


YOLOv1论⽂详解【算法原理、置信度、IOU、损失函数等】
YOLOv1
从R-CNN到Faster R-CNN⼀直采⽤的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很⾼,但由于
two-stage(proposal耗费时间过多)处理速度不⾏达不到real-time效果。
(R-CNN use region proposal methods to first generate potential bounding boxes in an image and then run a classifier
on these proposed boxes.)
YOLO提供了另⼀种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为⽹络的输⼊,把
Object Detection 的问题转化成⼀个 Regression 问题)。
YOLO v1
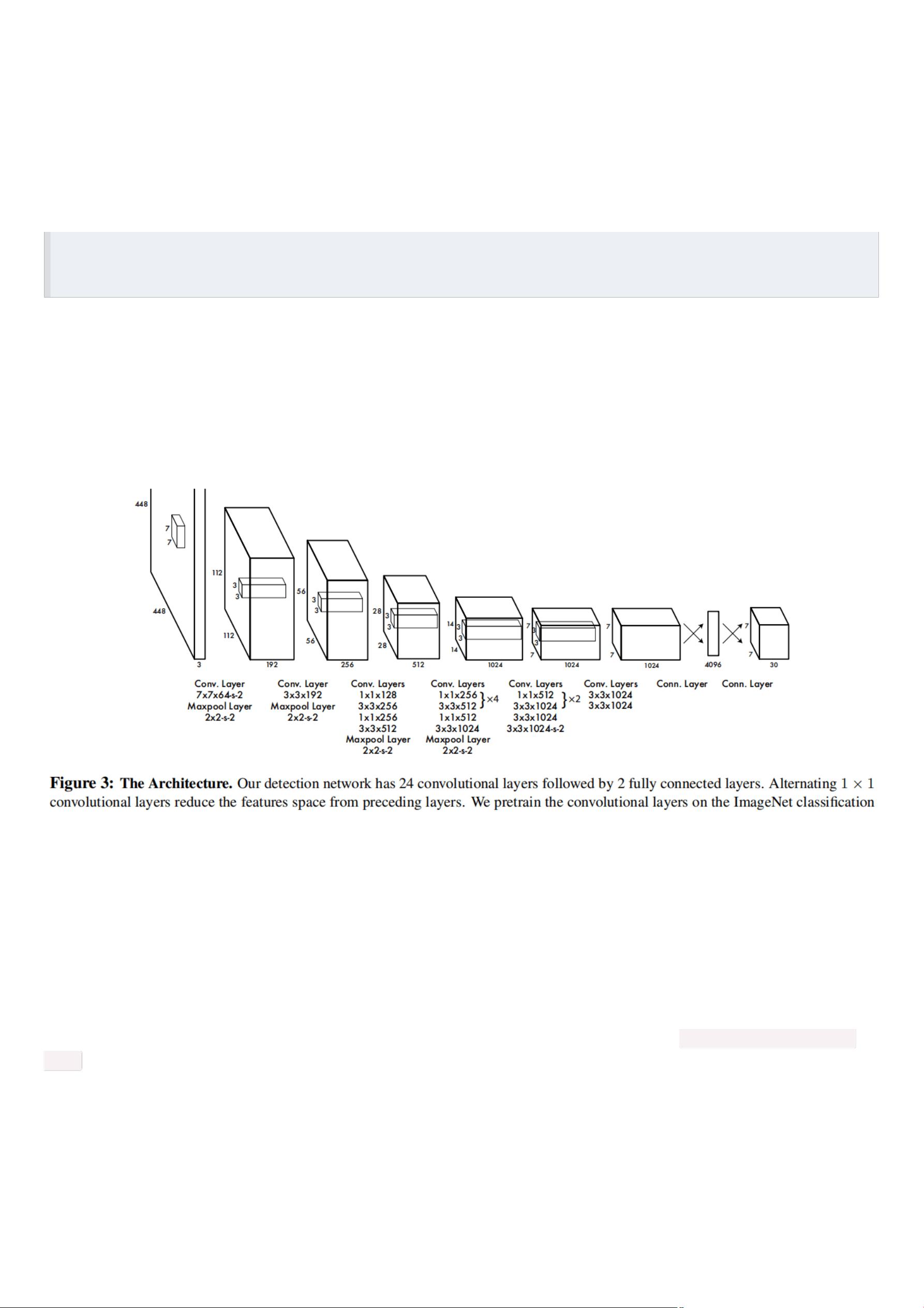
⽹络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(⽤1×1 reduction layers 紧跟 3×3 convolutional layers 取代
GoogleNet的 inception modules )。
The final output of our network is the 7 × 7 × 30 tensor of predictions.
优点
1.由于整个检测管道是单个⽹络,因此可以直接根据检测性能进⾏端到端优化。
2.与基于滑动窗⼝和基于区域提案的技术不同,YOLO在训练和测试期间可以看到整个图像,因此它可以隐式地编码有关类及其外观的上下
⽂信息。
算法原理
1.在YOLOv1中作者将⼀幅图⽚分成7x7个⽹格(grid cell),由⽹络的最后⼀层输出7×7×30的tensor,
也就是说每个格⼦输出1×1×30的
tensor
。30⾥⾯包括了2个bounding box的x,y,w,h,confidengce以及针对格⼦⽽⾔的20个类别概率,输出就是 7x7x(5x2 + 20)
。(通⽤公式: SxS个⽹格,每个⽹格要预测B个bounding box还要预测C个categories,输出就是S x S x (5×B+C)的⼀个tensor。 注
意:class信息是针对每个⽹格的,confidence信息是针对每个bounding box的),如Figure 2: The Model所⽰。
















