机器学习数学基础:线性代数+微积分+概率统计+优化算法 矩阵运算助力特征提取,导数分析优化模型性能,概率评估数据分布,优化算法寻
需积分: 0 76 浏览量
2024-03-20
19:27:01
上传
评论
收藏 852KB PDF 举报

###
第一章 数学基础
1.1 向量和矩阵
1.1.1 标量、向量、矩阵、张量之间的联系
1.1.2 张量与矩阵的区别
1.1.3 矩阵和向量相乘结果
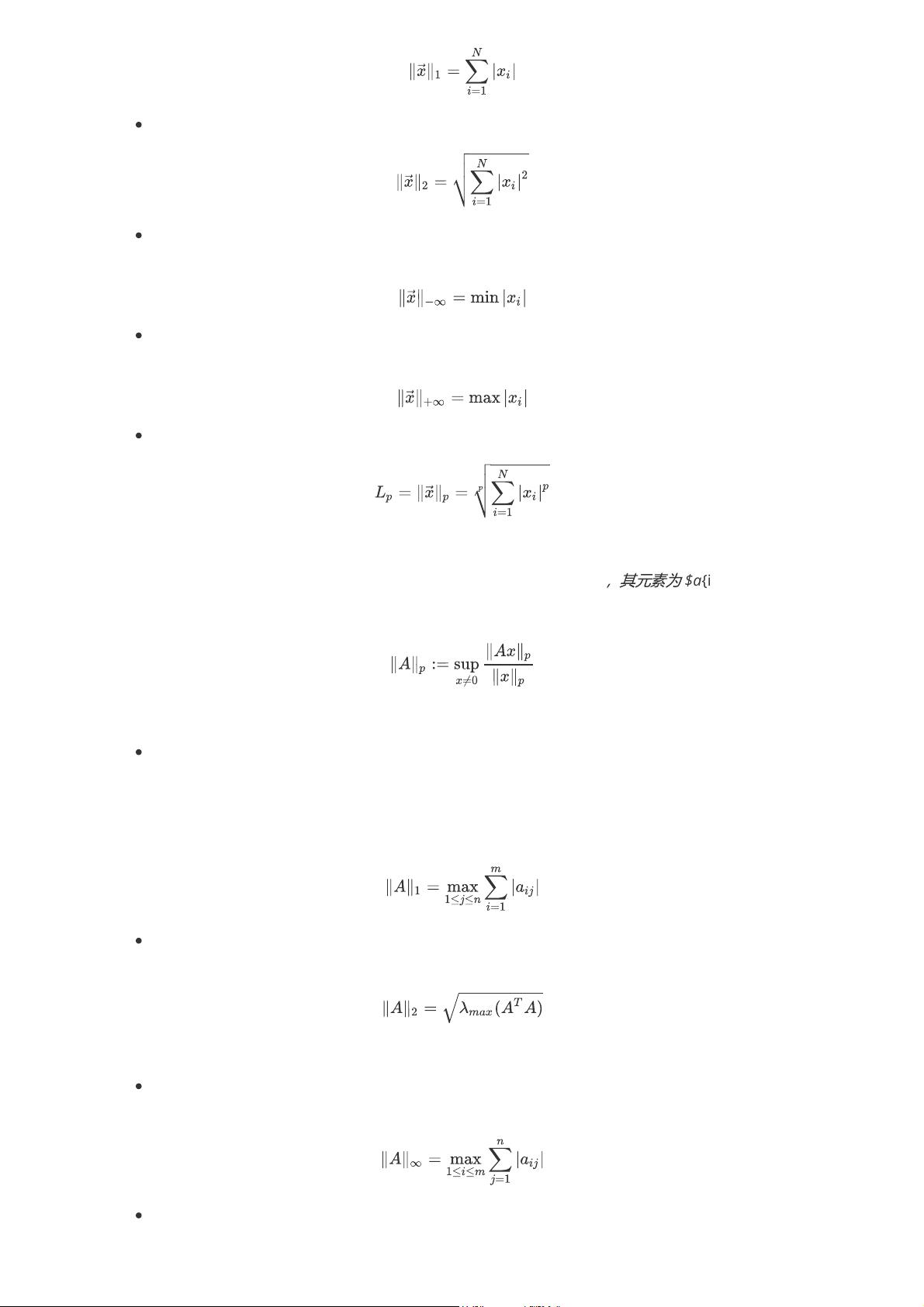
1.1.4 向量和矩阵的范数归纳
1.1.5 如何判断一个矩阵为正定
1.2 导数和偏导数
1.2.1 导数偏导计算
1.2.2 导数和偏导数有什么区别?
1.3 特征值和特征向量
1.3.1 特征值分解与特征向量
1.3.2 奇异值与特征值有什么关系
1.4 概率分布与随机变量
1.4.1 机器学习为什么要使用概率
1.4.2 变量与随机变量有什么区别
1.4.3 随机变量与概率分布的联系
1.4.4 离散型随机变量和概率质量函数
1.4.5 连续型随机变量和概率密度函数
1.4.6 举例理解条件概率
1.4.7 联合概率与边缘概率联系区别
1.4.8 条件概率的链式法则
1.4.9 独立性和条件独立性
1.5 常见概率分布
1.5.1 Bernoulli分布
1.5.2 高斯分布
1.5.3 何时采用正态分布
1.5.4 指数分布
1.5.5 Laplace 分布
1.5.6 Dirac分布和经验分布
1.6 期望、方差、协方差、相关系数
1.6.1 期望
1.6.2 方差
1.6.3 协方差
1.6.4 相关系数
参考文献
第一章 数学基础
深度学习通常又需要哪些数学基础?深度学习里的数学到底难在哪里?通常初学者都会有这些问题,在
网络推荐及书本推荐里,经常看到会列出一系列数学科目,比如微积分、线性代数、概率论、复变函
数、数值计算、优化理论、信息论等等。这些数学知识有相关性,但实际上按照这样的知识范围来学
习,学习成本会很久,而且会很枯燥,本章我们通过选举一些数学基础里容易混淆的一些概念做以介
绍,帮助大家更好的理清这些易混淆概念之间的关系。
1.1 向量和矩阵

剩余11页未读,继续阅读
资源评论













