



1、找到pip3.exe所在的文件夹,复制路径
我的路径是:
C:
\
Users
\
AppData
\
Local
\
Programs
\
Python
\
Python37
\
Scripts
2、按Win+R,输入CMD确定
3、进入后,先输入cd 路径 回车
4、输入 pip3 install pypdf2 回车
5、输入 pip3 install pdfplumber 回车
6、输入pip3 install pymupdf 回车
安装
2020
年
6
月
11
日
10:03
分区 PDF 的第 1 页
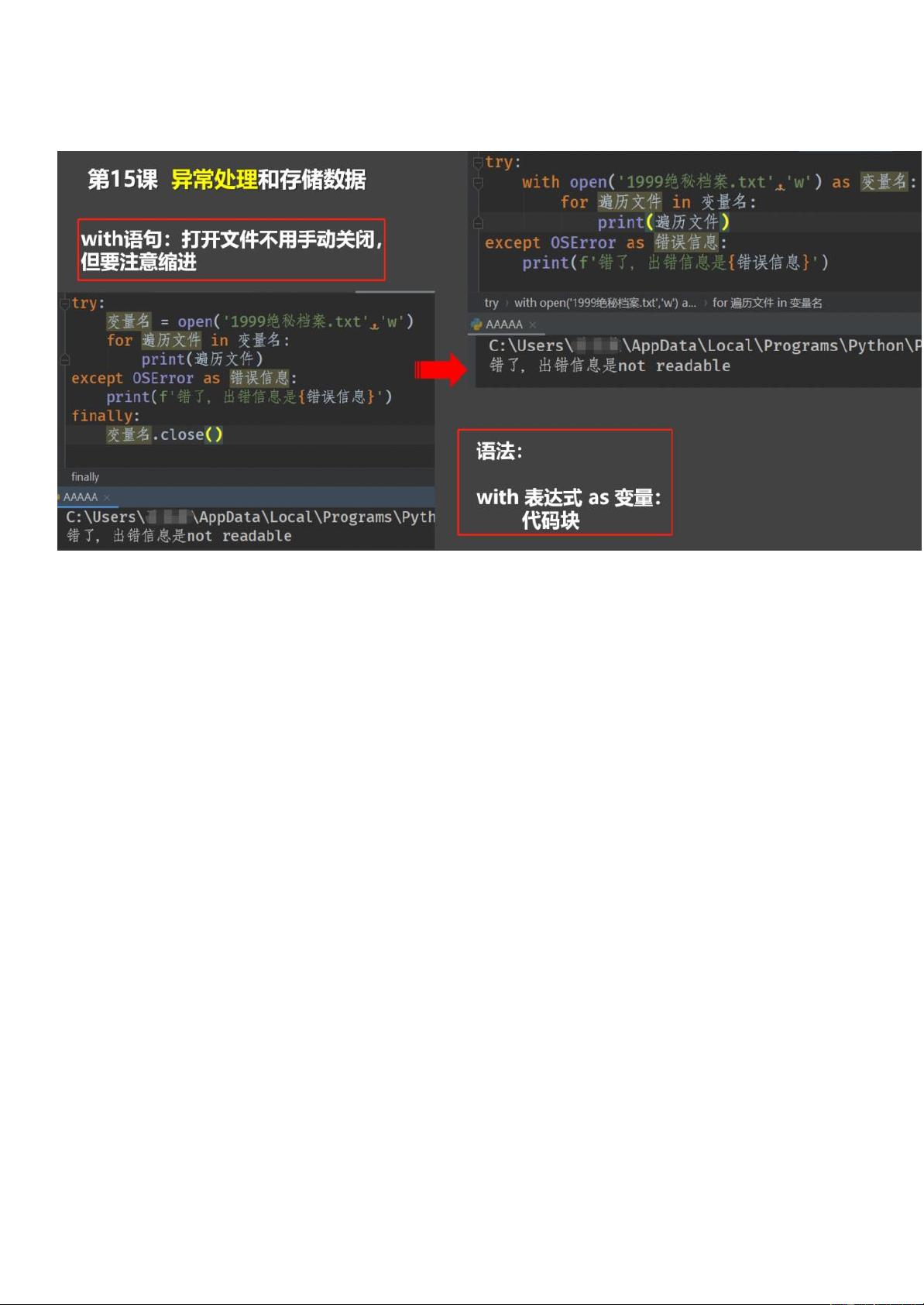
Python基础课程PPT笔记184页 with语句
前景回顾:
with
语句
2020
年
6
月
15
日
20:08
分区
PDF
的第
2
页

pdfminer3k:主要用于读取 pdf 中的文本,代码太复杂
1.
pdfminer 是pdfminer3k在Python2x时代的版本,对于表格的处理非常的不友好,能提取出文字,但是没有格式
2.
tabula-py 是专门用来提取PDF表格数据的,同时支持PDF导出为CSV、Excel格式,但是这工具是用 java 写的,依赖 java7/8。tabula-py 就是对它做了一
层 python 的封装,所以也依赖 java7/8。
3.
pypdf2 网上代码比较多,但是读出来有时是乱码
4.
pdfplumber 是按页来处理 pdf 的,可以获得页面的所有文字,并且提供的单独的方法用于提取表格,对于合并单元格等提取也存在问题。相比前面4个稍好一
点。
5.
解析PDF文本及表格的几种库:
2020年6月15日
21:08
分区 PDF 的第 3 页

一、对其中一页提取
import pdfplumber
路径 = r'c:/文字.pdf'
首页 = pdf.pages[0] # 指定页码
文本 = 页码.extract_text() # 提取文本
文件 = open('c:/1.txt', mode='a') # 新建文件,追加形式写入
文件.write(文本) # 将文本写入到文件
with pdfplumber.open(路径) as pdf:
二、对所有页面提取
import pdfplumber
路径 = r'c:/文字.pdf'
with pdfplumber.open(路径) as pdf:
for 页码 in pdf.pages:
文本 = 页码.extract_text()
文件 = open('c:/1.txt', mode='a')
文件.write(文本)
01.从PDF中提取文本
2020年6月15日
20:18
分区
PDF
的第
4
页

一、保存成Csv文件
import pdfplumber
import pandas as pd
文件 = r'c:/表1.pdf'
with pdfplumber.open(文件) as pdf:
for 页码 in pdf.pages:
for 表格 in 页码.extract_tables():
数据 = pd.DataFrame(表格[1:],columns=表格[0])
数据.to_csv('c:/1.csv',mode='a',encoding='ANSI')
二、保存成Excel文件
import pdfplumber
import pandas as pd
a = r'c:/表1.pdf' # 混合.pdf
count = 1
with pdfplumber.open(a) as pdf:
with pd.ExcelWriter('c:/1.xlsx') as writer:
for 页码 in pdf.pages:
for 表格 in 页码.extract_tables():
数据 = pd.DataFrame(表格[1:],columns=表格[0])
数据.to_excel(writer,sheet_name=f'sheet{count}')
count += 1
02.从PDF中提取表格
2020
年
6
月
15
日
20:55
分区
PDF
的第
5
页













