深度学习后端架构选型及其应用场景选择
需积分: 0 8 浏览量
2024-03-29
10:00:37
上传
评论
收藏 4.37MB PDF 举报


第十八章 后端架构选型及应用场景
18.1 为什么需要分布式计算?
18.2 目前有哪些深度学习分布式计算框架?
18.2.1 PaddlePaddle
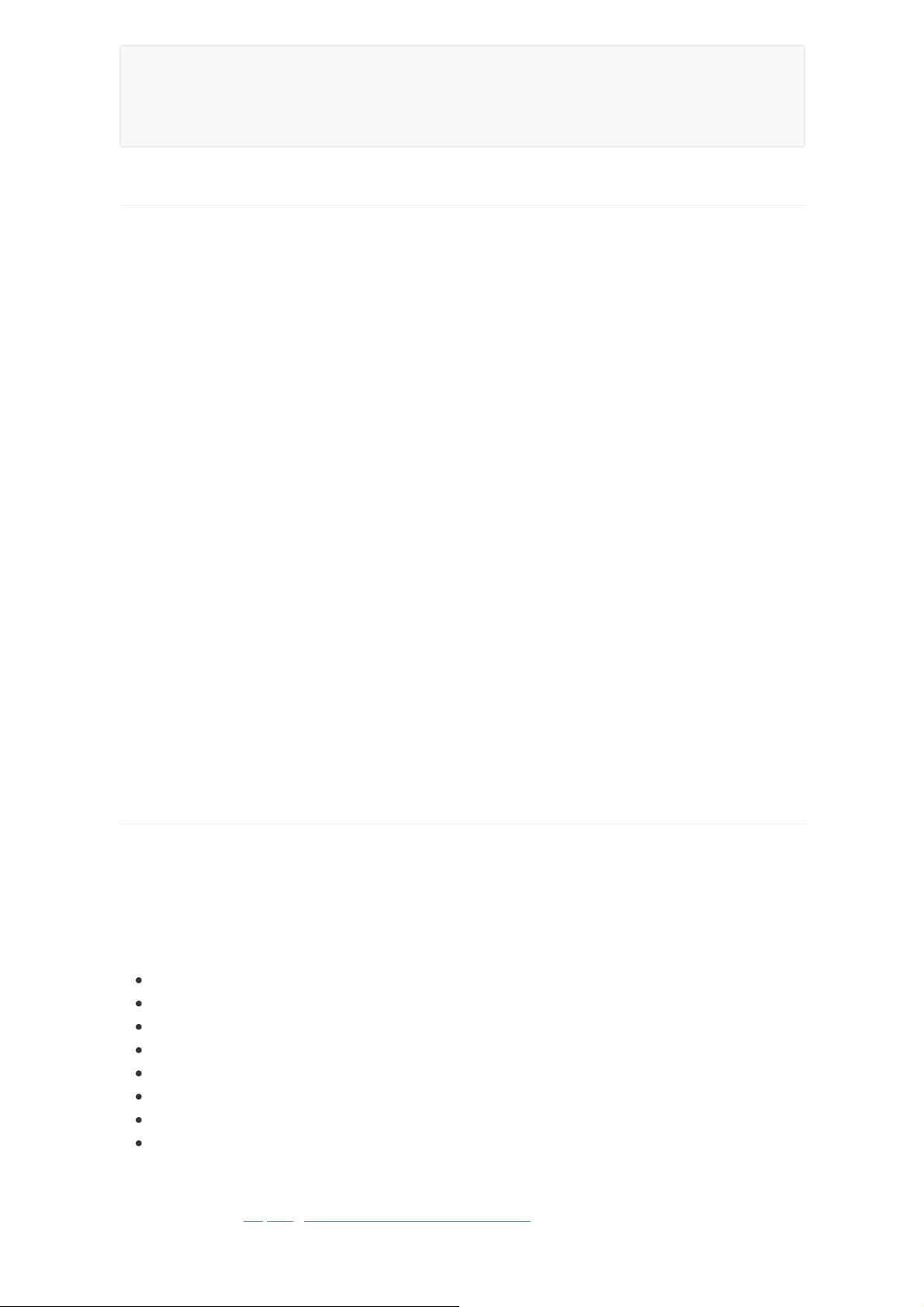
18.2.2 Deeplearning4j
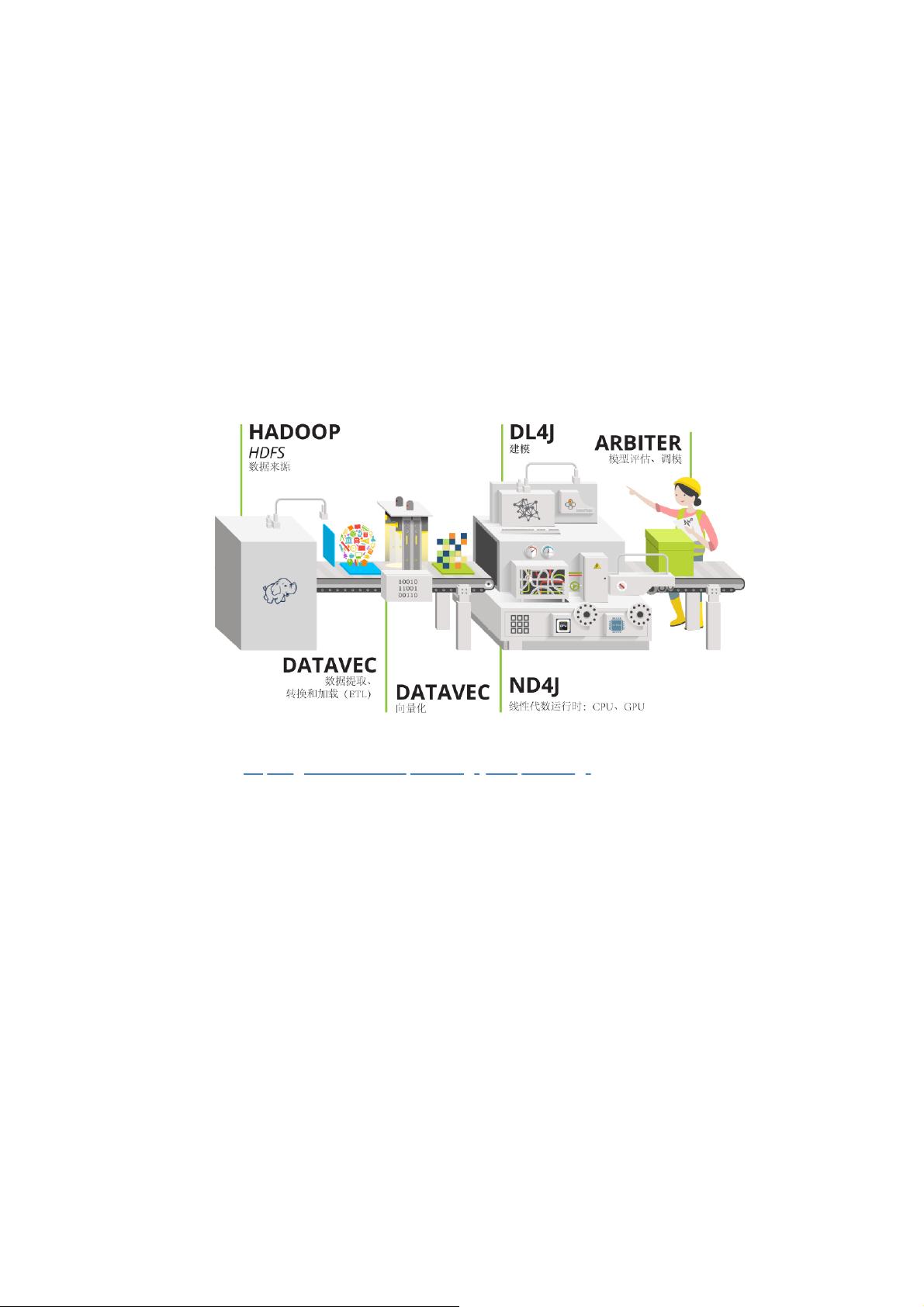
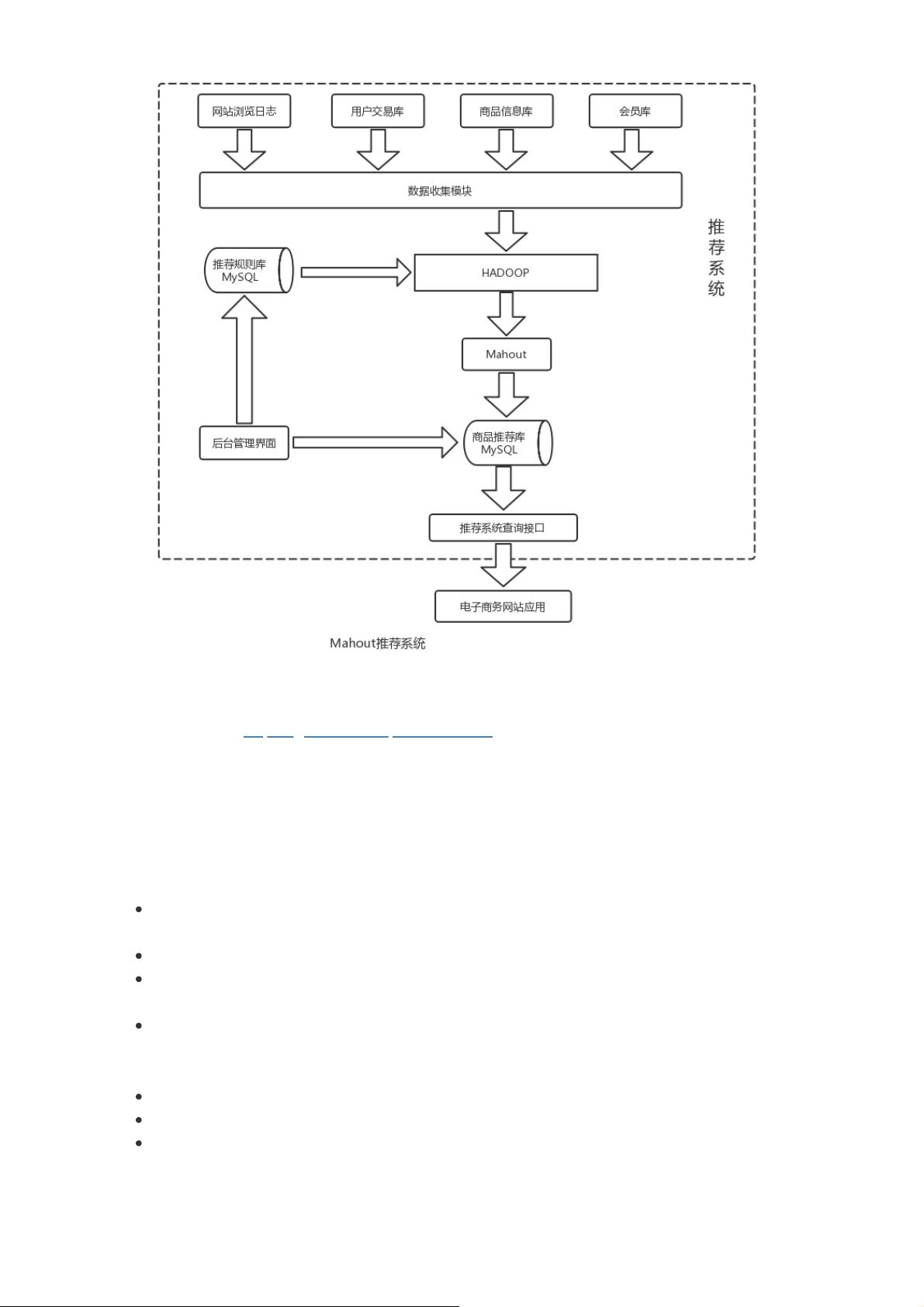
18.2.3 Mahout
18.2.4 Spark MLllib
18.2.5 Ray
18.2.6 Spark stream
18.2.7 Horovod
18.2.8 BigDL
18.2.9 Petastorm
18.2.10 TensorFlowOnSpark
18.3 如何进行实时计算?
18.3.1 什么是实时流计算?
18.3.2 实时流计算过程
18.4 如何进行离线计算?
18.4.1 数据采集
18.4.2 数据预处理
18.4.3 数据建模
18.4.4 ETL
18.4.5 数据导出
18.4.6 工作流调度
18.5 如何设计一个人机交互系统?
18.5.1 什么是人机交互系统?
18.5.2 如何设计人机交互系统的问答引擎算法架构?
18.5.3 如何处理长难句?
18.5.4 如何纠错?
18.5.5 什么是指代消解?如何指代消解?
18.5.6 如何做语义匹配?
18.5.7 如何在海量的向量中查找相似的TopN向量?
18.5.8 什么是话术澄清?
18.5.9 如何对结果进行排序打分?
18.5.10 如何评估人机交互系统的效果?
18.6 如何设计个性化推荐系统?
18.6.1 什么是个性化推荐系统?
18.6.2 如何设计个性化推荐系统的推荐引擎架构?
18.6.3 召回模块
18.6.4 排序模块
18.6.5 离线训练
18.6.6 用户画像
18.6.7 GBDT粗排
18.6.8 在线FM精排
18.6.9 算法介绍
18.6.10 如何评价个性化推荐系统的效果?
18.6.11 个性化推荐系统案例分析
18.7 参考文献
第十八章 后端架构选型及应用场景

剩余54页未读,继续阅读
资源评论













