

8.6
二叉树遍历
8.6.1 遍历二叉树的定义
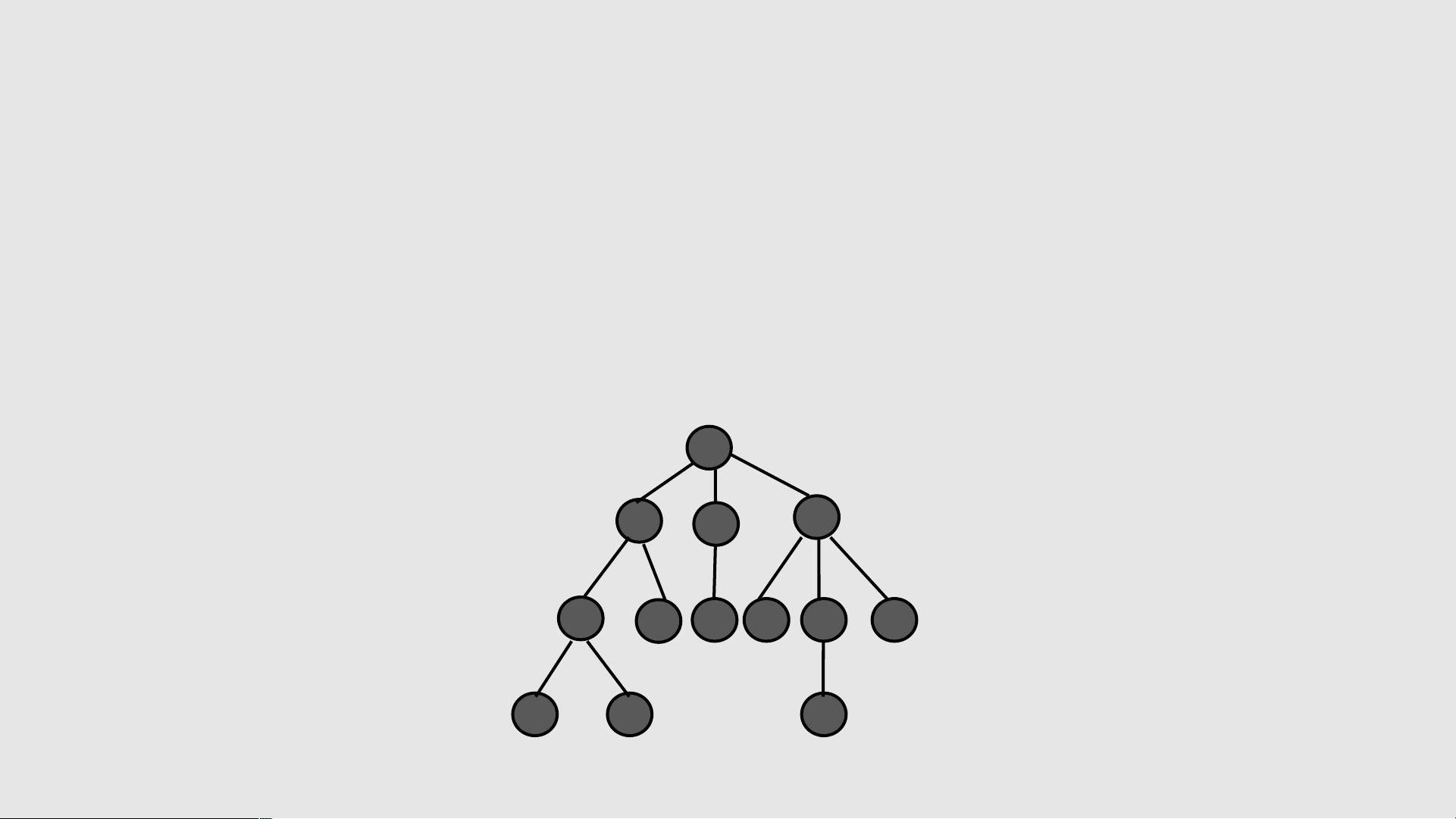
二叉树遍历是指按照某种顺序访问二叉树中的每个节
点,使每个节点被访问一次,且只被访问一次。
“ 访问”的含义:是指对节点施行某种操作,操作可以是
输出节点信息,修改节点的数据值等,但要求这种访问
不破坏它原来的数据结构。
以二叉链表作为二叉树的存储结构。
第 1 页 / 共 61 页

剩余60页未读,继续阅读
资源评论


加油学习加油进步
- 粉丝: 1405
- 资源: 52万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 减速器含设计文档二级直齿轮减速器设计
- 基于遗传算法的LQR控制器优化设计sumlink仿真模型 可用于学习了解LQR控制器,将其应用于其他模型
- 减速器含设计文档二级直齿圆柱齿轮减速器课程设计
- 目标检测手枪步枪数据集16292张YOLO+VOC格式.zip
- java和jsp写的酒店管理系统
- 燃料电池PEMFC非等温两相流模型,考虑流道液态水膜态水
- 文本格式的2025年日历
- 减速器含设计文档复合形法减速器优化设计
- 97个linux常用命令大全.docx
- 8控制TOP1期刊IEEE TAC程序复现-A Delay System Method for Designing Event-Triggered Controllers of Networked C
- 五套随机小姐姐短视频引流网站源码+最新API
- 论文文档KGP-250-10晶闸管中频加热电源
- 燃料电池PEMFC非等温两相流模型,考虑流道液态水膜态水
- 减速器含设计文档钢丝绳电动葫芦起升用减速器设计
- 前盖裁胶摆盘机设备sw16可编辑全套技术资料100%好用.zip
- MFC小游戏七:获胜界面和失败界面
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


