
数据结构(2)
数据结构
1.试写一算法,实现单链表的就地逆置(要求在原链表上进行)。
void converse(NODEPTR L)
{
NODEPTR p,q;
P=L ->next; q=p ->next;
L ->next=NULL;
while(p) /*对于当前结点 p,用头插法将结点 p 插入到头结点之后*/
{
p ->next=L ->next;
L ->next= p;
p=q;
q=q ->next;
}
}
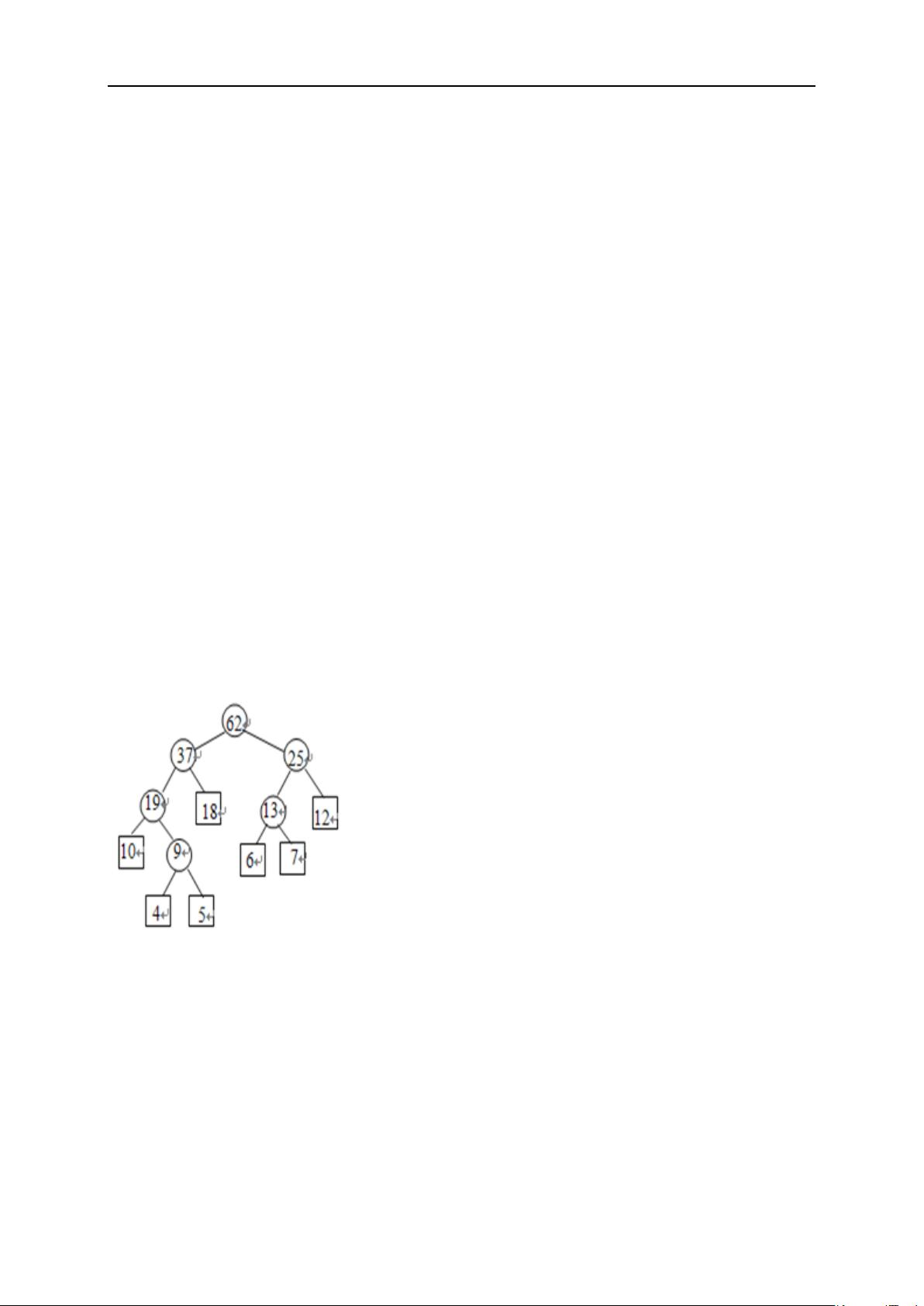
2.以数据集{4,5,6,7,10,12,18}为结点权值,画出构造的哈弗曼树,计算其带权路径长
度。
其带权路径长度为 62
3. 假 设 一 棵 二 叉 树 如 下 图 所 示 , 求 :
资源评论


是空空呀
- 粉丝: 197
- 资源: 3万+









最新资源
- 数据分析-09-学生校园消费分析(包含数据和代码)
- 基于微信小程序的社区垃圾回收管理系统ssm.zip
- 基于微信平台的购物商城小程序开发ssm.zip
- 高校学习助手小程序ssm.zip
- 基于一份网易云音乐数据集,使用python对该该数据集进行数据清洗,包括缺失值处理、异常值检测和处理、重复值处理、数据类型转换、统一化数据格式、数据一致性处理、数据采样、特征工程等
- 运动健康小程序SpringBoot.zip
- 学生管理系统springboot.zip
- 基于JAVA的微信食堂线上订餐小程序的设计与实现ssm.zip
- 机械设计薄膜铝箔袋连续封口机770标准机sw17可编辑非常好的设计图纸100%好用.zip
- 基于微信小程序的快递管理平台的设计与实现ssm.zip
- 基于微信小程序的校园保修系统springboot.zip
- 基于微信小程序的社区车位租赁系统的设计与实现springboot.zip
- 便捷饭店点餐小程序的设计与实现ssm.zip
- 基于springboot+vue的保险业务管理系统源码+数据库+文档说明(毕业设计)
- Java毕业设计-基于springboot+vue的保险业务管理系统源码+数据库+文档说明
- upload - labs 通关手册
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


