数据结构中的排序算法是计算机科学中的重要概念,用于组织和优化数据存储,提高访问和处理效率。本文件主要探讨了两种常见的交换类排序方法:起泡排序和快速排序。
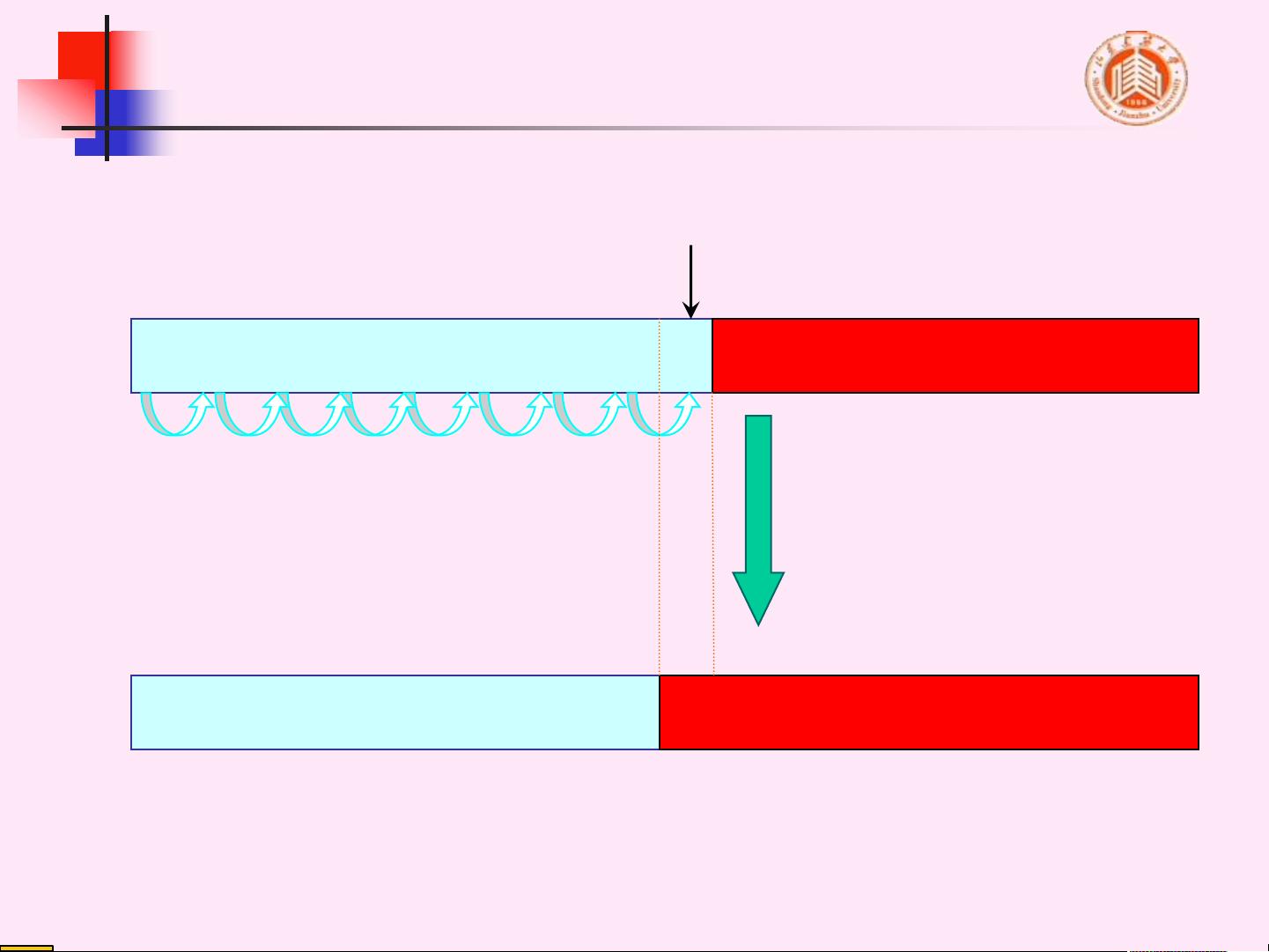
起泡排序是一种简单直观的排序算法,其基本思想是通过不断地交换相邻的、顺序错误的元素来逐步将最大或最小的元素“冒”到序列的末尾。具体步骤如下:
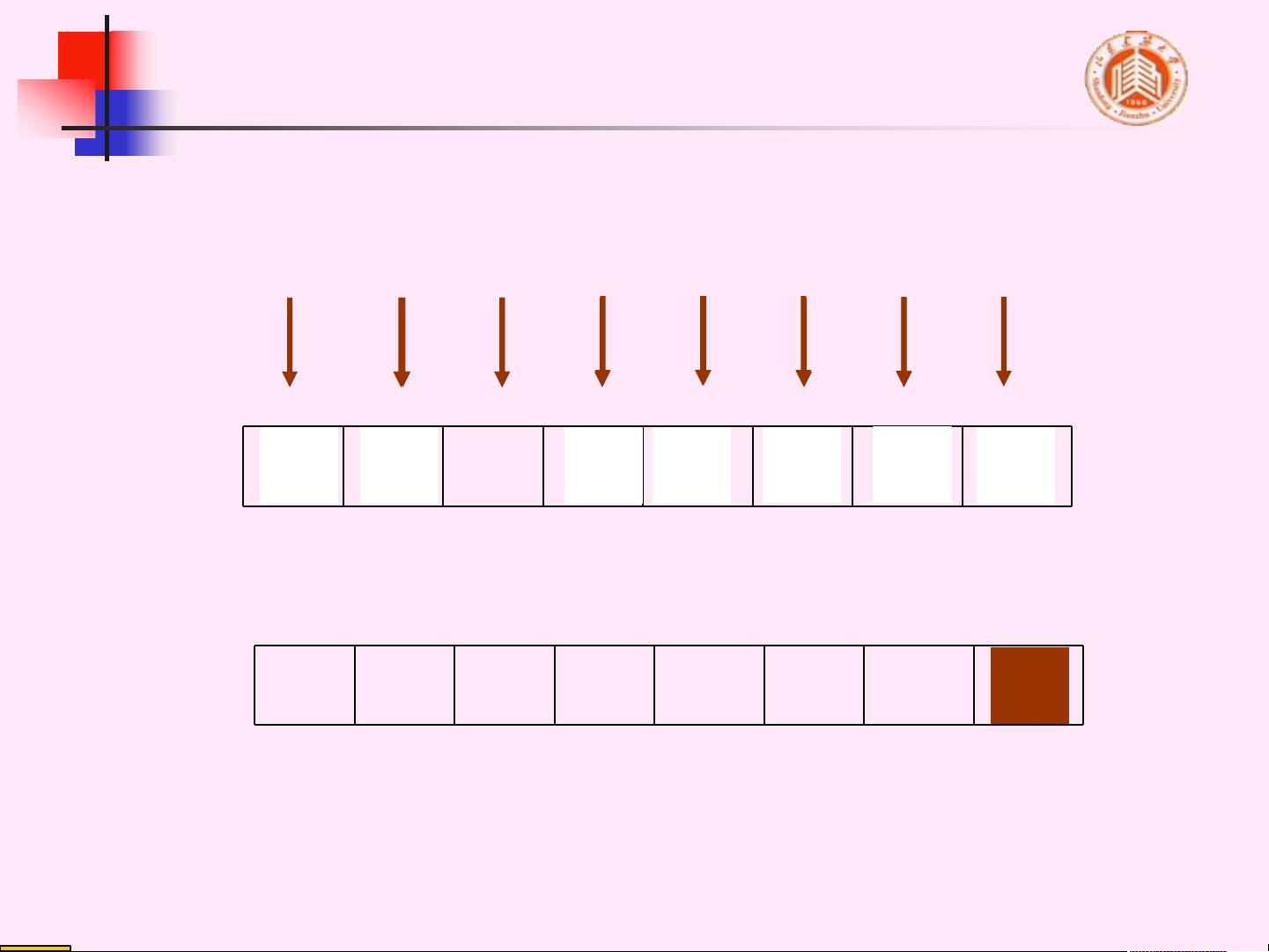
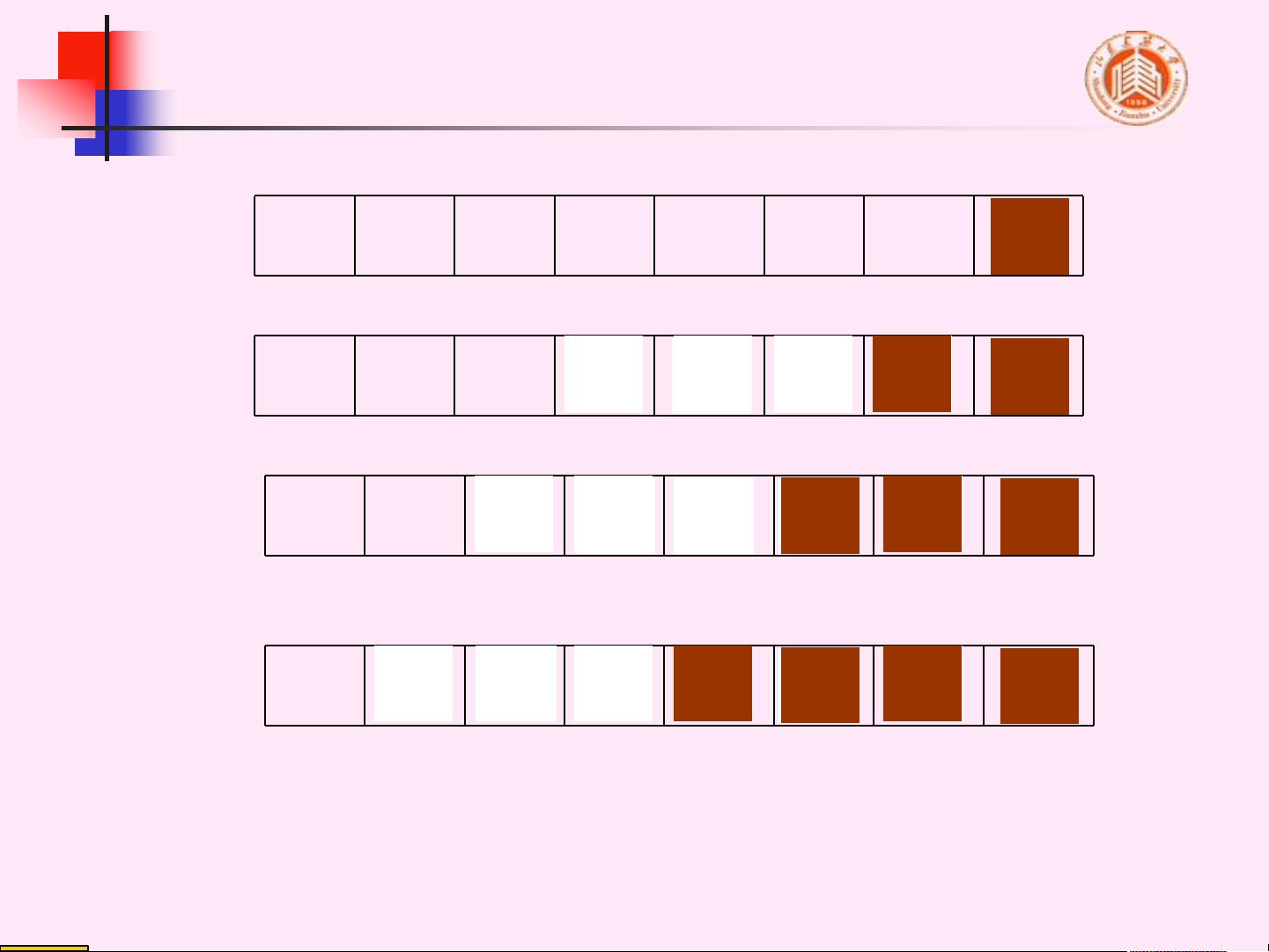
1. **起泡排序的过程**:起泡排序通过多趟比较和交换完成排序。在每趟排序中,会将当前未排序部分的最大元素(或最小元素)移动到已排序部分的末尾。在第 i 趟排序后,序列的前 n-i+1 个元素会是有序的,而后面的元素则保持原样。
2. **起泡排序的示例**:文档中给出了一个976576 13273049等元素的起泡排序过程,通过多趟交换,最终将序列排序为13273049。每次比较相邻两个元素,如果顺序错误则交换,较大的元素逐渐“浮”到序列末尾。
3. **起泡排序的代码实现**:文档中给出了C语言实现的起泡排序函数`BubbleSort()`,使用了一个while循环和一个for循环,每次遍历序列并检查相邻元素是否需要交换。`lastExchangeIndex`变量用来记录最后一次交换的位置,以优化不必要的比较。
4. **起泡排序的性能分析**:起泡排序的时间复杂度在最好情况下(即输入序列已经有序)为O(n),而在最坏情况下(输入序列完全逆序)为O(n^2)。由于起泡排序总是进行n-1次比较,因此即使是最好情况下的比较次数也是线性的。
快速排序是另一种高效的交换类排序算法,由C.A.R. Hoare在1960年提出。它的核心是分治策略,通过选取一个“基准”元素,将序列划分为两部分,使得一部分的所有元素都小于基准,另一部分的所有元素都大于基准,然后递归地对这两部分进行快速排序。
1. **快速排序的基本思想**:快速排序的关键操作是“分区”(partition),它将序列分为两部分,并确保基准元素位于最终排序后的正确位置。之后对左右两部分分别进行快速排序。
2. **快速排序的步骤**:选择一个元素作为“基准”,如第一个元素;通过一趟扫描将所有小于基准的元素移到其左边,大于基准的元素移到右边;对基准左右两边的子序列分别进行快速排序。
3. **快速排序的性能**:快速排序的平均时间复杂度为O(n log n),最坏情况同样为O(n^2),但这种情况在实际应用中很少发生,因为可以采用随机化策略选择基准,避免最坏情况。
总结,起泡排序适合于小型数据集或者已经部分有序的数据,而快速排序通常在大多数情况下表现更优,尤其是对于大规模数据。在实际编程中,快速排序由于其高效的平均性能和较低的空间复杂度,被广泛应用于各种场景。然而,了解和掌握多种排序算法可以帮助我们根据具体需求选择最适合的解决方案。