Bayes 和 KNN 分类器实现鸢尾花数据集分类
一、 问题描述
鸢尾花数据集是入门的经典数据集。Iris 数据集是常用的分类实验数据集,
由 Fisher, 1936 收集整理。Iris 也称鸢尾花卉数据集,是一类多重变量分析的
数据集。数据集包含 150 个样本,分为 3 类,每类 50 个数据,每个数据包含 4
个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度 4 个属性预测鸢尾花
卉属于(山鸢尾 Setosa,变色鸢尾 Versicolour,维吉尼亚鸢尾 Virginica)三
个种类中的哪一类。在三个类别中,其中有一个类别和其他两个类别是线性可分
的。假设鸢尾花数据集的各个类别是服从正态分布的,尝试利用贝叶斯决策论的
原理,
1. 设计贝叶斯分类器;
2. 设计基于最近邻准则的分类器。
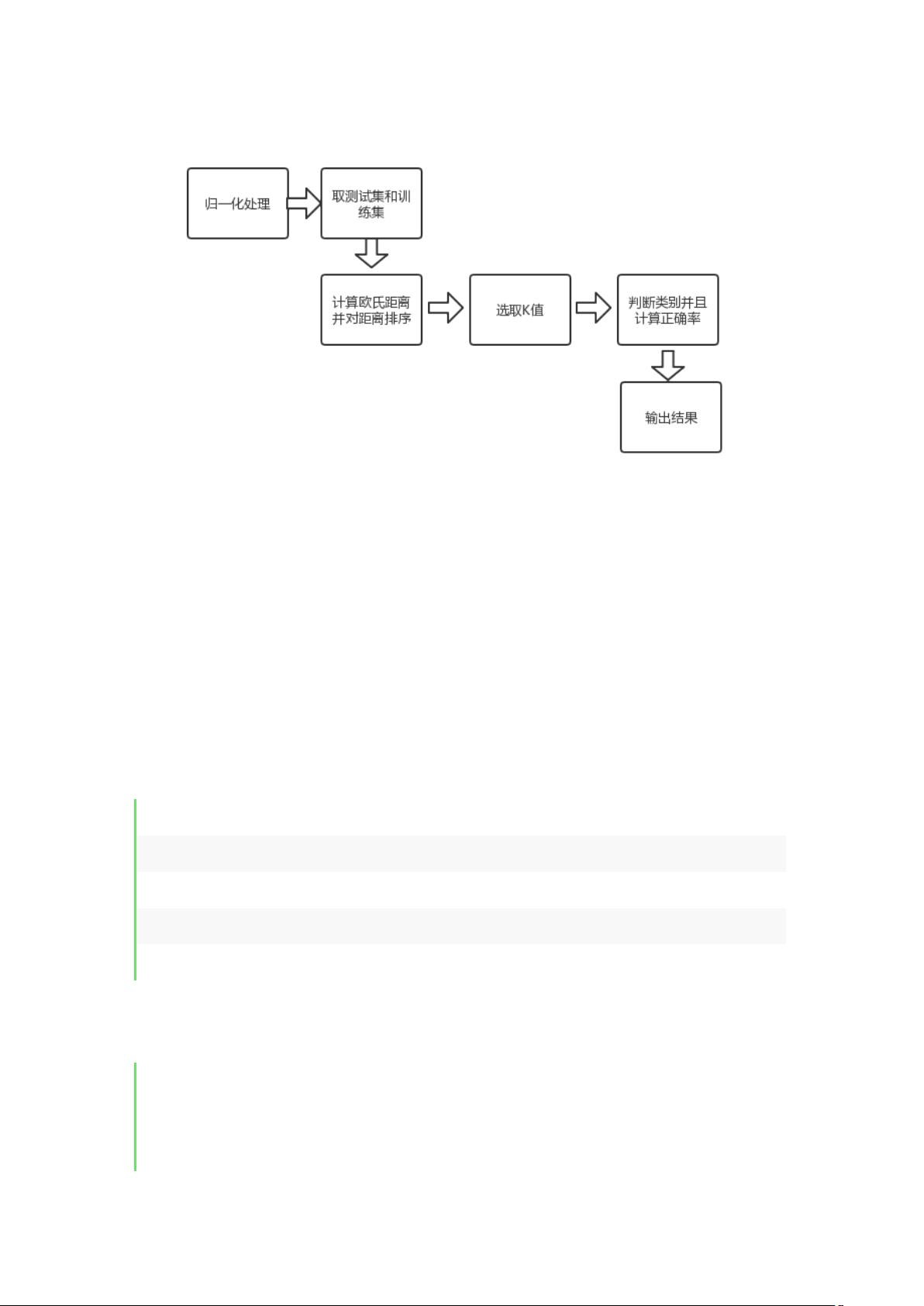
二、 数据预处理
(1)划分数据集
数据集一共分为四个变量,分别为:花萼长度、花萼宽度、花瓣长度、花瓣
宽度。 由数据集可以直观地看到 iris 数据集给出的三种花是按照顺序来的,前
50 个是第 0 类,51-100 是第 1 类,101~150 是第二类,分训练集和测试集时需
把顺序打乱。本次选取 120 个数据组为训练集,30 个为测试集。为实现随机性,
使用 random_state 随机形成模型训练数据和测试数据。
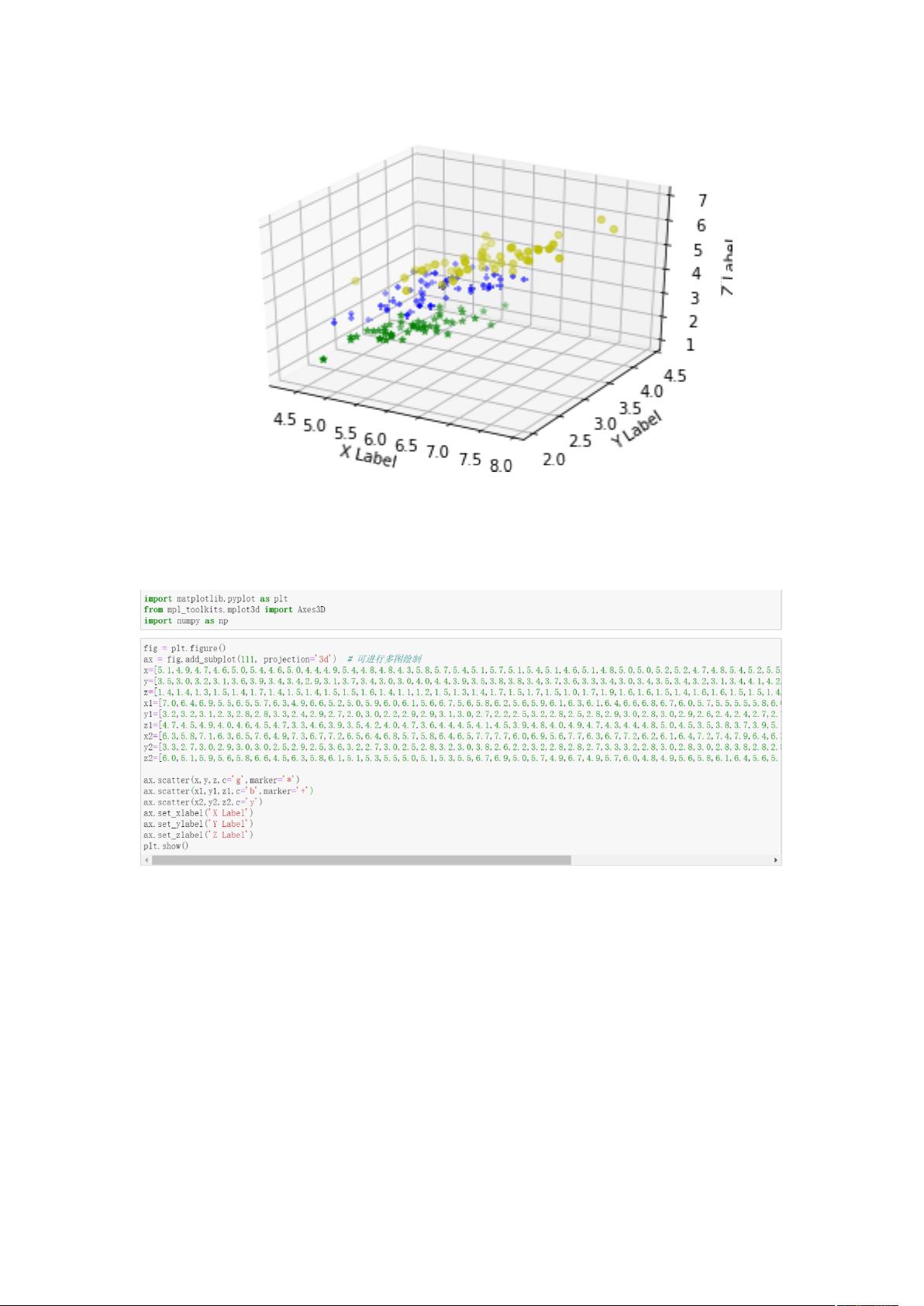
(2)数据可视化
由于花瓣宽度变化很小,将其省略后根据前三维数据画出散点图,如下所示: