
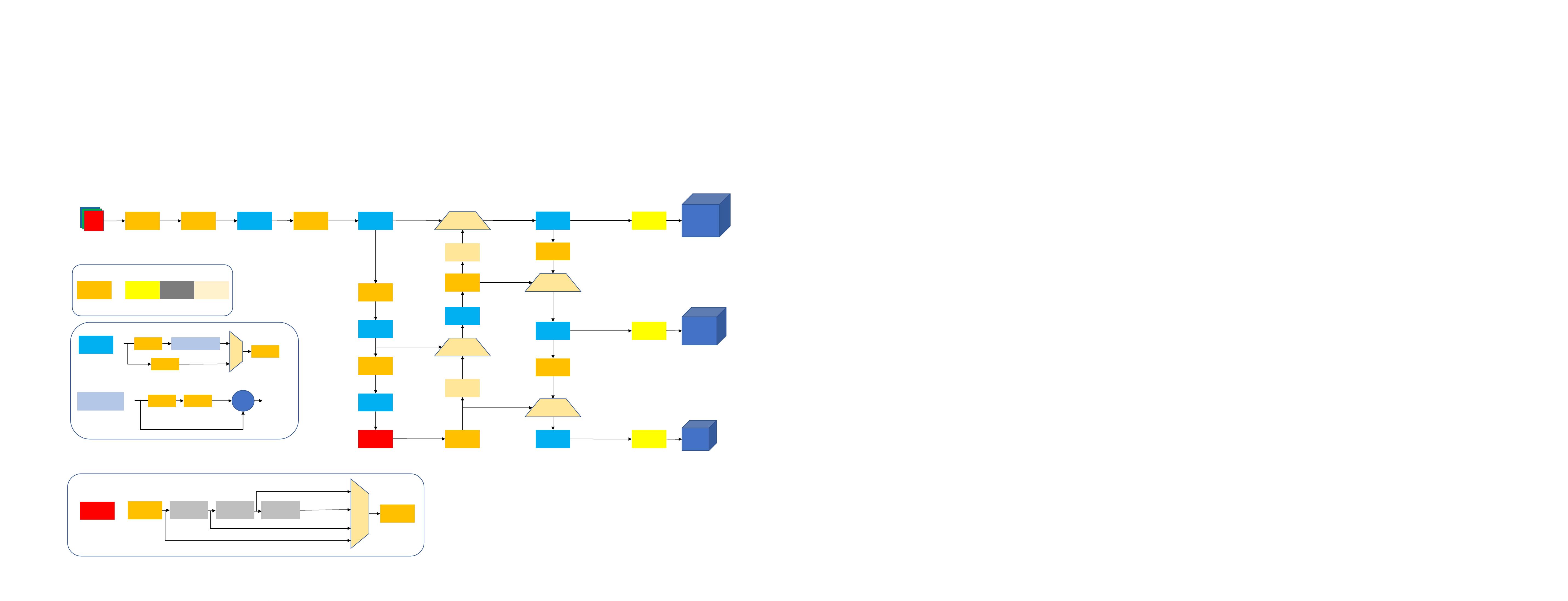
C3CBS CBS
CBS
C3
CBS
C3
CBS
C3
SPPF
3 x 640 x 640
1024 x 20 x 20
128 x 160 x 160
128 x 160 x 160
256 x 80 x 80
256 x 80 x 80
256 x 80 x 80
512 x 40 x 40
64 x 320 x 320
1024 x 20 x 20
C3
C3
Up
Sample
Concat
CBS
CBS
Up
Sample
Concat
CBS
Concat
C3
CBS
Concat
C3
1024 x 20 x 20
512 x 20 x 20
512 x 40 x 40
1024 x 40 x 40
512 x 40 x 40
256 x 40 x 40
256 x 80 x 80
512 x 80 x 80
256 x 80 x 80
256 x 80 x 80
256 x 40 x 40
512 x 40 x 40
512 x 40 x 40
512 x 40 x 40
512 x 20 x 20
1024 x 20 x 20
1024 x 20 x 20
Conv
BN
SiLU
=
CBS
SPPF
=
Concat
CBS
CBS
MaxPool
MaxPool MaxPool
C3
CBS BottleNeck
Concat
=
CBS
CBS
BottleNeck
=
CBS CBS
add
Conv
Conv
Conv
255 x 80 x 80
255 x 40 x 40
255 x 20 x 20
512 x 40 x 40
资源评论

 书家小子2024-10-17画的真的可以。
书家小子2024-10-17画的真的可以。

Major-TomC
- 粉丝: 1
- 资源: 10









最新资源
- ShellTransition学习笔记
- 5G+AI智慧高校大数据顶层规划设计及应用方案(67页PPT).pptx
- 基于PWM的 三色灯RGB模块调色 标准库 代码
- 基于Simulink仿真的光储并网直流微电网模型研究:MPPT最大功率输出与混合储能系统的协同优化,基于Simulink仿真的光储并网直流微电网模型研究:MPPT最大功率输出与混合储能系统的协同优化
- JAVA实现有趣的迷宫小游戏(附源码).zip
- 基于NRBO-Transformer-BILSTM的深度学习模型:多特征分类预测与性能评估的Matlab实现,基于NRBO-Transformer-BILSTM的多特征分类预测模型与性能评估的Matl
- 磁链观测器在VESC中的应用方法及其代码、文档、仿真模型的对应关系以及附送翻译的Lawicel CANUSB驱动,磁链观测器在VESC中的应用:实现0速闭环启动,代码、文档、仿真模型供学习,磁链观测器
- 基于多智能体一致性算法的电力系统分布式经济调度策略:迭代优化与仿真验证,基于多智能体一致性算法与迭代计算的电力系统分布式经济优化调度策略(MATLAB实现),MATLAB代码基于多智能体系统一致性算
- 2013.8.5-2025.3.5碳排放权交易数据(日度).xlsx
- 中断上下文详细解析PDF详细内容
- VC-redist.x64-14.42.34438.0.7z
- MATLAB实现基于BiGRU-AdaBoost双向门控循环单元结合AdaBoost多输入分类预测(含模型描述及示例代码)
- Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)(含模型描述及示例代码)
- MATLAB实现SSA-CNN-BiLSTM-Attention多变量时间序列预测(SE注意力机制)(含模型描述及示例代码)
- 基于磁耦合谐振的无线电能传输设计:MATLAB仿真中的PWM控制与过零检测模块探讨及二极管与同步整流技术的结合应用 ,基于Matlab Simulink仿真的无线电能传输设计:磁耦合谐振与PWM MO
- 博图16立体车库控制系统:PLC运行效果视频展示与接线图详解,深度解析:4x5立体车库控制系统的博图16版本,含PLC运行效果视频、详细接线图及IO表,4x5立体车库控制系统 博图16 带PLC运行效
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


