目标检测是计算机视觉领域中的一项核心技术,它结合了深度学习技术来识别和定位图像或视频中的多个对象
需积分: 0 77 浏览量
2024-03-18
22:28:38
上传
评论
收藏 11.84MB PDF 举报

第八章 目标检测
8.1 基本概念
8.1.1 什么是目标检测?
8.1.2 目标检测要解决的核心问题?
8.1.3 目标检测算法分类?
8.1.4 目标检测有哪些应用?
8.2 Two Stage目标检测算法
8.2.1 R-CNN
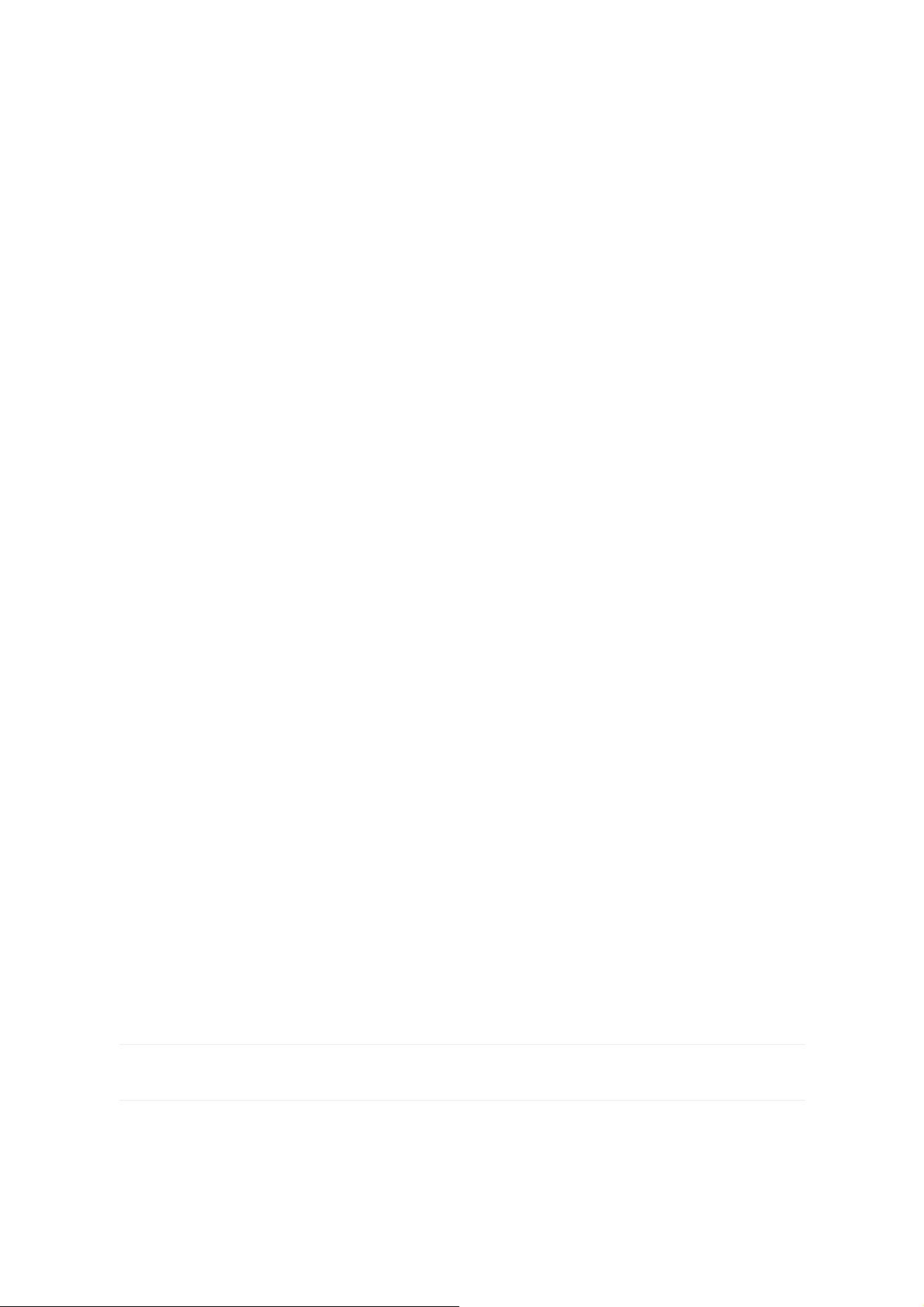
8.2.2 Fast R-CNN
8.2.3 Faster R-CNN
8.2.4 R-FCN
8.2.5 FPN
8.2.6 Mask R-CNN
8.3 One Stage目标检测算法
8.3.1 SSD
8.3.2 DSSD
8.3.3 YOLOv1
8.3.4 YOLOv2
8.3.5 YOLO9000
8.3.6 YOLOv3
8.3.7 RetinaNet
8.3.8 RFBNet
8.3.9 M2Det
8.4 人脸检测
8.4.1 目前主要有人脸检测方法分类?
8.4.2 如何检测图片中不同大小的人脸?
8.4.3 如何设定算法检测最小人脸尺寸?
8.4.4 如何定位人脸的位置?
8.4.5 如何通过一个人脸的多个框确定最终人脸框位置?
8.4.6 基于级联卷积神经网络的人脸检测(Cascade CNN)
8.4.7 基于多任务卷积神经网络的人脸检测(MTCNN)
8.4.8 Facebox
8.5 目标检测的技巧汇总
8.6 目标检测的常用数据集
8.6.1 PASCAL VOC
8.6.2 MS COCO
8.6.3 Google Open Image
8.6.4 ImageNet
TODO
参考文献
第八章 目标检测
8.1 基本概念
8.1.1 什么是目标检测?
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和
位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光
照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。



剩余52页未读,继续阅读
资源评论


fighting的码农(zg)-GPT
- 粉丝: 345
- 资源: 34









最新资源
- 5uonly.apk
- 2023-04-06-项目笔记 - 第一百十九阶段 - 4.4.2.117全局变量的作用域-117 -2024.04.30
- 2023-04-06-项目笔记 - 第一百十九阶段 - 4.4.2.117全局变量的作用域-117 -2024.04.30
- 前端开发技术实验报告:内含4四实验&实验报告
- Highlight Plus v20.0.1
- 林周瑜-论文.docx
- 基于MIC+NE555光敏电阻的声光控电路Multisim仿真原理图
- 基于JSP毕业设计-基于WEB操作系统课程教学网站的设计与实现(源代码+论文).zip
- 基于LM324和LM386的音响放大器Multisim仿真+PCB电路原理图
- Python机器学习与数据挖掘环境配置与库验证
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


