
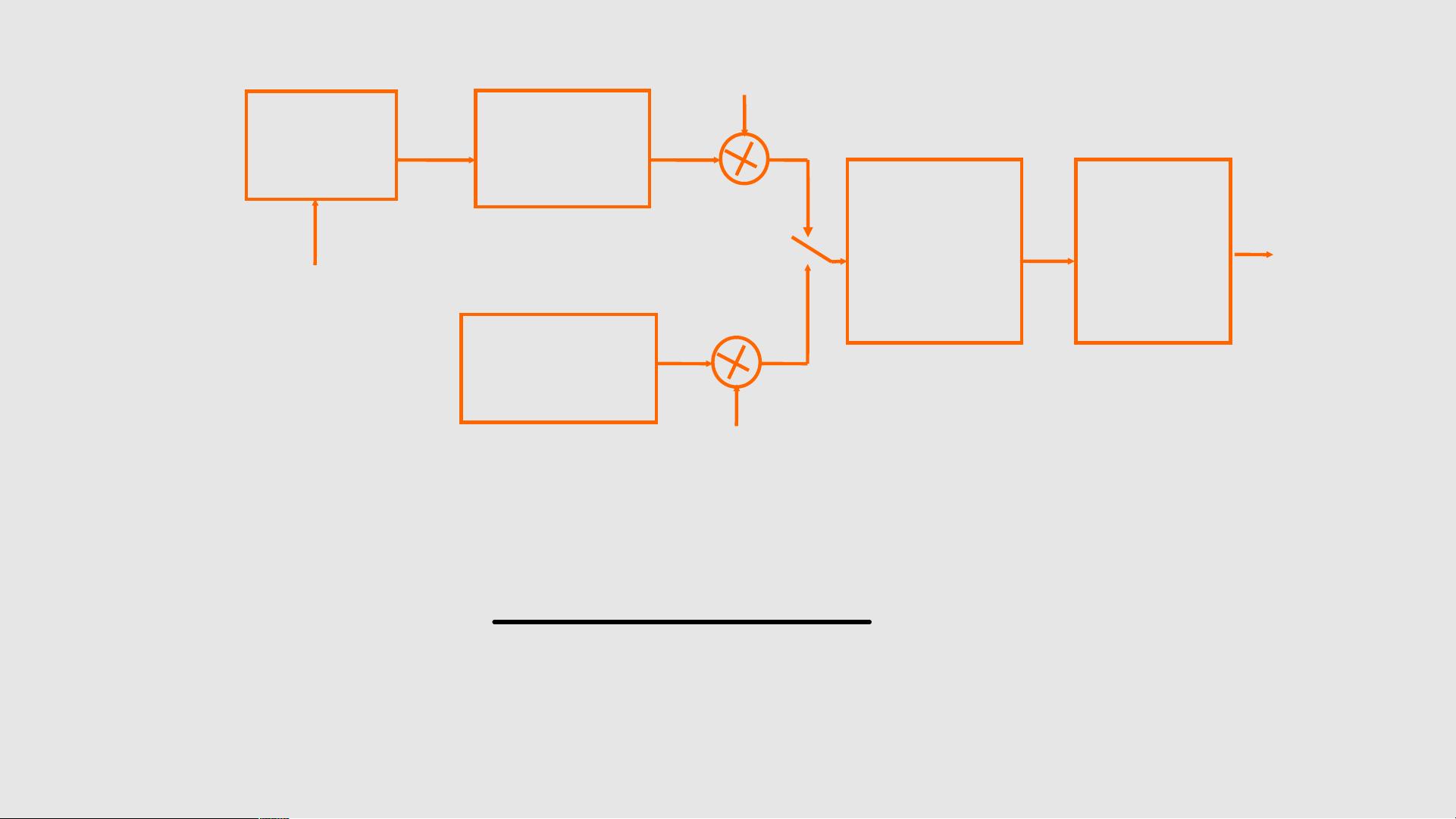
传输函数
A
v
冲激序列
发生器
声门脉冲
模型 G(z)
随机噪声
发生器
基音周期 T
P
A
N
线性系统
声道 V(z)
辐射模型
R(z)
清 / 浊音
开关
第 1 页 / 共 80 页
1
( ) ( ) ( ) ( )
1
q
k
k
k
H z G z V z R z
G
d z

剩余63页未读,继续阅读
资源评论


加油学习加油进步
- 粉丝: 1407
- 资源: 52万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 英语四级考试综合训练与听力阅读翻译解析
- 三相异步电机转子磁场定向矢量控制技术及其与弱磁控制的协同优化策略,三相异步电机转子磁场定向矢量控制与弱磁控制策略探究,三相异步电机转子磁场定向矢量控制与弱磁控制 ,三相异步电机; 转子磁场定向矢量控制
- 【java毕业设计】SpringBoot+Vue自习室预约管理系统(高级版) 源码+sql脚本+论文 完整版
- 字节面试题,包括一面和二面,vue和react
- 技术博客基于MATLAB Simulink的移相变压器仿真模型,模拟实现可调移相角度的变压器副边36脉波不控整流,MATLAB Simulink仿真模型实现可设置移相角度的变压器副边36脉波不控整
- 利用Bigemap Pro缓冲区工具实现地图发光效果
- 2025 Data+AI:智能数据架构与应用最佳实践合集.pdf
- Vue生命周期详解:从初始化到销毁的关键环节与应用
- 2018 蓝桥杯C语言b组国赛真题
- 软件测试实验三1111111111111111
- 直接复制,然后粘贴到assert下面
- 基于Springboot敬老院管理系统源码+22张表+100%可以运行使用+三端19个菜单/业务功能+vue前后分离使用Maven、Spingboot等技术
- PEM电解槽仿真模型分析,基于Comsol仿真的质子交换膜电解槽多物理场耦合模型:传热、多孔介质流动与极化性能分析,质子交膜(PEM)电解槽comsol仿真模型,耦合电解槽,传热,多孔介质流动物理场
- 欧姆龙CP1H与三菱E700变频器通讯程序:实现三台变频器频率设定与读取,稳定可靠扩展功能强大,欧姆龙CP1H与三菱E700变频器通讯程序:实现三台变频器频率设定与读取,稳定可靠扩展应用,欧姆龙CP1
- COMSOL仿真研究:斜入射圆偏振高斯光与金纳米线在衬底上的相互作用-模型构建与应用,Comsol模拟研究斜入射圆偏振高斯光在金纳米线与衬底结构上的作用:应用其模型解析交互机制 ,comsol仿真斜
- 高等数学教育中几何画板课件制作的实例指导与微课教程
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


