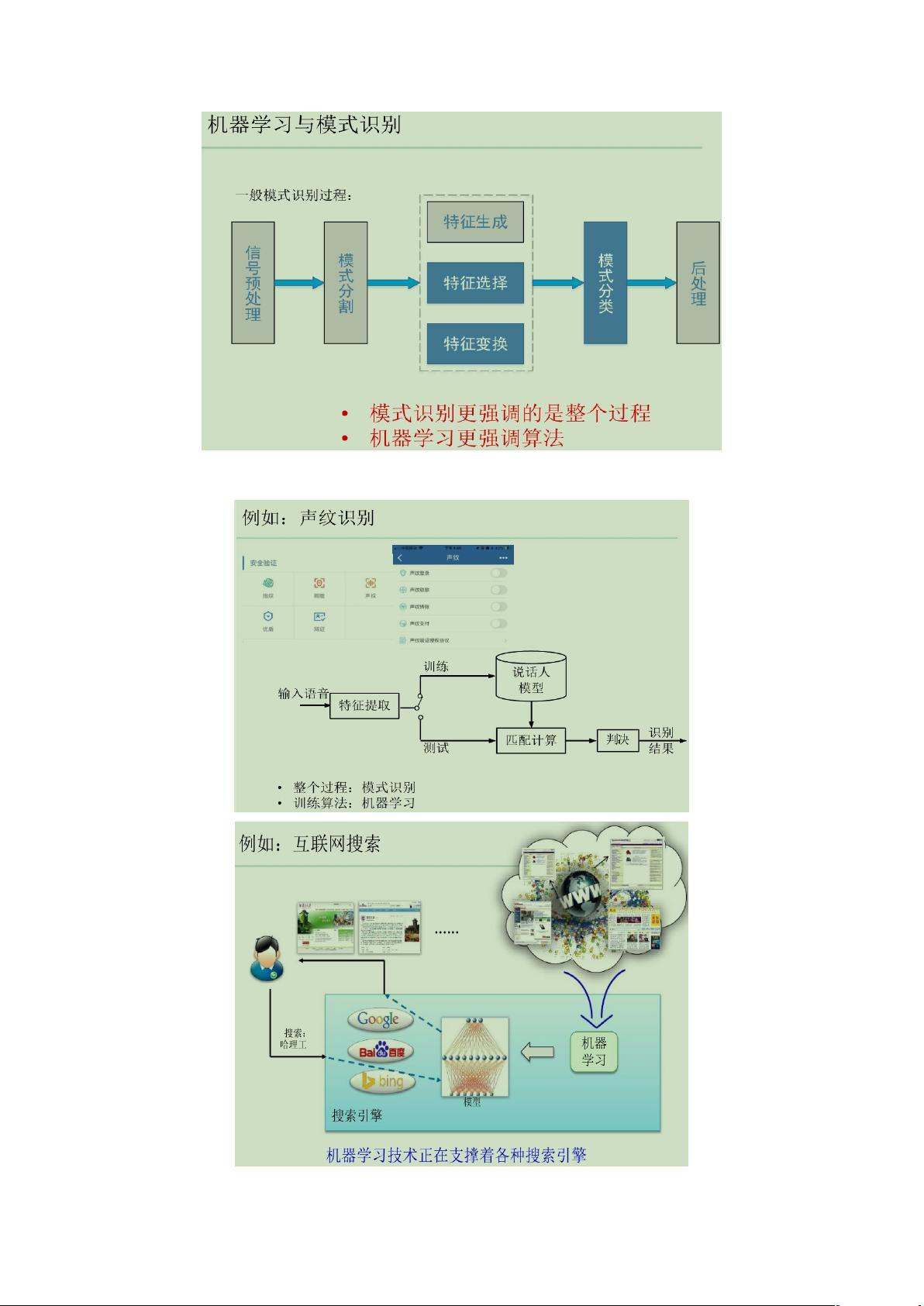
机器学习能做什么?(我们可能每天都在使用机器学习)

机器学习能做什么?
一般小规模的数据上就已经很有用。
例如:伪造语音检测(刑侦):判断语音是否为合成/盗录语音;
画作鉴别:确定作品的真伪。
大数据上更惊人:
帮助奥巴马胜选(政治)。
机器学习已“无处不在”:生物信息学;Web 搜索;入侵检测;汽车自动驾驶;
火星机器人;决策助手。
经常被谈到的 Deep Learning 仅是机器学习中的一个小分支。
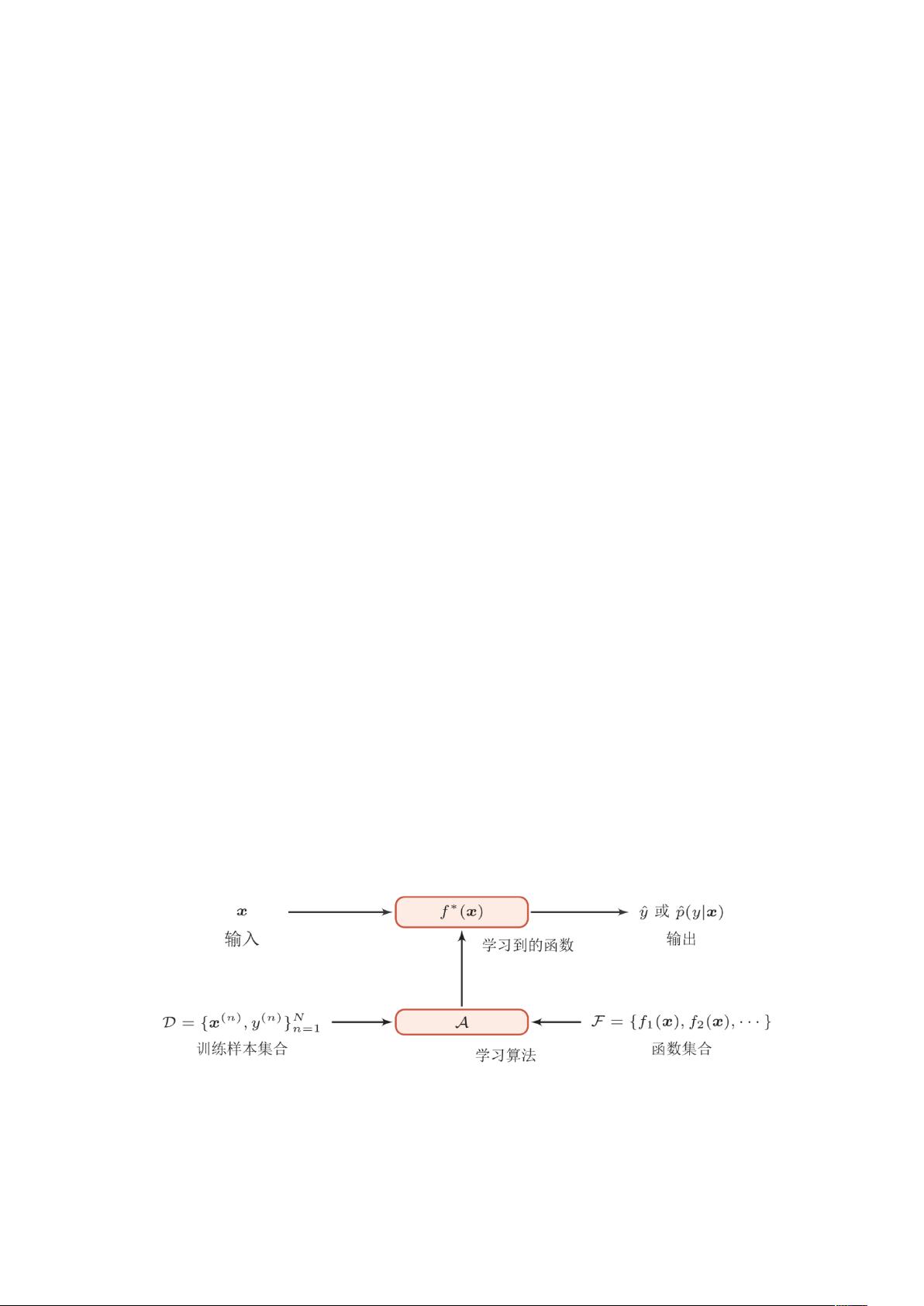
关于【假设空间】:
演绎:从一般到特殊的特化过程;
归纳:从特殊到一般的泛化过程;
假设空间:全部假设组成的空间;
学习过程:在所有假设(hypothesis)组成的空间中进行搜索的过程。
目标:找到与训练集“匹配”(fit)的假设。
版本空间(version space):即 与训练集一致的假设集合。
归纳偏好(inductive bias):机器学习算法在学习过程中对某种类型假设的偏
好。 对应有“奥卡姆剃刀原则”:如有多个假设与观察一致,则选择最简单的
那个。(任何一个有效的机器学习算法必有其偏好)
学习算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得
好的性能!
NFL 定理:一个算法 A 若在某些问题上比另一个算法 B 好,必存在另一些问题,
B 比 A 好。 该定理的重要前提:所有问题出现的机会相同、或所有问题同等重
要。
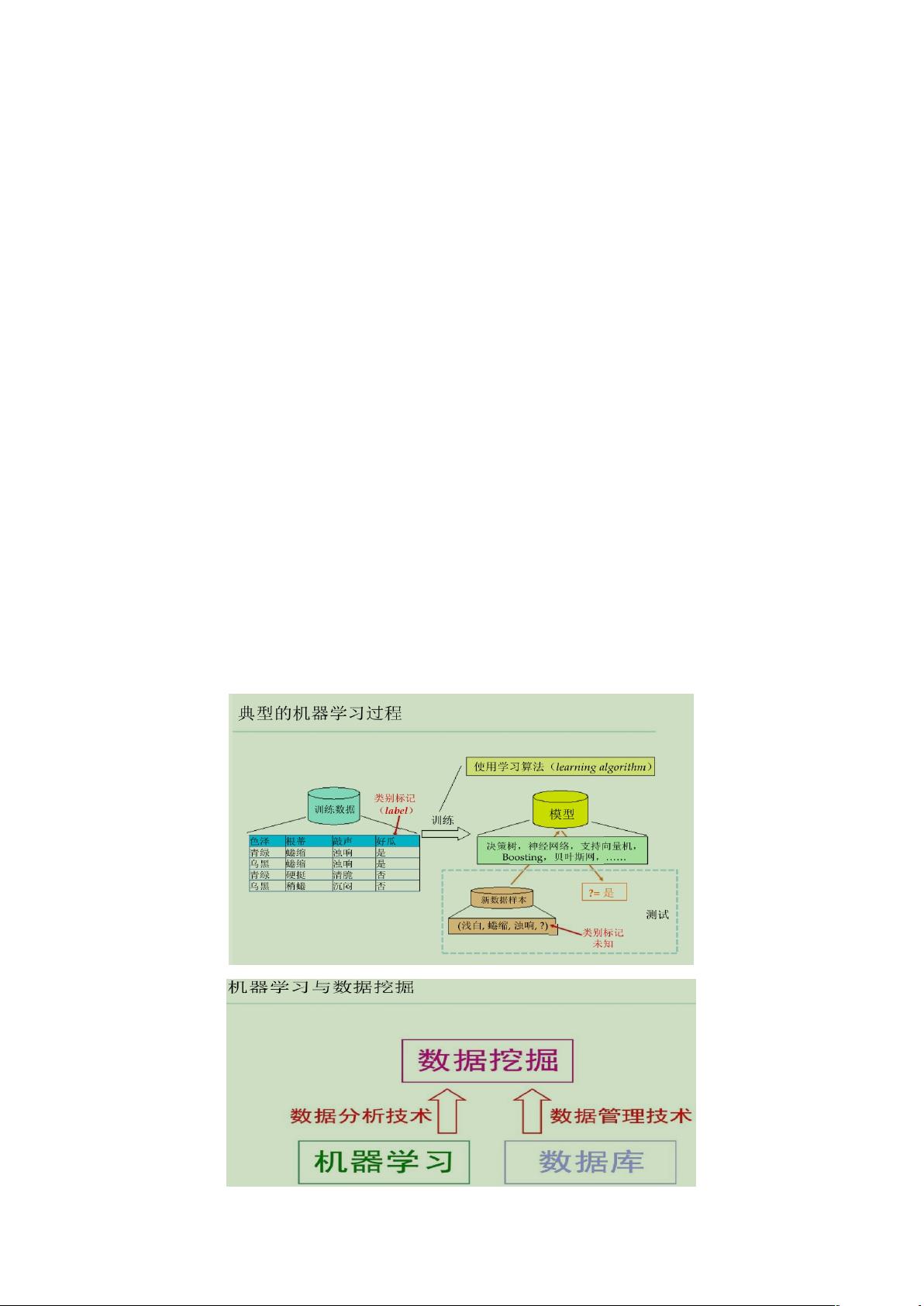
2、基本概念(理解 + 选择性记忆)
1.什么是监督学习和非监督学习,它们之间的区别有哪些?(适当记忆~)
监督学习,是指训练集的数据已经分好类别,通过对带有标签的数据进行学习,
来调整分类器的参数,使其达到所要求性能的过程。
常见的监督学习算法:逻辑回归、K 近邻、朴素贝叶斯、支持向量机。
非监督学习,需要将一系列没有标签和类别未知的数据,输入到算法中,需要根据样本
之间的相似性对样本集进行分类(聚类)试图使类内差距最小化,类间差距最大化。
常见的非监督学习算法:K-means、LDA。
二者的区别:
①监督学习必须要有训练集和测试集,非监督学习没有训练集,只有一组数据,在该数
据集内寻找规律。
②监督学习要求训练集必须由带标签的样本组成,非监督学习不要求数据样本带有标签。
③非监督学习是在寻找数据集中的规律性,但这种规律性并不一定要对数据进行分类。
2.解释分类、聚类、回归、损失函数(适当记忆~)
分类:根据一些给定的已知类别标号的样本,通过训练得到某种目标函数,使它能够对
未知类别的样本进行分类。
聚类:指事先并不知道任何样本的类别标号,希望通过某种算法来把一组未知类别的样
本划分成若干类别,这在机器学习中被称作无监督学习。
回归:用于预测输入变量和输出变量之间的关系,特别是当输入变量的值发生变化时,
输出变量的值随之发生的变化。
损失函数:用来估量模型的预测值 f(x)与真实值 Y 的不一致程度,它是一个非负实值函
数,通常使用 L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
3.什么是机器学习,机器学习的步骤是什么?
机器学习是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技
能,重新组织已有的知识结构使之不断改善自身性能的学科。
1 提出问题
2 采集数据、导入数据、查看数据信息
3 数据预处理、特征提取、特征选择
4 模型构建(建立训练数据集和测试数据集、选择机器学习算法、创建模型、训练模型) 5
评估模型 6 方案实施 7 报告撰写

4.什么是过拟合和欠拟合,产生的原因,以及解决办法(适当记忆~)
过拟合:在训练集上使用了一个非常复杂的模型,以至于这个模型在拟合训练集时表现
非常好,但是在测试集的表现非常差。
过拟合原因:训练数据集样本单一、训练样本噪音数据干扰过大、模型过于复杂。
过拟合解决办法:
①在训练和建立模型的时候,一定要从相对简单的模型开始,不要一上来就把模型调得
非常复杂、特征非常多。
②数据采样一定要尽可能地覆盖全部数据种类。
③在模型的训练过程中,我们也可以利用数学手段预防过拟合现象的发生,例如:可以
在算法中添加惩罚函数来预防过拟合。
欠拟合:如果模型过于简单,对于训练集的特点都不能完全考虑到的话,那么这样的模
型在训练集和测试集的表现都会非常的差。
欠拟合原因:模型复杂度过低、特征量过少
欠拟合解决办法:
①通过增加新特征来增大假设空间。
②添加多项式特征,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
③减少正则化参数。
④使用非线性模型,比如决策树、深度学习等模型。
⑤调整模型的容量,模型的容量是指其拟合各种函数的能力,容量低的模型可能很难拟
合训练集。
5.如何划分数据集以及评估方法有哪几种(适当记忆~)
评估方法就是进行划分数据集的,应该要求测试集与训练集之间互斥,用测试集来进行
模型预测,来评估模型的分类和性能能力。
留出法:就是将整个数据集 按照某种比例进行划分成训练集和测试集,要注意分层对
数据采样,多次重复划分,测试集最好保持在 20-30%的数据量上
交叉验证法:将全部数据集 D 分成 k 个不相交的子集,进行 k 次训练和测试,每次从
分好的子集中里面,拿出一个子集作为测试集,其它 k-1 个子集作为训练集,计算 k 次
测试结果的平均值,作为该模型的真实结果。留一法:是交叉验证法的一种,例如 D 中
有 m 个样本,令 k=m,则每个子集仅包含一个样本。适合小样本数据。
自助法:假定 D 中包含 m 个样本,通过对它进行采样产生数据集 D’,每次随机从 D 中
挑选一个样本,将其拷贝放入 D’中,然后再将该样本放回 D 中,这个过程重复 m 次,
则得到了包含 m 个样本的数据集 D’,可将 D’用在训练集,D\D’用作测试集。
6.最大似然估计(MLE)
在已经得到实验结果(样本)的情况下,估计满足这个样本分布的参数 θ,使这个样本出
现概率最大的参数 θ,作为真参数 θ 估计。即:模型已定,参数未知。要求所有的
采样都是独立同分布的。
求解过程:
1 由总体分布推导出样本的联合概率密度函数(或联合密度函数);
2 通过联合概率密度函数(或联合密度函数)得到似然函数 L(θ)。
3 对似然函数取对数,再求导,令导数为 0,得到似然方程,再计算极大值点,
若无法求导数时,要用极大似然原则来求解。













评论0