





二、索引介绍
1、索引是什么
官方介绍索引是帮助MySQL高效获取数据的数据结构。更通俗的说,数据库索引好比是一本书前
面的目录,能加快数据库的查询速度。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往是存储在磁盘上的文件中的
(可能存储在单独的索引文件中,也可能和数据一起存储在数据文件中)。
我们通常所说的索引,包括聚集索引、覆盖索引、组合索引、前缀索引、唯一索引等,没有特别说
明,默认都是使用B+树结构组织(多路搜索树,并不一定是二叉的)的索引。
2、索引的优势和劣势
优势:
可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。
通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
被索引的列会自动进行排序,包括【单列索引】和【组合索引】,只是组合索引的排序要复
杂一些。
如果按照索引列的顺序进行排序,对应order by语句来说,效率就会提高很多。
劣势:
索引会占据磁盘空间
索引虽然会提高查询效率,但是会降低更新表的效率。比如每次对表进行增删改操作,MySQL不
仅要保存数据,还有保存或者更新对应的索引文件。
三、索引的使用
1、索引的类型
主键索引:索引列中的值必须是唯一的,不允许有空值。
普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值。
唯一索引:索引列中的值必须是唯一的,但是允许为空值。
全文索引:只能在文本类型CHAR,VARCHAR,TEXT类型字段上创建全文索引。字段长度比较大时,
如果创建普通索引,在进行like模糊查询时效率比较低,这时可以创建全文索引。
MyISAM和InnoDB中都可以使用全文索引。
InnoDB全文索引,官网介绍:https://dev.mysql.com/doc/refman/5.7/en/innodb-fulltext-ind
ex.html
全文搜索时候,全文索引一般很少使用,数据量比较少或者并发度低的时候可以用。但是数据
量大或者并发度高的时候一般是用专业的工具lucene,es,solr。
ALTER TABLE table_name ADD PRIMARY KEY (column_name);
ALTER TABLE table_name ADD INDEX index_name (column_name) ;
CREATE UNIQUE INDEX index_name ON table(column_name) ;
可以使用MATCH() ... AGAINST语法执行全文搜索。
空间索引:MySQL在5.7之后的版本支持了空间索引,而且支持OpenGIS几何数据模型。MySQL
在空间索引这方面遵循OpenGIS几何数据模型规则。(本课程中不做过多介绍)
参考资料:
MySQL中 OpenGIS Geometry Model
空间数据类型
前缀索引
在文本类型如CHAR,VARCHAR,TEXT类列上创建索引时,可以指定索引列的长度,但是数值类型不
能指定。
按照索引列的数量
单列索引:索引中只有一个列。
组合索引:使用2个以上的字段创建的索引。
组合索引的使用,需要遵循最左前缀原则(最左匹配原则,后面详细讲解)。
一般情况下,建议使用组合索引代替单列索引(主键索引除外,具体原因后面知识点讲解)。
2、删除索引
3、查看索引
四、索引的数据结构
1、索引的要求
#创建表时,创建全文索引
CREATE TABLE `t_fulltext` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`content` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
FULLTEXT KEY `idx_content` (`content`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
#创建全文索引
ALTER TABLE `t_fulltext` ADD FULLTEXT INDEX `idx_content`(`content`);
SELECT * FROM t_fulltext WHERE MATCH(content) AGAINST('开课吧');
ALTER TABLE table_name ADD INDEX index_name (column1(length));
ALTER TABLE table_name ADD INDEX index_name (column1,column2);
DROP INDEX index_name ON table
SHOW INDEX FROM table_name \G
索引的数据结构,至少需要支持两种最常用的查询需求:
1. 等值查询:根据某个值查找数据,比如:
2. 范围查询:根据某个范围区间查找数据,比如:
同时需要考虑时间和空间因素。在执行时间方面,我们希望通过索引,查询数据的时间尽可能小;
在存储空间方面,我们希望索引不要消耗太多的内存空间和磁盘空间。
2、数据结构的选用
常用的数据结构:Hash表,二叉树,平衡二叉查找树(红黑树是一个近似平衡二叉树),B树,B+树。
数据结构示例网站:可以通过动画看到操作过程,非常好的一个网站。
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
1)Hash表
Hash表,Java中的HashMap,TreeMap就是Hash表结构,以键值对的方式存储数据。我们使用Hash
表存储表数据Key可以存储索引列,Value可以存储行记录或者行磁盘地址。Hash表在等值查询时效率
很高,时间复杂度为O(1);但是不支持范围快速查找,范围查找时还是只能通过扫描全表方式。
2)二叉树
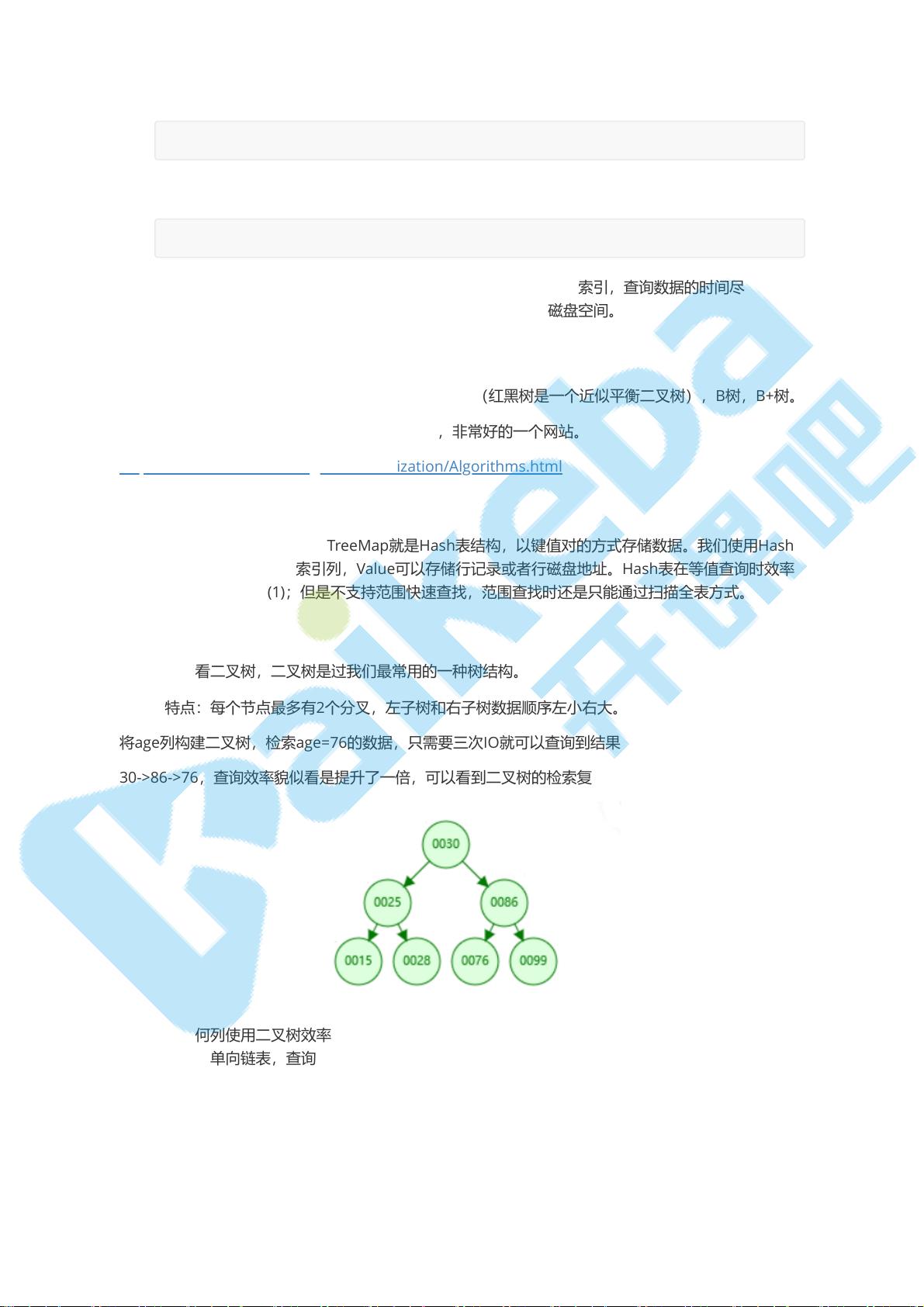
我们在来看看二叉树,二叉树是过我们最常用的一种树结构。
二叉树特点:每个节点最多有2个分叉,左子树和右子树数据顺序左小右大。
将age列构建二叉树,检索age=76的数据,只需要三次IO就可以查询到结果:
30->86->76,查询效率貌似看是提升了一倍,可以看到二叉树的检索复杂度和树高相关。
那是不是任何列使用二叉树效率都会提升呢?答案是否定的。比如,将id列构建二叉树,可以看到二叉
树退化为一个单向链表,查询id=6的数据,需要全表扫描。
select * from t_user where age=76;
select * from t_user where age>=76 and age<=86;

3)平衡二叉查找树
平衡二叉树是采用二分法思维,平衡二叉查找树除了具备二叉树的特点,最主要的特征是树的左右两个
子树的层级最多相差1。在插入删除数据时通过左旋/右旋操作保持二叉树的平衡,不会出现左子树很
高、右子树很矮的情况。
使用平衡二叉查找树查询的性能接近于二分查找法,时间复杂度是 O(log2n)。查询id=6,只需要两次
IO。
平衡二叉树存在的问题
1. 时间复杂度和树高相关。树有多高就需要检索多少次,每个节点的读取,都对应一次磁盘 IO 操
作。树的高度就等于每次查询数据时磁盘 IO 操作的次数。磁盘每次寻道时间为10ms,在表数据
量大时,查询性能就会很差。(1百万的数据量,log2n约等于20次磁盘IO,时间20*10=0.2s)
2. 平衡二叉树不支持范围查询快速查找,范围查询时需要从根节点多次遍历,查询效率不高。
4)B树:改造二叉树
MySQL的数据是存储在磁盘文件中的,查询处理数据时,需要先把磁盘中的数据加载到内存中,磁盘
IO 操作非常耗时,所以我们优化的重点就是尽量减少磁盘 IO 操作。访问二叉树的每个节点就会发生一
次IO,如果想要减少磁盘IO操作,就需要尽量降低树的高度。那如何降低树的高度呢?
假如key为bigint=8字节,每个节点有两个指针,每个指针为4个字节,一个节点占用的空间16个字节
(8+4*2=16)。
我们知道,MySQL的InnoDB存储引擎一次IO会读取的一页16K的数据量,而二叉树一次IO有效数据量
只有16字节,空间利用率极低。













